Zero-Shot Translation with Google’s Multilingual Neural Machine Translation System
November 22, 2016
Posted by Mike Schuster (Google Brain Team), Melvin Johnson (Google Translate) and Nikhil Thorat (Google Brain Team)
Quick links
In the last 10 years, Google Translate has grown from supporting just a few languages to 103, translating over 140 billion words every day. To make this possible, we needed to build and maintain many different systems in order to translate between any two languages, incurring significant computational cost. With neural networks reforming many fields, we were convinced we could raise the translation quality further, but doing so would mean rethinking the technology behind Google Translate.
In September, we announced that Google Translate is switching to a new system called Google Neural Machine Translation (GNMT), an end-to-end learning framework that learns from millions of examples, and provided significant improvements in translation quality. However, while switching to GNMT improved the quality for the languages we tested it on, scaling up to all the 103 supported languages presented a significant challenge.
In “Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”, we address this challenge by extending our previous GNMT system, allowing for a single system to translate between multiple languages. Our proposed architecture requires no change in the base GNMT system, but instead uses an additional “token” at the beginning of the input sentence to specify the required target language to translate to. In addition to improving translation quality, our method also enables “Zero-Shot Translation” — translation between language pairs never seen explicitly by the system.

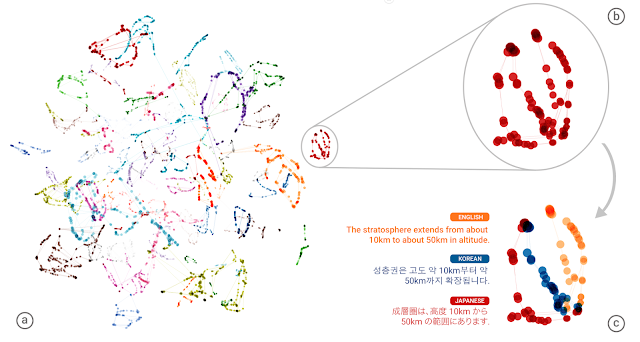
This inspired us to ask the following question: Can we translate between a language pair which the system has never seen before? An example of this would be translations between Korean and Japanese where Korean⇄Japanese examples were not shown to the system. Impressively, the answer is yes — it can generate reasonable Korean⇄Japanese translations, even though it has never been taught to do so. We call this “zero-shot” translation, shown by the yellow dotted lines in the animation. To the best of our knowledge, this is the first time this type of transfer learning has worked in Machine Translation.
The success of the zero-shot translation raises another important question: Is the system learning a common representation in which sentences with the same meaning are represented in similar ways regardless of language — i.e. an “interlingua”? Using a 3-dimensional representation of internal network data, we were able to take a peek into the system as it translates a set of sentences between all possible pairs of the Japanese, Korean, and English languages.

We show many more results and analyses in our paper, and hope that its findings are not only interesting for machine learning or machine translation researchers but also to linguists and others who are interested in how multiple languages can be processed by machines using a single system.
Finally, the described Multilingual Google Neural Machine Translation system is running in production today for all Google Translate users. Multilingual systems are currently used to serve 10 of the recently launched 16 language pairs, resulting in improved quality and a simplified production architecture.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯