WAXAL: A large-scale open resource for African language speech technology
March 6, 2026
Tavonga Siyavora, Senior Product Manager, and Abdoulaye Diack, Program Manager, Google Research
WAXAL provides a critical, open-access foundation for African speech technology. Featuring a large corpus of ASR and TTS data for 27 native languages under a highly permissive license, WAXAL empowers the African AI ecosystem to build robust speech systems that better reflect the region's unique linguistic diversity.
Quick links
Voice-enabled technologies like virtual assistants and automated transcription have transformed how we interact with computers. However, their benefits disproportionately favor a handful of high-resource languages. This divide has left hundreds of millions of people — particularly in Sub-Saharan Africa, home to over 2,000 distinct languages — unable to access essential technology in their native tongues. Several years ago, the team at Google Research set out to help tackle this problem.
To address this critical need, we introduce WAXAL: a large-scale, openly accessible speech dataset that initially covers 27 Sub-Saharan African languages spoken by over 100 million speakers across more than 26 countries. Developed through a multi-year effort beginning in 2021, in collaboration with African academic and community organizations, WAXAL provides the high-quality, permissively licensed data necessary to build robust speech systems. Setting a foundational milestone, this initial release features approximately 1,846 hours of transcribed natural speech for automatic speech recognition (ASR) and over 565 hours of high-fidelity recordings for text-to-speech (TTS). We are releasing these resources under a Creative Commons license (CC-BY-4.0) to catalyze research and enable inclusive voice-enabled technologies tailored to the unique linguistic characteristics of the continent. We intend for the WAXAL collection to continuously evolve and expand to include additional languages as part of our ongoing effort to bridge the digital divide.
Introducing WAXAL
By addressing critical data scarcity for over 100 million speakers, WAXAL aims to empower the regional AI research ecosystem. To support the development of robust speech technologies, the corpus integrates two specialized datasets designed to provide comprehensive coverage for both speech recognition and synthesis tasks.
- WAXAL-ASR (Spontaneous Understanding): Comprising approximately 1,846 hours of transcribed audio, this dataset captures natural, unscripted speech. Instead of reading scripts, diverse participants were asked to describe visual stimuli covering 50+ topics in their native language. This image-prompted elicitation captured authentic linguistic variations, including tonal nuances and code-switching. This method successfully yielded more natural speech than traditional methods.

Examples from Google’s Open Images used as prompts to elicit natural speech for the ASR dataset.
- WAXAL-TTS (High-Fidelity Generation): Designed to facilitate the creation of natural-sounding synthetic voices, this dataset contains over 565 hours of high-quality, phonetically balanced audio. The TTS collection process was highly collaborative: local community members worked in pairs to draft scripts of 10,000–20,000 words, alternating reader and recorder roles. To ensure professional-grade acoustics, some participants used project funding to build custom studio boxes. The resulting recordings were then segmented, matched with the script text, and reviewed for accuracy and quality.

TTS recording box at University of Ghana.
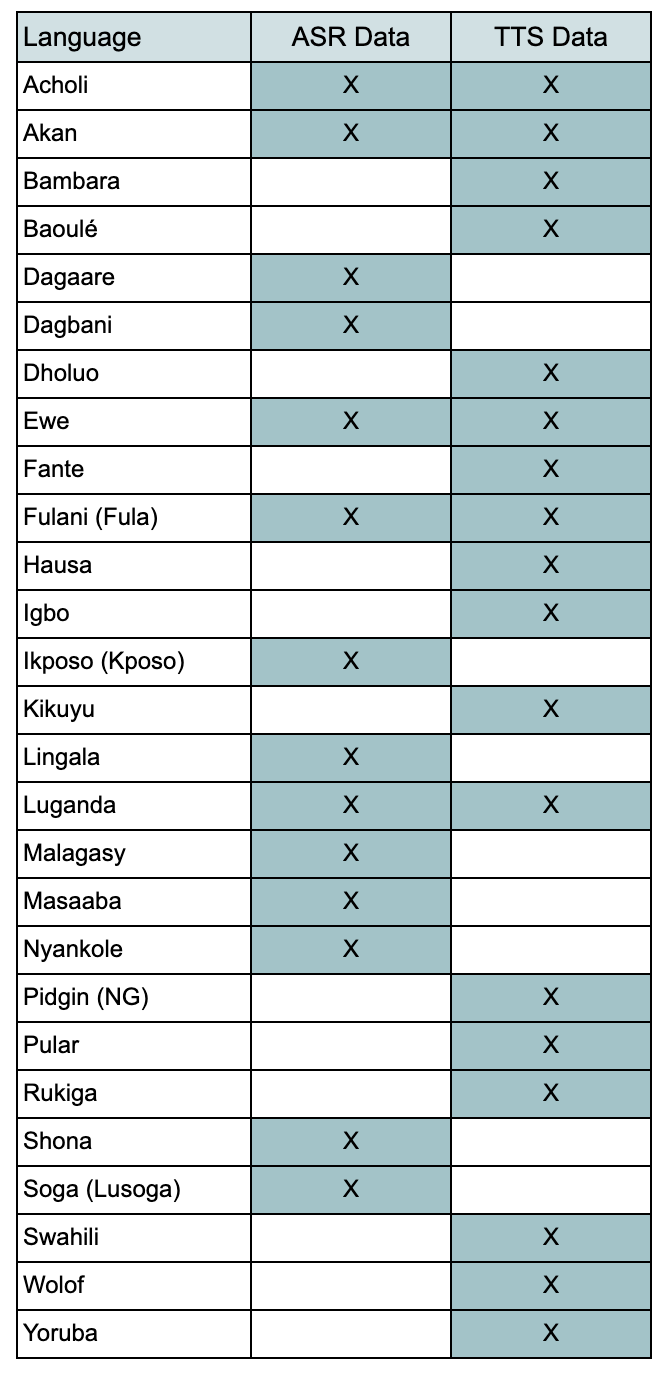
The WAXAL corpus's dual focus on unscripted ASR data and high-fidelity TTS audio is designed to enable the development of full-duplex conversational systems. Specifically, the ASR component facilitates the modeling of varied, spontaneous speech input typical of real-world scenarios, while the high-quality TTS component provides the clean reference data required for generating clear, natural output. The table below lists the 27 languages currently included in the dataset:
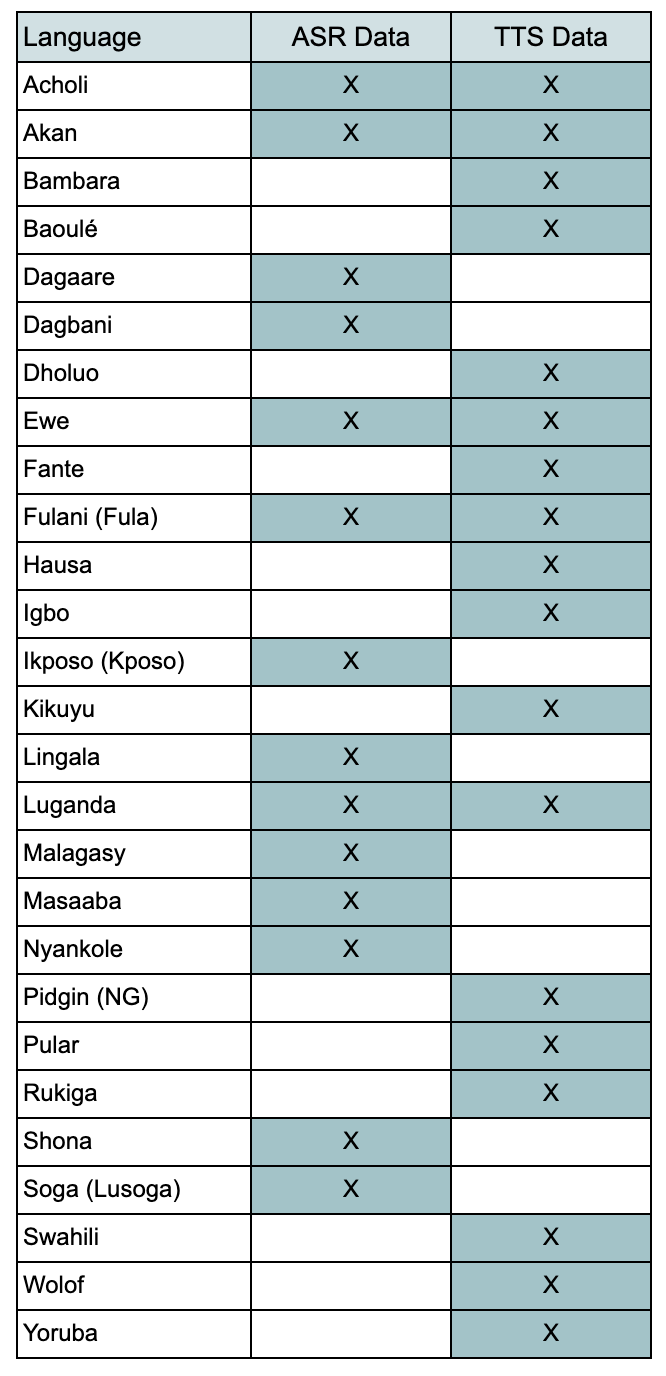
Breakdown of the current WAXAL dataset, showing the 27 initial Sub-Saharan African languages and the availability of ASR and TTS data for each.
Anchoring in the African AI ecosystem
Crucial to the WAXAL project was our commitment to working with, and contributing directly to, the African AI ecosystem. The data collection effort was led entirely by African academic and community organizations, guided by Google experts on world-class data collection practices. This collaborative approach ensured the corpus was built by and for the community it serves; with shared methodology each partner focused on a specific subset of languages. Our partners included Makerere University, which collected ASR and/or TTS data for nine different languages, and the University of Ghana, which focused its efforts on eight languages, using the ASR image-prompted data collection methodology outlined above. Additional key collaborators were Digital Umuganda, in partnership with Addis Ababa University, who were instrumental in leading the ASR collection for several regional languages. For the high-quality, studio-recorded voices, Media Trust, Loud n Clear and African Institute for Mathematical Sciences Senegal spearheaded the TTS recordings across various regional languages.
This framework is fundamentally rooted in the principle that our partners retain ownership of the collected data toward the shared commitment to make all datasets openly available for the broader community. This deep collaboration and open-access philosophy have already enabled notable derivative research and publications.
- Through this framework, our partners have already enabled new research, such as the development of a cookbook for community-driven collection of impaired speech . This research resulted in the first open-source dataset for Akan speakers with conditions like cerebral palsy and stammering, and demonstrated that in-person, image-prompted elicitation is more effective than text-based prompts for these populations. This work provides a vital roadmap for developing inclusive speech technologies in low-resource environments.
- Furthermore, the initiative supported a major study that introduced a 5,000-hour speech corpus for five Ghanaian languages — Akan, Ewe, Dagbani, Dagaare, and Ikposo. This work established infrastructure for building robust ASR and TTS systems tailored to the linguistic diversity of West Africa by using a controlled crowdsourcing approach to capture natural, spontaneous intonations.
- Other essential research has focused on benchmarking four state-of-the-art models (Whisper, XLS-R, MMS, and W2v-BERT) across 13 African languages. This study analyzed how performance scales with increased training data, offering key insights into data efficiency and highlighting that scaling benefits are strongly dependent on linguistic complexity and domain alignment.
- Finally, a systematic literature review was published, cataloging 74 datasets across 111 African languages to map the current frontier of speech technology. This review emphasized the urgent need for multi-domain conversational corpora and the adoption of linguistically informed metrics, such as Character Error Rate (CER), to better evaluate performance in morphologically rich and tonal language contexts.
Conclusion and future directions
WAXAL represents a key milestone in bridging the digital divide, offering a high-quality, open-access speech resource for 27 Sub-Saharan African languages. Developed through deep collaboration with African academic and community organizations, this initiative empowers the continent’s AI ecosystem and preserves linguistic diversity. We hope WAXAL will continue to serve as a vital resource for the digital preservation of African languages and a foundation for future innovations. Google remains committed to this effort, with plans to continuously expand the WAXAL dataset.
Acknowledgements
We are grateful to our partners at Makerere University, the University of Ghana, Digital Umuganda, University of Addis Ababa, the African Institute for Mathematical Sciences Senegal, Media Trust and Loud and Clear Communications Ltd for their essential contributions in reducing the language gap and building a more inclusive digital future for millions of speakers across the African continent.
Quick links
Other posts of interest
-

June 30, 2026
Expanding our Heat Resilience data to 50+ global cities- Climate & Sustainability ·
- Earth AI ·
- Open Source Models & Datasets
-

June 26, 2026
Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction- Machine Intelligence ·
- Mobile Systems ·
- Natural Language Processing
-

June 24, 2026
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing