Using Evolutionary AutoML to Discover Neural Network Architectures
March 15, 2018
Posted by Esteban Real, Senior Software Engineer, Google Brain Team
Quick links
The brain has evolved over a long time, from very simple worm brains 500 million years ago to a diversity of modern structures today. The human brain, for example, can accomplish a wide variety of activities, many of them effortlessly — telling whether a visual scene contains animals or buildings feels trivial to us, for example. To perform activities like these, artificial neural networks require careful design by experts over years of difficult research, and typically address one specific task, such as to find what's in a photograph, to call a genetic variant, or to help diagnose a disease. Ideally, one would want to have an automated method to generate the right architecture for any given task.
One approach to generate these architectures is through the use of evolutionary algorithms. Traditional research into neuro-evolution of topologies (e.g. Stanley and Miikkulainen 2002) has laid the foundations that allow us to apply these algorithms at scale today, and many groups are working on the subject, including OpenAI, Uber Labs, Sentient Labs and DeepMind. Of course, the Google Brain team has been thinking about AutoML too. In addition to learning-based approaches (eg. reinforcement learning), we wondered if we could use our computational resources to programmatically evolve image classifiers at unprecedented scale. Can we achieve solutions with minimal expert participation? How good can today's artificially-evolved neural networks be? We address these questions through two papers.
In “Large-Scale Evolution of Image Classifiers,” presented at ICML 2017, we set up an evolutionary process with simple building blocks and trivial initial conditions. The idea was to "sit back" and let evolution at scale do the work of constructing the architecture. Starting from very simple networks, the process found classifiers comparable to hand-designed models at the time. This was encouraging because many applications may require little user participation. For example, some users may need a better model but may not have the time to become machine learning experts. A natural question to consider next was whether a combination of hand-design and evolution could do better than either approach alone. Thus, in our more recent paper, “Regularized Evolution for Image Classifier Architecture Search” (2018), we participated in the process by providing sophisticated building blocks and good initial conditions (discussed below). Moreover, we scaled up computation using Google's new TPUv2 chips. This combination of modern hardware, expert knowledge, and evolution worked together to produce state-of-the-art models on CIFAR-10 and ImageNet, two popular benchmarks for image classification.
A Simple Approach
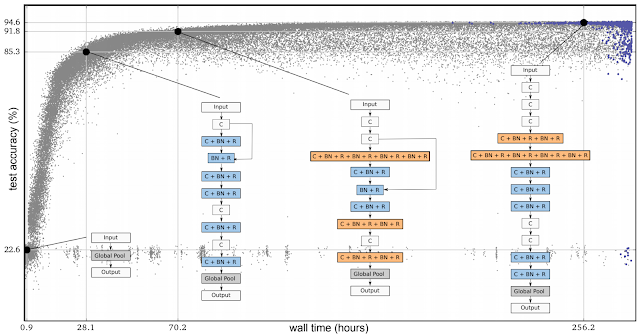
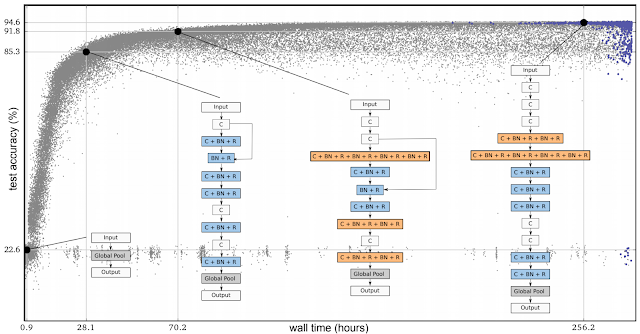
The following is an example of an experiment from our first paper. In the figure below, each dot is a neural network trained on the CIFAR-10 dataset, which is commonly used to train image classifiers. Initially, the population consists of one thousand identical simple seed models (no hidden layers). Starting from simple seed models is important — if we had started from a high-quality model with initial conditions containing expert knowledge, it would have been easier to get a high-quality model in the end. Once seeded with the simple models, the process advances in steps. At each step, a pair of neural networks is chosen at random. The network with higher accuracy is selected as a parent and is copied and mutated to generate a child that is then added to the population, while the other neural network dies out. All other networks remain unchanged during the step. With the application of many such steps in succession, the population evolves.
 |
| Progress of an evolution experiment. Each dot represents an individual in the population. The four diagrams show examples of discovered architectures. These correspond to the best individual (rightmost; selected by validation accuracy) and three of its ancestors. |
In all the above, even though we were minimizing the researcher's participation by having simple initial architectures and intuitive mutations, a good amount of expert knowledge went into the building blocks those architectures were made of. These included important inventions such as convolutions, ReLUs and batch-normalization layers. We were evolving an architecture made up of these components. The term "architecture" is not accidental: this is analogous to constructing a house with high-quality bricks.
Combining Evolution and Hand Design
After our first paper, we wanted to reduce the search space to something more manageable by giving the algorithm fewer choices to explore. Using our architectural analogy, we removed all the possible ways of making large-scale errors, such as putting the wall above the roof, from the search space. Similarly with neural network architecture searches, by fixing the large-scale structure of the network, we can help the algorithm out. So how to do this? The inception-like modules introduced in Zoph et al. (2017) for the purpose of architecture search proved very powerful. Their idea is to have a deep stack of repeated modules called cells. The stack is fixed but the architecture of the individual modules can change.
 |
| The building blocks introduced in Zoph et al. (2017). The diagram on the left is the outer structure of the full neural network, which parses the input data from bottom to top through a stack of repeated cells. The diagram on the right is the inside structure of a cell. The goal is to find a cell that yields an accurate network. |
A Controlled Comparison
Even though the mutation/selection evolutionary process is not complicated, maybe an even more straightforward approach (like random search) could have done the same. Other alternatives, though not simpler, also exist in the literature (like reinforcement learning). Because of this, the main purpose of our second paper was to provide a controlled comparison between techniques.
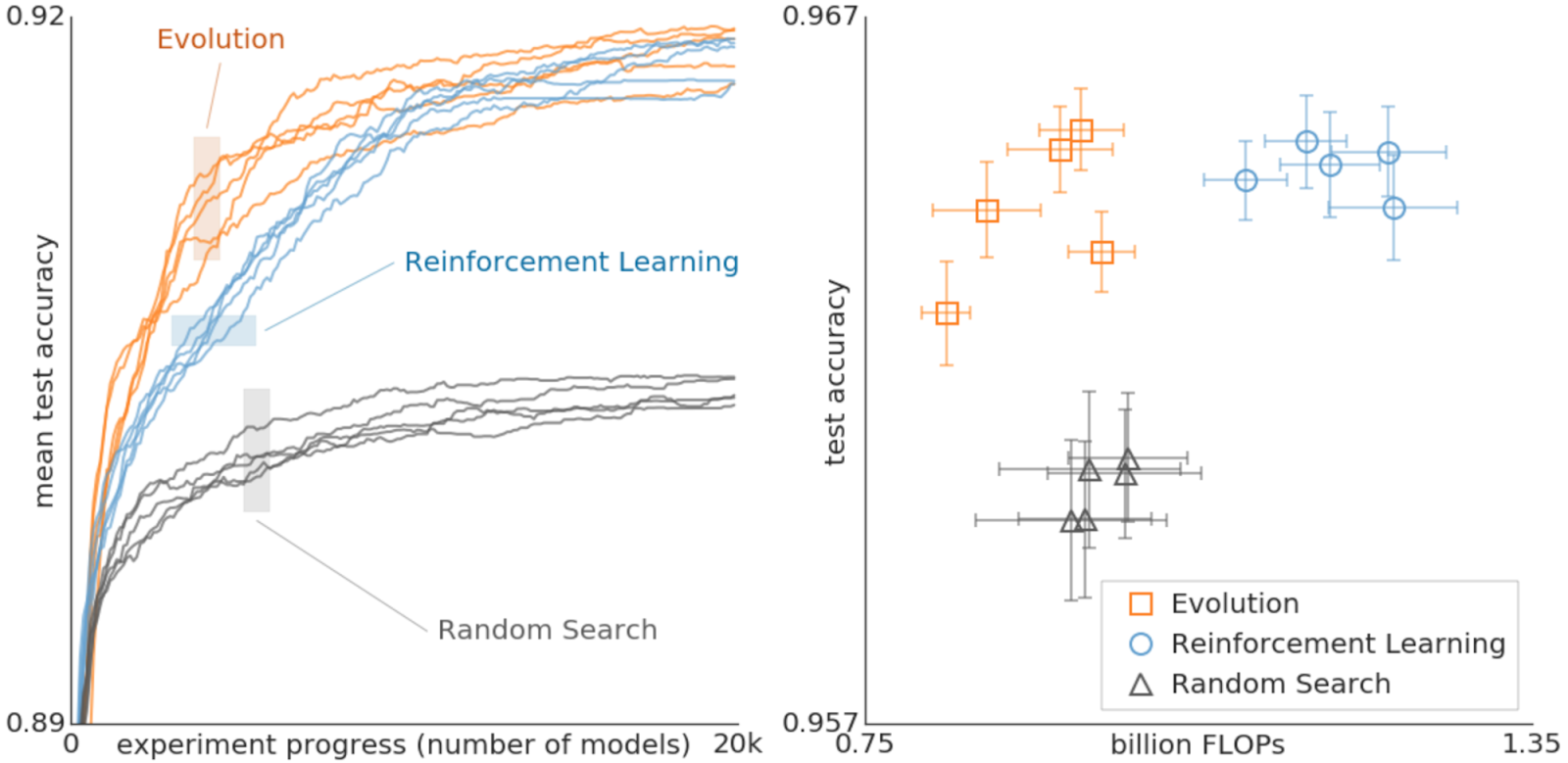 |
| Comparison between evolution, reinforcement learning, and random search for the purposes of architecture search. These experiments were done on the CIFAR-10 dataset, under the same conditions as Zoph et al. (2017), where the search space was originally used with reinforcement learning. |
One important feature of the evolutionary algorithm we used in our second paper is a form of regularization: instead of letting the worst neural networks die, we remove the oldest ones — regardless of how good they are. This improves robustness to changes in the task being optimized and tends to produce more accurate networks in the end. One reason for this may be that since we didn't allow weight inheritance, all networks must train from scratch. Therefore, this form of regularization selects for networks that remain good when they are re-trained. In other words, because a model can be more accurate just by chance — noise in the training process means even identical architectures may get different accuracy values — only architectures that remain accurate through the generations will survive in the long run, leading to the selection of networks that retrain well. More details of this conjecture can be found in the paper.
The state-of-the-art models we evolved are nicknamed AmoebaNets, and are one of the latest results from our AutoML efforts. All these experiments took a lot of computation — we used hundreds of GPUs/TPUs for days. Much like a single modern computer can outperform thousands of decades-old machines, we hope that in the future these experiments will become household. Here we aimed to provide a glimpse into that future.
Acknowledgements
We would like to thank Alok Aggarwal, Yanping Huang, Andrew Selle, Sherry Moore, Saurabh Saxena, Yutaka Leon Suematsu, Jie Tan, Alex Kurakin, Quoc Le, Barret Zoph, Jon Shlens, Vijay Vasudevan, Vincent Vanhoucke, Megan Kacholia, Jeff Dean, and the rest of the Google Brain team for the collaborations that made this work possible.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence
×
❮
❯