
VaultGemma: The world's most capable differentially private LLM
September 12, 2025
Amer Sinha, Software Engineer, and Ryan McKenna, Research Scientist, Google Research
We introduce VaultGemma, the most capable model trained from scratch with differential privacy.
Quick links
As AI becomes more integrated into our lives, building it with privacy at its core is a critical frontier for the field. Differential privacy (DP) offers a mathematically sound solution by adding calibrated noise to prevent memorization. However, applying DP to LLMs introduces trade-offs. Understanding these trade-offs is crucial. Applying DP noise alters traditional scaling laws — rules describing performance dynamics — by reducing training stability (the model's ability to learn consistently without experiencing catastrophic events like loss spikes or divergence) and significantly increasing batch size (a collection of training examples sent to the model simultaneously for processing) and computation costs.
Our new research, “Scaling Laws for Differentially Private Language Models”, conducted in partnership with Google DeepMind, establishes laws that accurately model these intricacies, providing a complete picture of the compute-privacy-utility trade-offs. Guided by this research, we’re excited to introduce VaultGemma, the largest (1B-parameters), open model trained from scratch with differential privacy. We are releasing the weights on Hugging Face and Kaggle, alongside a technical report, to advance the development of the next generation of private AI.
Understanding the scaling laws
With a carefully thought-out experimental methodology, we aimed to quantify the benefit of increasing model sizes, batch sizes, and iterations in the context of DP training. Our work required making some simplifying assumptions to overcome the exponential number of combinations one might consider trying. We assumed that how well the model learns depends mostly on the "noise-batch ratio” which compares the amount of random noise we add for privacy to the size of the data groups (batches) we use for training. This assumption works because the privacy noise we add is much greater than any natural randomness that comes from sampling the data.
To establish a DP scaling law, we conducted a comprehensive set of experiments to evaluate performance across a variety of model sizes and noise-batch ratios. The resulting empirical data, together with known deterministic relationships between other variables, allows us to answer a variety of interesting scaling-laws–style queries, such as, “For a given compute budget, privacy budget, and data budget, what is the optimal training configuration to achieve the lowest possible training loss?”

The structure of our DP scaling laws. We establish that predicted loss can be accurately modeled using primarily the model size, iterations and the noise-batch ratio, simplifying the complex interactions between the compute, privacy, and data budgets.
Key findings: A powerful synergy
Before diving into the full scaling laws, it’s useful to understand the dynamics and synergies between the compute budget, privacy budget, and data budget from a privacy accounting perspective — i.e., understand how these factors influence the noise-batch ratio for a fixed model size and number of iterations. This analysis is significantly cheaper to do as it does not require any model training, yet it yields a number of useful insights. For instance, increasing the privacy budget in isolation leads to diminishing returns, unless coupled with a corresponding increase in either the compute budget (FLOPs) or data budget (tokens).
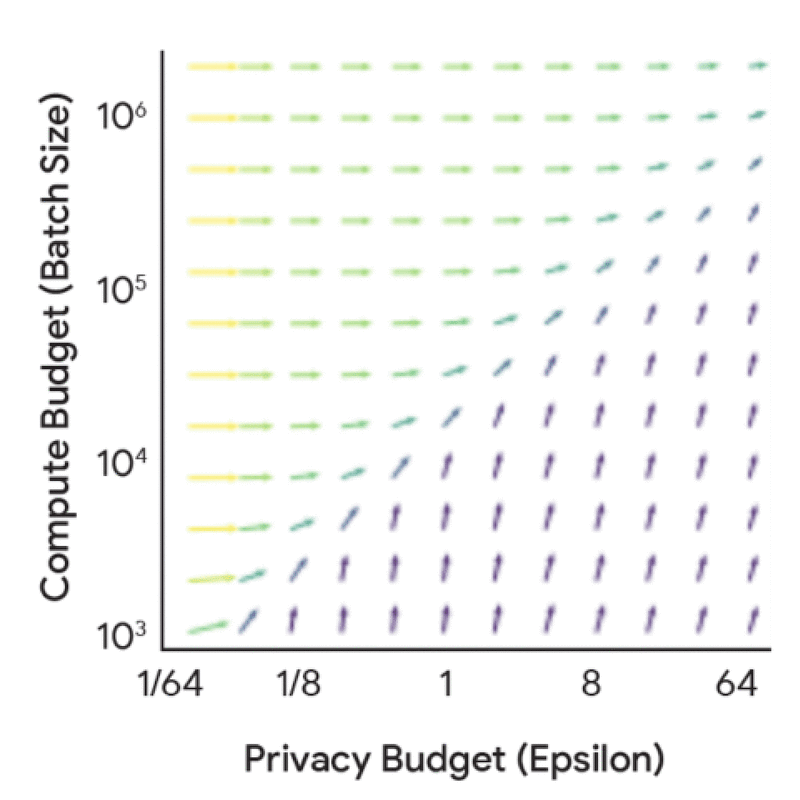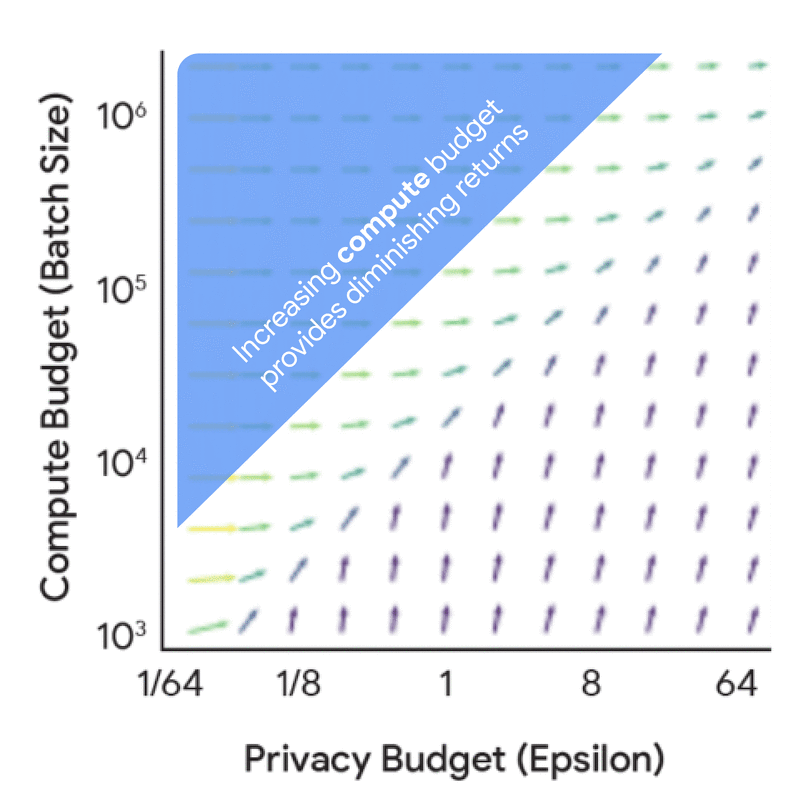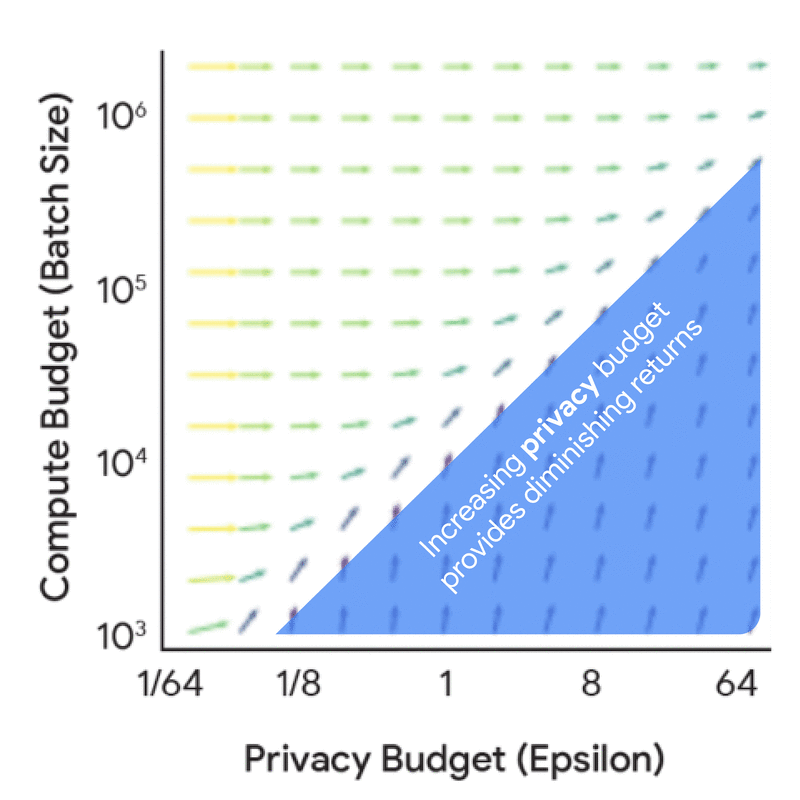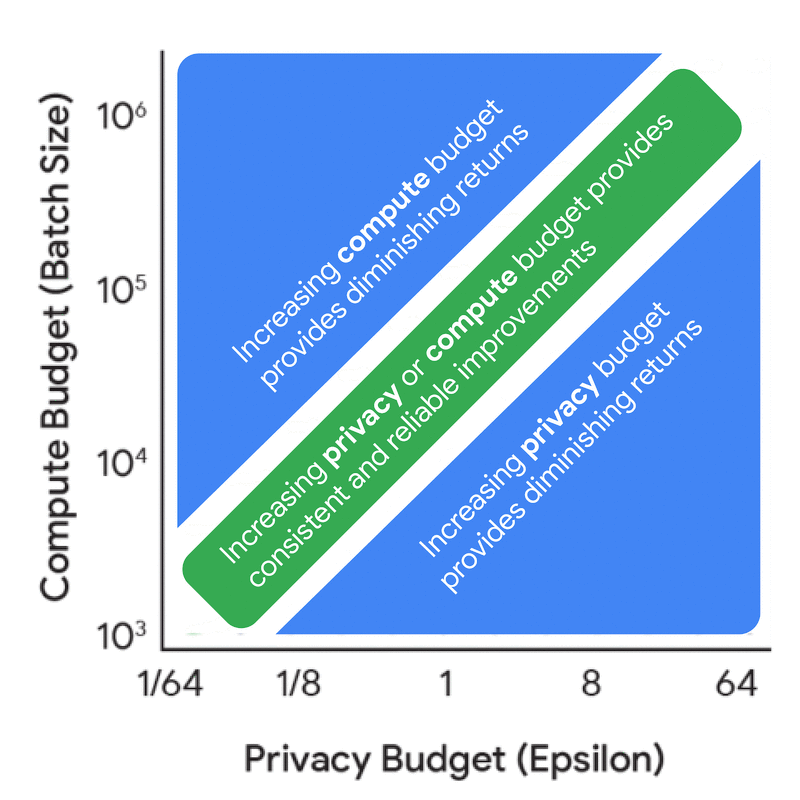
Marginal benefit of increasing the privacy budget (epsilon) and the compute budget (batch size) in terms of their effect on the noise-batch ratio.
To explore this synergy further, the visualization below shows how the optimal training configuration changes based on different constraints. As the privacy and compute budgets change, notice how the recommendation shifts between investing in a larger model versus training with larger batch sizes or more iterations.
Predicted training loss for different settings of data/privacy/compute budget, and a further detailed breakdown by the number of iterations, batch size, and model size. The plots show both the minimum achievable loss for different budget settings, along with the optimal hyper-parameter configurations.
This data provides a wealth of useful insights for practitioners. While all the insights are reported in the paper, a key finding is that one should train a much smaller model with a much larger batch size than would be used without DP. This general insight should be unsurprising to a DP expert given the importance of large batch sizes. While this general insight holds across many settings, the optimal training configurations do change with the privacy and data budgets. Understanding the exact trade-off is crucial to ensure that both the compute and privacy budgets are used judiciously in real training scenarios. The above visualizations also reveal that there is often wiggle room in the training configurations — i.e., a range of model sizes might provide very similar utility if paired with the correct number of iterations and/or batch size.
Applying the scaling laws to build VaultGemma
The Gemma models are designed with responsibility and safety at their core. This makes them a natural foundation for developing a production-quality, DP-trained model like VaultGemma.
Algorithmic advancements: Training at scale
The scaling laws we derived above represent an important first step towards training a useful Gemma model with DP. We used the scaling laws to determine both how much compute we needed to train a compute-optimal 1B parameter Gemma 2-based model with DP, and how to allocate that compute among batch size, iterations, and sequence length to achieve the best utility.
One prominent gap between the research underlying the scaling laws and the actual training of VaultGemma was our handling of Poisson sampling, which is a central component of DP-SGD. We initially used a straightforward method of loading data in uniform batches but then switched to Poisson sampling to get the best privacy guarantees with the least amount of noise. This method posed two main challenges: it created batches of different sizes, and it required a specific, randomized order for processing the data. We solved this by using our recent work on Scalable DP-SGD, which allows us to process data in fixed-size batches — either by adding extra padding or trimming them — while still maintaining strong privacy protections.
Results
Armed with our new scaling laws and advanced training algorithms, we built VaultGemma, to date the largest (1B-parameters) open model fully pre-trained with differential privacy with an approach that can yield high-utility models.
From training VaultGemma, we found our scaling laws to be highly accurate. The final training loss of VaultGemma was remarkably close to what our equations predicted, validating our research and providing the community with a reliable roadmap for future private model development.

Performance comparison of VaultGemma 1B (differentially private) against its non-private counterpart (Gemma3 1B) and an older baseline (GPT-2 1.5B). The results quantify the current resource investment required for privacy and demonstrate that modern DP training yields utility comparable to non-private models from roughly five years ago.
We also compare downstream performance of our model against its non-private counterpart across a range of standard academic benchmarks (i.e., HellaSwag, BoolQ, PIQA, SocialIQA, TriviaQA, ARC-C, ARC-E ). To put this performance in perspective and quantify the current resource investment required for privacy, we also include a comparison to an older similar-sized GPT-2 model, which performs similarly on these benchmarks. This comparison illustrates that today’s private training methods produce models with utility comparable to that of non-private models from roughly 5 years ago, highlighting the important gap our work will help the community systematically close.
Finally, the model comes with strong theoretical and empirical privacy protections.
Formal privacy guarantee
In general, both the privacy parameters (ε, δ) and the privacy unit are important considerations when doing DP training, as these together determine what the trained model can learn. VaultGemma was trained with a sequence-level DP guarantee of (ε ≤ 2.0, δ ≤ 1.1e-10), where a sequence consists of 1024 consecutive tokens extracted from heterogeneous data sources. Specifically, we used the same training mixture that was used to train the Gemma 2 model, consisting of a number of documents of varying lengths. During pre-processing, long documents are split up and tokenized into multiple sequences, and shorter documents are packed together into a single sequence. While the sequence-level privacy unit was a natural choice for our training mixture, in situations where there is a clear mapping between data and users, user-level differential privacy would be a better choice.
What does this mean in practice? Informally speaking, because we provide protection at the sequence level, if information relating to any (potentially private) fact or inference occurs in a single sequence, then VaultGemma essentially does not know that fact: the response to any query will be statistically similar to the result from a model that never trained on the sequence in question. However, if many training sequences contain information relevant to a particular fact, then in general VaultGemma will be able to provide that information.
Empirical memorization
To complement our sequence-level DP guarantee, we conduct additional tests of the empirical privacy properties of the trained model. To do so, we prompted the model with a 50-token prefix from a training document to see if it would generate the corresponding 50-token suffix. VaultGemma 1B shows no detectable memorization of its training data and successfully demonstrates the efficacy of DP training.
Conclusion
VaultGemma represents a significant step forward in the journey toward building AI that is both powerful and private by design. By developing and applying a new, robust understanding of the scaling laws for DP, we have successfully trained and released the largest open, DP-trained language model to date.
While a utility gap still exists between DP-trained and non-DP–trained models, we believe this gap can be systematically narrowed with more research on mechanism design for DP training. We hope that VaultGemma and our accompanying research will empower the community to build the next generation of safe, responsible, and private AI for everyone.
Acknowledgements
We'd like to thank the entire Gemma and Google Privacy teams for their contributions and support throughout this project, in particular, Peter Kairouz, Brendan McMahan and Dan Ramage for feedback on the blog post, Mark Simborg and Kimberly Schwede for help with visualizations, and the teams at Google that helped with algorithm design, infrastructure implementation, and production maintenance. The following people directly contributed to the work presented here (ordered alphabetically): Borja Balle, Zachary Charles, Christopher A. Choquette-Choo, Lynn Chua, Prem Eruvbetine, Badih Ghazi, Steve He, Yangsibo Huang, Armand Joulin, George Kaissis, Pritish Kamath, Ravi Kumar, Daogao Liu, Ruibo Liu, Pasin Manurangsi, Thomas Mesnard, Andreas Terzis, Tris Warkentin, Da Yu, and Chiyuan Zhang.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence


