Using Machine Learning to Explore Neural Network Architecture
May 17, 2017
Posted by Quoc Le & Barret Zoph, Research Scientists, Google Brain team
Quick links
At Google, we have successfully applied deep learning models to many applications, from image recognition to speech recognition to machine translation. Typically, our machine learning models are painstakingly designed by a team of engineers and scientists. This process of manually designing machine learning models is difficult because the search space of all possible models can be combinatorially large — a typical 10-layer network can have ~1010 candidate networks! For this reason, the process of designing networks often takes a significant amount of time and experimentation by those with significant machine learning expertise.
 |
| Our GoogleNet architecture. Design of this network required many years of careful experimentation and refinement from initial versions of convolutional architectures. |
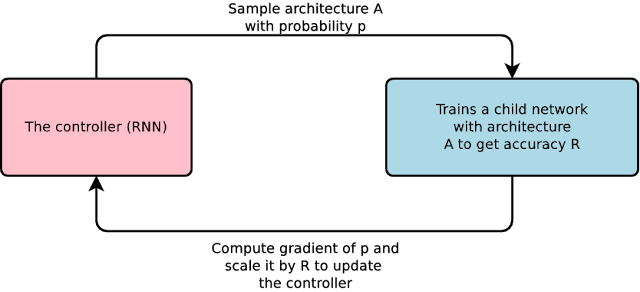
In our approach (which we call "AutoML"), a controller neural net can propose a “child” model architecture, which can then be trained and evaluated for quality on a particular task. That feedback is then used to inform the controller how to improve its proposals for the next round. We repeat this process thousands of times — generating new architectures, testing them, and giving that feedback to the controller to learn from. Eventually the controller learns to assign high probability to areas of architecture space that achieve better accuracy on a held-out validation dataset, and low probability to areas of architecture space that score poorly. Here’s what the process looks like:

So, what kind of neural nets does it produce? Let’s take one example: a recurrent architecture that’s trained to predict the next word on the Penn Treebank dataset. On the left here is a neural net designed by human experts. On the right is a recurrent architecture created by our method:

The machine-chosen architecture does share some common features with the human design, such as using addition to combine input and previous hidden states. However, there are some notable new elements — for example, the machine-chosen architecture incorporates a multiplicative combination (the left-most blue node on the right diagram labeled “elem_mult”). This type of combination is not common for recurrent networks, perhaps because researchers see no obvious benefit for having it. Interestingly, a simpler form of this approach was recently suggested by human designers, who also argued that this multiplicative combination can actually alleviate gradient vanishing/exploding issues, suggesting that the machine-chosen architecture was able to discover a useful new neural net architecture.
This approach may also teach us something about why certain types of neural nets work so well. The architecture on the right here has many channels so that the gradient can flow backwards, which may help explain why LSTM RNNs work better than standard RNNs.
Going forward, we’ll work on careful analysis and testing of these machine-generated architectures to help refine our understanding of them. If we succeed, we think this can inspire new types of neural nets and make it possible for non-experts to create neural nets tailored to their particular needs, allowing machine learning to have a greater impact to everyone.
References
[1] Large-Scale Evolution of Image Classifiers, Esteban Real, Sherry Moore, Andrew Selle, Saurabh Saxena, Yutaka Leon Suematsu, Quoc Le, Alex Kurakin. International Conference on Machine Learning, 2017.
[2] Neural Architecture Search with Reinforcement Learning, Barret Zoph, Quoc V. Le. International Conference on Learning Representations, 2017.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯