Zero-shot adaptive prompting of large language models
November 2, 2023
Posted by Xingchen Wan, Student Researcher, and Ruoxi Sun, Research Scientist, Cloud AI Team
Quick links
Recent advances in large language models (LLMs) are very promising as reflected in their capability for general problem-solving in few-shot and zero-shot setups, even without explicit training on these tasks. This is impressive because in the few-shot setup, LLMs are presented with only a few question-answer demonstrations prior to being given a test question. Even more challenging is the zero-shot setup, where the LLM is directly prompted with the test question only.
Even though the few-shot setup has dramatically reduced the amount of data required to adapt a model for a specific use-case, there are still cases where generating sample prompts can be challenging. For example, handcrafting even a small number of demos for the broad range of tasks covered by general-purpose models can be difficult or, for unseen tasks, impossible. For example, for tasks like summarization of long articles or those that require domain knowledge (e.g., medical question answering), it can be challenging to generate sample answers. In such situations, models with high zero-shot performance are useful since no manual prompt generation is required. However, zero-shot performance is typically weaker as the LLM is not presented with guidance and thus is prone to spurious output.
In “Better Zero-shot Reasoning with Self-Adaptive Prompting”, published at ACL 2023, we propose Consistency-Based Self-Adaptive Prompting (COSP) to address this dilemma. COSP is a zero-shot automatic prompting method for reasoning problems that carefully selects and constructs pseudo-demonstrations for LLMs using only unlabeled samples (that are typically easy to obtain) and the models’ own predictions. With COSP, we largely close the performance gap between zero-shot and few-shot while retaining the desirable generality of zero-shot prompting. We follow this with “Universal Self-Adaptive Prompting“ (USP), accepted at EMNLP 2023, in which we extend the idea to a wide range of general natural language understanding (NLU) and natural language generation (NLG) tasks and demonstrate its effectiveness.
Prompting LLMs with their own outputs
Knowing that LLMs benefit from demonstrations and have at least some zero-shot abilities, we wondered whether the model’s zero-shot outputs could serve as demonstrations for the model to prompt itself. The challenge is that zero-shot solutions are imperfect, and we risk giving LLMs poor quality demonstrations, which could be worse than no demonstrations at all. Indeed, the figure below shows that adding a correct demonstration to a question can lead to a correct solution of the test question (Demo1 with question), whereas adding an incorrect demonstration (Demo 2 + questions, Demo 3 with questions) leads to incorrect answers. Therefore, we need to select reliable self-generated demonstrations.
 |
| Example inputs & outputs for reasoning tasks, which illustrates the need for carefully designed selection procedure for in-context demonstrations (MultiArith dataset & PaLM-62B model): (1) zero-shot chain-of-thought with no demo: correct logic but wrong answer; (2) correct demo (Demo1) and correct answer; (3) correct but repetitive demo (Demo2) leads to repetitive outputs; (4) erroneous demo (Demo3) leads to a wrong answer; but (5) combining Demo3 and Demo1 again leads to a correct answer. |
COSP leverages a key observation of LLMs: that confident and consistent predictions are more likely correct. This observation, of course, depends on how good the uncertainty estimate of the LLM is. Luckily, in large models, previous works suggest that the uncertainty estimates are robust. Since measuring confidence requires only model predictions, not labels, we propose to use this as a zero-shot proxy of correctness. The high-confidence outputs and their inputs are then used as pseudo-demonstrations.
With this as our starting premise, we estimate the model’s confidence in its output based on its self-consistency and use this measure to select robust self-generated demonstrations. We ask LLMs the same question multiple times with zero-shot chain-of-thought (CoT) prompting. To guide the model to generate a range of possible rationales and final answers, we include randomness controlled by a “temperature” hyperparameter. In an extreme case, if the model is 100% certain, it should output identical final answers each time. We then compute the entropy of the answers to gauge the uncertainty — the answers that have high self-consistency and for which the LLM is more certain, are likely to be correct and will be selected.
Assuming that we are presented with a collection of unlabeled questions, the COSP method is:
- Input each unlabeled question into an LLM, obtaining multiple rationales and answers by sampling the model multiple times. The most frequent answers are highlighted, followed by a score that measures consistency of answers across multiple sampled outputs (higher is better). In addition to favoring more consistent answers, we also penalize repetition within a response (i.e., with repeated words or phrases) and encourage diversity of selected demonstrations. We encode the preference towards consistent, un-repetitive and diverse outputs in the form of a scoring function that consists of a weighted sum of the three scores for selection of the self-generated pseudo-demonstrations.
- We concatenate the pseudo-demonstrations into test questions, feed them to the LLM, and obtain a final predicted answer.
 |
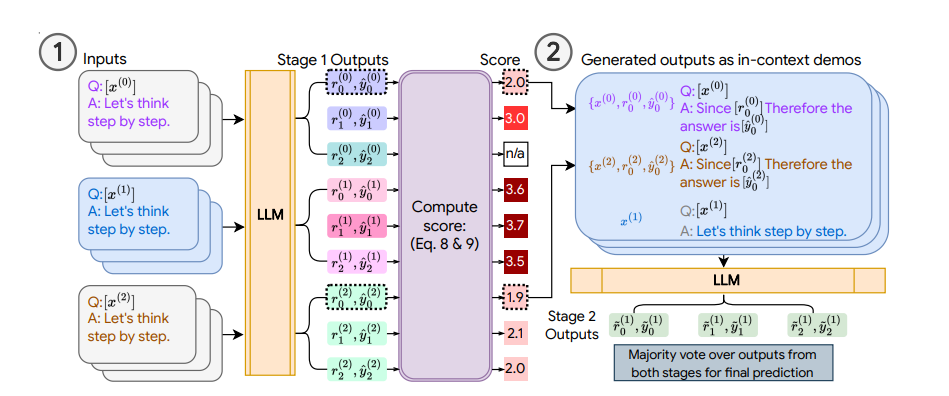
| Illustration of COSP: In Stage 1 (left), we run zero-shot CoT multiple times to generate a pool of demonstrations (each consisting of the question, generated rationale and prediction) and assign a score. In Stage 2 (right), we augment the current test question with pseudo-demos (blue boxes) and query the LLM again. A majority vote over outputs from both stages forms the final prediction. |
COSP focuses on question-answering tasks with CoT prompting for which it is easy to measure self-consistency since the questions have unique correct answers. But this can be difficult for other tasks, such as open-ended question-answering or generative tasks that don’t have unique answers (e.g., text summarization). To address this limitation, we introduce USP in which we generalize our approach to other general NLP tasks:
- Classification (CLS): Problems where we can compute the probability of each class using the neural network output logits of each class. In this way, we can measure the uncertainty without multiple sampling by computing the entropy of the logit distribution.
- Short-form generation (SFG): Problems like question answering where we can use the same procedure mentioned above for COSP, but, if necessary, without the rationale-generating step.
- Long-form generation (LFG): Problems like summarization and translation, where the questions are often open-ended and the outputs are unlikely to be identical, even if the LLM is certain. In this case, we use an overlap metric in which we compute the average of the pairwise ROUGE score between the different outputs to the same query.
 |
| Illustration of USP in exemplary tasks (classification, QA and text summarization). Similar to COSP, the LLM first generates predictions on an unlabeled dataset whose outputs are scored with logit entropy, consistency or alignment, depending on the task type, and pseudo-demonstrations are selected from these input-output pairs. In Stage 2, the test instances are augmented with pseudo-demos for prediction. |
We compute the relevant confidence scores depending on the type of task on the aforementioned set of unlabeled test samples. After scoring, similar to COSP, we pick the confident, diverse and less repetitive answers to form a model-generated pseudo-demonstration set. We finally query the LLM again in a few-shot format with these pseudo-demonstrations to obtain the final predictions on the entire test set.
Key Results
For COSP, we focus on a set of six arithmetic and commonsense reasoning problems, and we compare against 0-shot-CoT (i.e., “Let’s think step by step“ only). We use self-consistency in all baselines so that they use roughly the same amount of computational resources as COSP. Compared across three LLMs, we see that zero-shot COSP significantly outperforms the standard zero-shot baseline.
 |
| Key results of COSP in six arithmetic (MultiArith, GSM-8K, AddSub, SingleEq) and commonsense (CommonsenseQA, StrategyQA) reasoning tasks using PaLM-62B, PaLM-540B and GPT-3 (code-davinci-001) models. |
 |
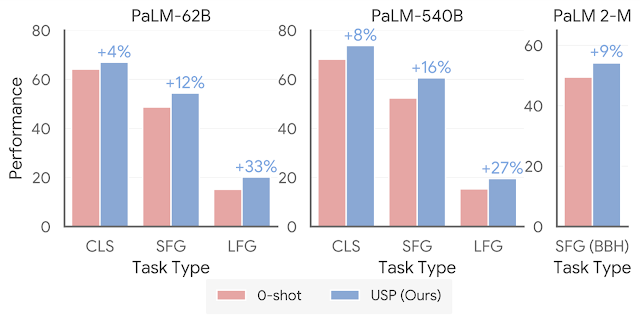
| USP improves significantly on 0-shot performance. “CLS” is an average of 15 classification tasks; “SFG” is the average of five short-form generation tasks; “LFG” is the average of two summarization tasks. “SFG (BBH)” is an average of all BIG-Bench Hard tasks, where each question is in SFG format. |
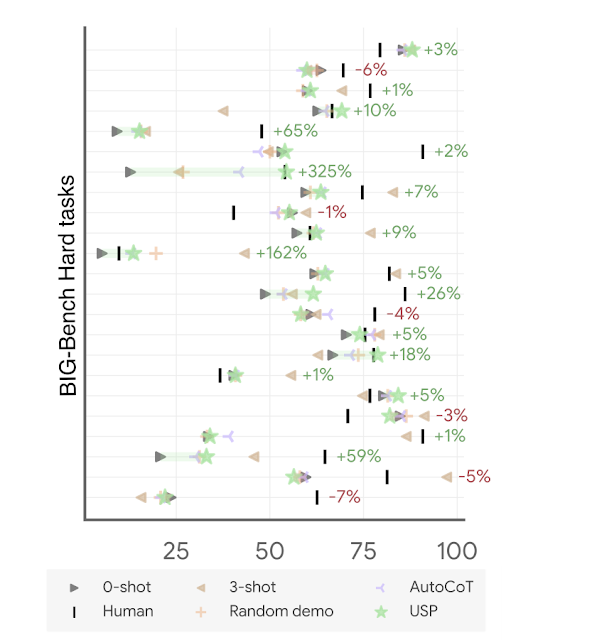
For USP, we expand our analysis to a much wider range of tasks, including more than 25 classifications, short-form generation, and long-form generation tasks. Using the state-of-the-art PaLM 2 models, we also test against the BIG-Bench Hard suite of tasks where LLMs have previously underperformed compared to people. We show that in all cases, USP again outperforms the baselines and is competitive to prompting with golden examples.
 |
| Accuracy on BIG-Bench Hard tasks with PaLM 2-M (each line represents a task of the suite). The gain/loss of USP (green stars) over standard 0-shot (green triangles) is shown in percentages. “Human” refers to average human performance; “AutoCoT” and “Random demo” are baselines we compared against in the paper; and “3-shot” is the few-shot performance for three handcrafted demos in CoT format. |
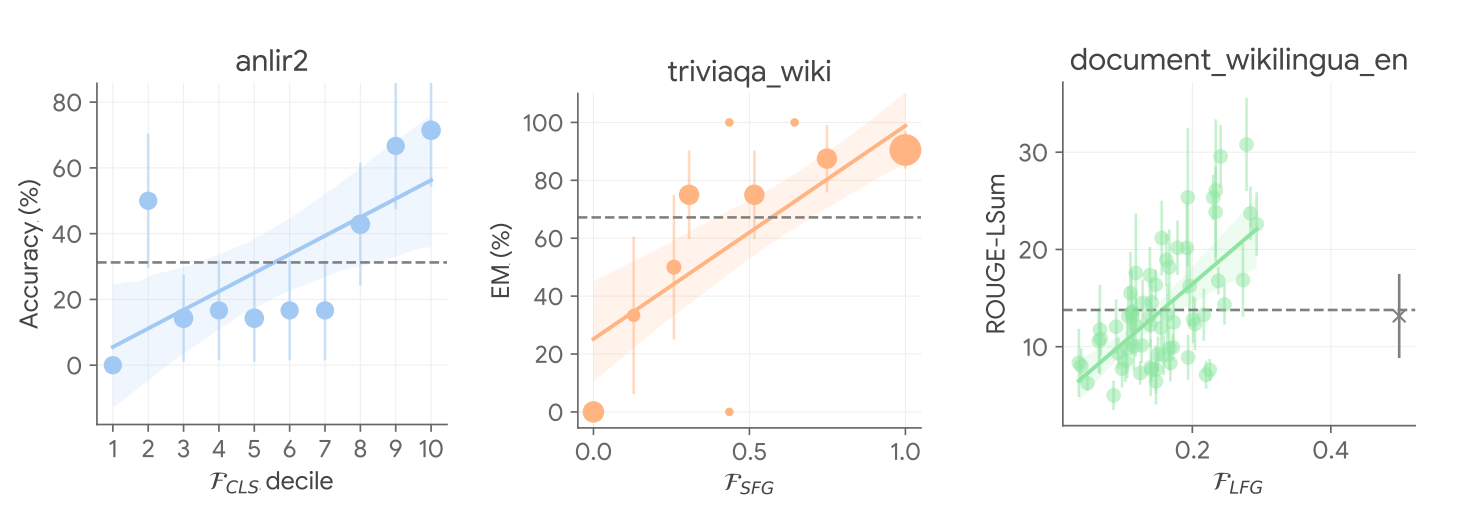
We also analyze the working mechanism of USP by validating the key observation above on the relation between confidence and correctness, and we found that in an overwhelming majority of the cases, USP picks confident predictions that are more likely better in all task types considered, as shown in the figure below.
 |
| USP picks confident predictions that are more likely better. Ground-truth performance metrics against USP confidence scores in selected tasks in various task types (blue: CLS, orange: SFG, green: LFG) with PaLM-540B. |
Conclusion
Zero-shot inference is a highly sought-after capability of modern LLMs, yet the success in which poses unique challenges. We propose COSP and USP, a family of versatile, zero-shot automatic prompting techniques applicable to a wide range of tasks. We show large improvement over the state-of-the-art baselines over numerous task and model combinations.
Acknowledgements
This work was conducted by Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan Ö. Arık, and Tomas Pfister. We would like to thank Jinsung Yoon Xuezhi Wang for providing helpful reviews, and other colleagues at Google Cloud AI Research for their discussion and feedback.
Quick links
Other posts of interest
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence