VDTTS: Visually-Driven Text-To-Speech
April 7, 2022
Posted by Tal Remez, Software Engineer, Google Research and Micheal Hassid, Software Engineer Intern, Google Research
Quick links
Recent years have seen a tremendous increase in the creation and serving of video content to users across the world in a variety of languages and over numerous platforms. The process of creating high quality content can include several stages from video capturing and captioning to video and audio editing. In some cases dialogue is re-recorded (referred to as dialog replacement, post-sync or dubbing) in a studio in order to achieve high quality and replace original audio that might have been recorded in noisy conditions. However, the dialog replacement process can be difficult and tedious because the newly recorded audio needs to be well synced with the video, requiring several edits to match the exact timing of mouth movements.
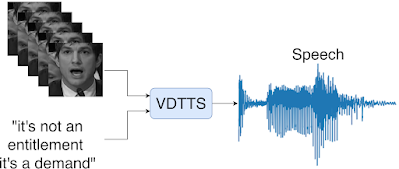
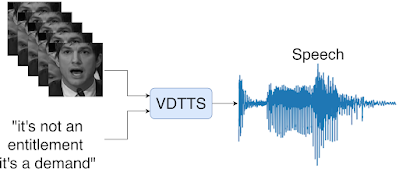
In “More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech”, we present a proof-of-concept visually-driven text-to-speech model, called VDTTS, that automates the dialog replacement process. Given a text and the original video frames of the speaker, VDTTS is trained to generate the corresponding speech. As opposed to standard visual speech recognition models, which focus on the mouth region, we detect and crop full faces using MediaPipe to avoid potentially excluding information pertinent to the speaker’s delivery. This gives the VDTTS model enough information to generate speech that matches the video while also recovering aspects of prosody, such as timing and emotion. Despite not being explicitly trained to generate speech that is synchronized to the input video, the learned model still does so.
 |
| Given a text and video frames of a speaker, VDTTS generates speech with prosody that matches the video signal. |
VDTTS Model
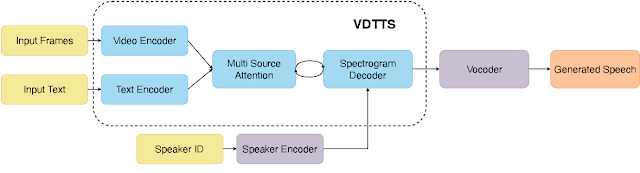
The VDTTS model resembles Tacotron at its core and has four main components: (1) text and video encoders that process the inputs; (2) a multi-source attention mechanism that connects encoders to a decoder; (3) a spectrogram decoder that incorporates the speaker embedding (similarly to VoiceFilter), and produces mel-spectrograms (which are a form of compressed representation in the frequency domain); and (4) a frozen, pretrained neural vocoder that produces waveforms from the mel-spectrograms.
 |
| The overall architecture of VDTTS. Text and video encoders process the inputs and then a multisource attention mechanism connects these to a decoder that produces mel-spectrograms. A vocoder then produces waveforms from the mel-spectrograms to generate speech as an output. |
We train VDTTS using video and text pairs from LSVSR in which the text corresponds to the exact words spoken by a person in a video. Throughout our testing, we have determined that VDTTS cannot generate arbitrary text, thus making it less prevalent for misuse (e.g., the generation of fake content).
Quality
To showcase the unique strength of VDTTS in this post, we have selected two inference examples from the VoxCeleb2 test dataset and compare the performance of VDTTS to a standard text-to-speech (TTS) model. In both examples, the video frames provide prosody and word timing clues, visual information that is not available to the TTS model.
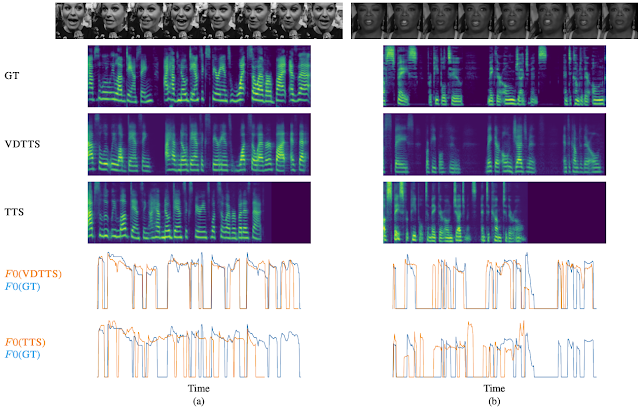
In the first example, the speaker talks at a particular pace that can be seen as periodic gaps in the ground-truth mel-spectrogram (shown below). VDTTS preserves this characteristic and generates audio that is much closer to the ground-truth than the audio generated by standard TTS without access to the video.
Similarly, in the second example, the speaker takes long pauses between some of the words. These pauses are captured by VDTTS and are reflected in the video below, whereas the TTS does not capture this aspect of the speaker’s rhythm.
We also plot fundamental frequency (F0) charts to compare the pitch generated by each model to the ground-truth pitch. In both examples, the F0 curve of VDTTS fits the ground-truth much better than the TTS curve, both in the alignment of speech and silence, and also in how the pitch changes over time. See more original videos and VDTTS generated videos.
 |
| We present two examples, (a) and (b), from the VoxCeleb2 test set. From top to bottom: input face images, ground-truth (GT) mel-spectrogram, mel-spectrogram output of VDTTS, mel-spectrogram output of a standard TTS model, and two plots showing the normalized F0 (normalized by mean non-zero pitch, i.e., mean is only over voiced periods) of VDTTS and TTS compared to the ground-truth signal. |
Video Samples
| Original | VDTTS | VDTTS video-only | TTS |
| Original displays the original video clip. VDTTS, displays the audio predicted using both the video frames and the text as input. VDTTS video-only displays audio predictions using video frames only. TTS displays audio predictions using text only. Top transcript: "of space for people to make their own judgments and to come to their own". Bottom transcript: "absolutely love dancing I have no dance experience whatsoever but as that". |
Model Performance
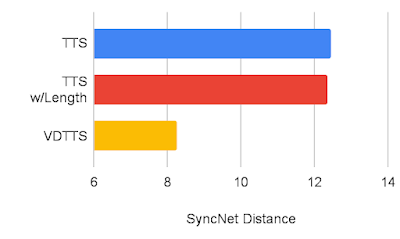
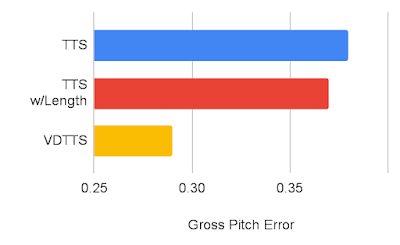
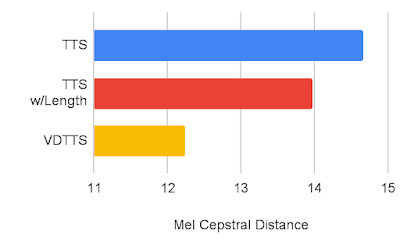
We’ve measured the VDTTS model’s performance using the VoxCeleb2 dataset and compared it to TTS and the TTS with length hint (a TTS that receives the scene length) models. We demonstrate that VDTTS outperforms both models by large margins in most of the aspects we measured: higher sync-to-video quality (measured by SyncNet Distance) and better speech quality as measured by mel cepstral distance (MCD), and lower Gross Pitch Error (GPE), which measures the percentage of frames where pitch differed by more than 20% on frames for which voice was present on both the predicted and reference audio.
 |
| SyncNet distance comparison between VDTTS, TTS and the TTS with Length hint (a lower metric is better). |
 |
| Mel cepstral distance comparison between VDTTS, TTS and the TTS with Length hint (a lower metric is better). |
 |
| Gross Pitch Error comparison between VDTTS, TTS and the TTS with Length hint (a lower metric is better). |
Discussion and Future Work
One thing to note is that, intriguingly, VDTTS can produce video synchronized speech without any explicit losses or constraints to promote this, suggesting complexities such as synchronization losses or explicit modeling are unnecessary.
While this is a proof-of-concept demonstration, we believe that in the future, VDTTS can be upgraded to be used in scenarios where the input text differs from the original video signal. This kind of a model would be a valuable tool for tasks such as translation dubbing.
Acknowledgements
We would like to thank the co-authors of this research: Michelle Tadmor Ramanovich, Ye Jia, Brendan Shillingford, and Miaosen Wang. We are also grateful to the valued contributions, discussions, and feedback from Nadav Bar, Jay Tenenbaum, Zach Gleicher, Paul McCartney, Marco Tagliasacchi, and Yoni Tzafir.
Quick links