Universal Speech Model (USM): State-of-the-art speech AI for 100+ languages
March 6, 2023
Posted by Yu Zhang, Research Scientist, and James Qin, Software Engineer, Google Research
Quick links

Last November, we announced the 1,000 Languages Initiative, an ambitious commitment to build a machine learning (ML) model that would support the world’s one thousand most-spoken languages, bringing greater inclusion to billions of people around the globe. However, some of these languages are spoken by fewer than twenty million people, so a core challenge is how to support languages for which there are relatively few speakers or limited available data.
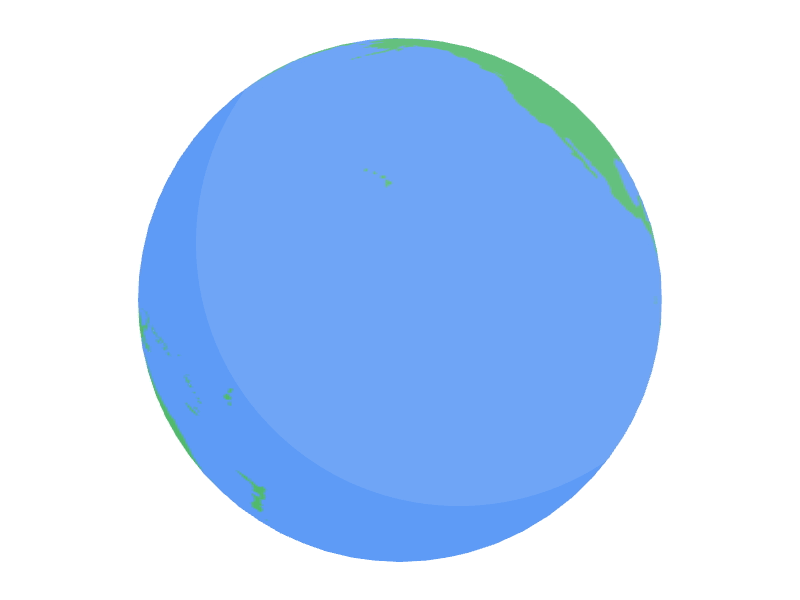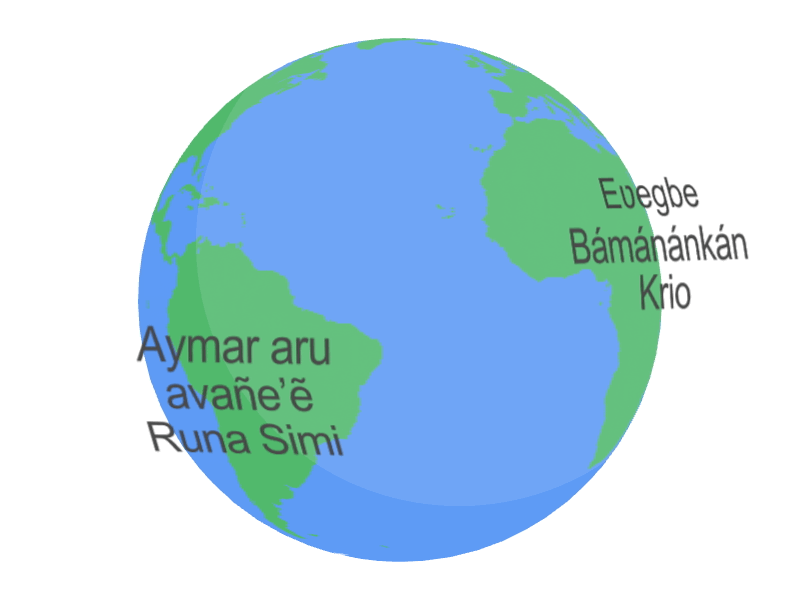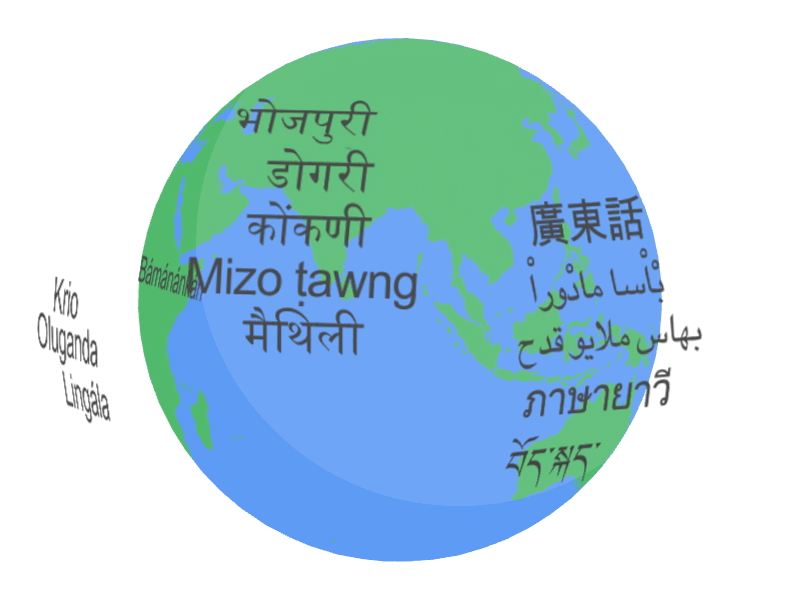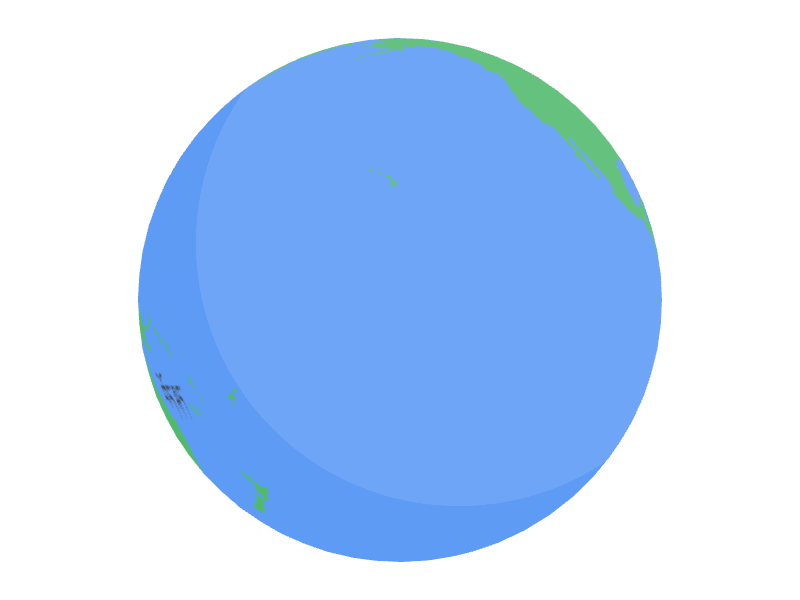
Today, we are excited to share more about the Universal Speech Model (USM), a critical first step towards supporting 1,000 languages. USM is a family of state-of-the-art speech models with 2B parameters trained on 12 million hours of speech and 28 billion sentences of text, spanning 300+ languages. USM, which is for use in YouTube (e.g., for closed captions), can perform automatic speech recognition (ASR) not only on widely-spoken languages like English and Mandarin, but also on under-resourced languages like Amharic, Cebuano, Assamese, and Azerbaijani to name a few. In “Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages”, we demonstrate that utilizing a large unlabeled multilingual dataset to pre-train the encoder of the model and fine-tuning on a smaller set of labeled data enables us to recognize under-represented languages. Moreover, our model training process is effective at adapting to new languages and data.
 |
| A sample of the languages that USM supports. |
Challenges in current ASR
To accomplish this ambitious goal, we need to address two significant challenges in ASR.
First, there is a lack of scalability with conventional supervised learning approaches. A fundamental challenge of scaling speech technologies to many languages is obtaining enough data to train high-quality models. With conventional approaches, audio data needs to be either manually labeled, which is time-consuming and costly, or collected from sources with pre-existing transcriptions, which are harder to find for languages that lack wide representation. In contrast, self-supervised learning can leverage audio-only data, which is available in much larger quantities across languages. This makes self-supervision a better approach to accomplish our goal of scaling across hundreds of languages.
Another challenge is that models must improve in a computationally efficient manner while we expand the language coverage and quality. This requires the learning algorithm to be flexible, efficient, and generalizable. More specifically, such an algorithm should be able to use large amounts of data from a variety of sources, enable model updates without requiring complete retraining, and generalize to new languages and use cases.
Our approach: Self-supervised learning with fine-tuning
USM uses the standard encoder-decoder architecture, where the decoder can be CTC, RNN-T, or LAS. For the encoder, USM uses the Conformer, or convolution-augmented transformer. The key component of the Conformer is the Conformer block, which consists of attention, feed-forward, and convolutional modules. It takes as input the log-mel spectrogram of the speech signal and performs a convolutional sub-sampling, after which a series of Conformer blocks and a projection layer are applied to obtain the final embeddings.
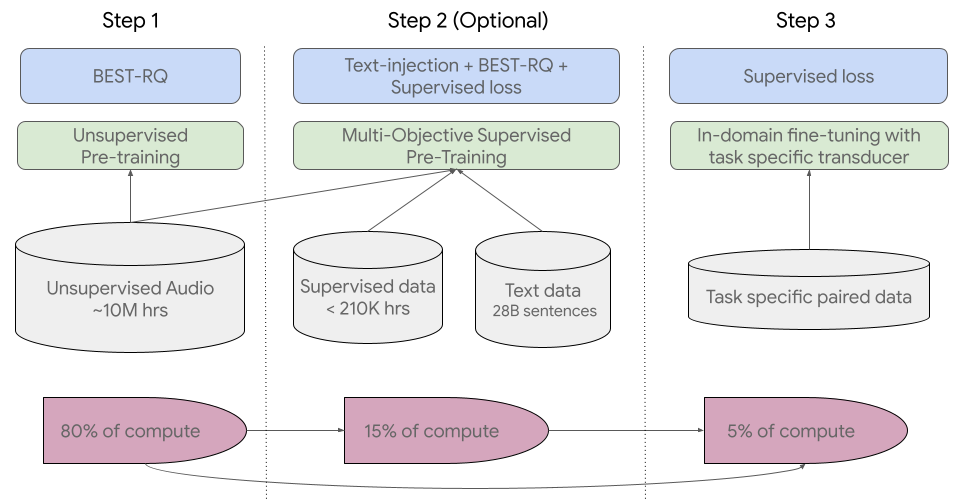
Our training pipeline starts with the first step of self-supervised learning on speech audio covering hundreds of languages. In the second optional step, the model’s quality and language coverage can be improved through an additional pre-training step with text data. The decision to incorporate the second step depends on whether text data is available. USM performs best with this second optional step. The last step of the training pipeline is to fine-tune on downstream tasks (e.g., ASR or automatic speech translation) with a small amount of supervised data.
For the first step, we use BEST-RQ, which has already demonstrated state-of-the-art results on multilingual tasks and has proven to be efficient when using very large amounts of unsupervised audio data.
In the second (optional) step, we used multi-objective supervised pre-training to incorporate knowledge from additional text data. The model introduces an additional encoder module to take text as input and additional layers to combine the output of the speech encoder and the text encoder, and trains the model jointly on unlabeled speech, labeled speech, and text data.
In the last stage, USM is fine-tuned on the downstream tasks. The overall training pipeline is illustrated below. With the knowledge acquired during pre-training, USM models achieve good quality with only a small amount of supervised data from the downstream tasks.
 |
| USM’s overall training pipeline. |
Key results
Performance across multiple languages on YouTube Captions
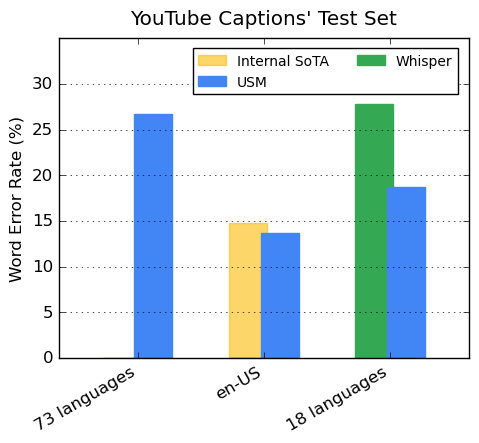
Our encoder incorporates 300+ languages through pre-training. We demonstrate the effectiveness of the pre-trained encoder through fine-tuning on YouTube Caption’s multilingual speech data. The supervised YouTube data includes 73 languages and has on average less than three thousand hours of data per language. Despite limited supervised data, the model achieves less than 30% word error rate (WER; lower is better) on average across the 73 languages, a milestone we have never achieved before. For en-US, USM has a 6% relative lower WER compared to the current internal state-of-the-art model. Lastly, we compare with the recently released large model, Whisper (large-v2), which was trained with more than 400k hours of labeled data. For the comparison, we only use the 18 languages that Whisper can successfully decode with lower than 40% WER. Our model has, on average, a 32.7% relative lower WER compared to Whisper for these 18 languages.
 |
| USM supports all 73 languages in the YouTube Captions' Test Set and outperforms Whisper on the languages it can support with lower than 40% WER. Lower WER is better. |
Generalization to downstream ASR tasks
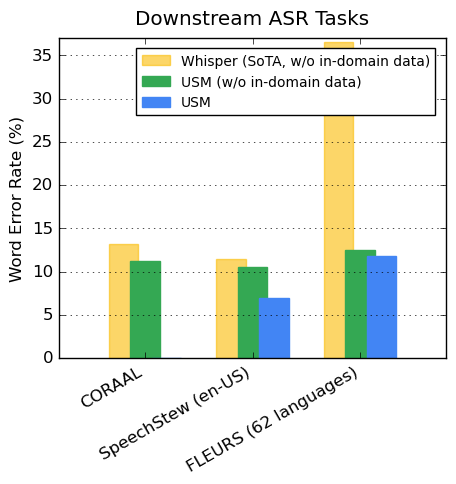
On publicly available datasets, our model shows lower WER compared to Whisper on CORAAL (African American Vernacular English), SpeechStew (en-US), and FLEURS (102 languages). Our model achieves lower WER with and without training on in-domain data. The comparison on FLEURS reports the subset of languages (62) that overlaps with the languages supported by the Whisper model. For FLEURS, USM without in-domain data has a 65.8% relative lower WER compared to Whisper and has a 67.8% relative lower WER with in-domain data.
 |
| Comparison of USM (with or without in-domain data) and Whisper results on ASR benchmarks. Lower WER is better. |
Performance on automatic speech translation (AST)
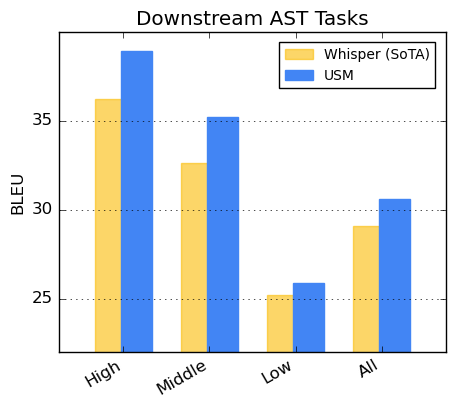
For speech translation, we fine-tune USM on the CoVoST dataset. Our model, which includes text via the second stage of our pipeline, achieves state-of-the-art quality with limited supervised data. To assess the breadth of the model’s performance, we segment the languages from the CoVoST dataset into high, medium, and low based on resource availability and calculate the BLEU score (higher is better) for each segment. As shown below, USM outperforms Whisper for all segments.
 |
| CoVoST BLEU score. Higher BLEU is better. |
Toward 1,000 languages
The development of USM is a critical effort towards realizing Google’s mission to organize the world’s information and make it universally accessible. We believe USM’s base model architecture and training pipeline comprise a foundation on which we can build to expand speech modeling to the next 1,000 languages.
Learn More
Check out our paper here. Researchers can request access to the USM API here.
Acknowledgements
We thank all the co-authors for contributing to the project and paper, including Andrew Rosenberg, Ankur Bapna, Bhuvana Ramabhadran, Bo Li, Chung-Cheng Chiu, Daniel Park, Françoise Beaufays, Hagen Soltau, Gary Wang, Ginger Perng, James Qin, Jason Riesa, Johan Schalkwyk, Ke Hu, Nanxin Chen, Parisa Haghani, Pedro Moreno Mengibar, Rohit Prabhavalkar, Tara Sainath, Trevor Strohman, Vera Axelrod, Wei Han, Yonghui Wu, Yongqiang Wang, Yu Zhang, Zhehuai Chen, and Zhong Meng.
We also thank Alexis Conneau, Min Ma, Shikhar Bharadwaj, Sid Dalmia, Jiahui Yu, Jian Cheng, Paul Rubenstein, Ye Jia, Justin Snyder, Vincent Tsang, Yuanzhong Xu, Tao Wang for useful discussions.
We appreciate valuable feedback and support from Eli Collins, Jeff Dean, Sissie Hsiao, Zoubin Ghahramani. Special thanks to Austin Tarango, Lara Tumeh, Amna Latif, and Jason Porta for their guidance around Responsible AI practices. We thank Elizabeth Adkison, James Cokerille for help with naming the model, Tom Small for the animated graphic, Abhishek Bapna for editorial support, and Erica Moreira for resource management . We thank Anusha Ramesh for feedback, guidance, and assistance with the publication strategy, and Calum Barnes and Salem Haykal for their valuable partnership.
-
Labels:
- Speech Processing
Quick links
Other posts of interest
-

December 3, 2025
From Waveforms to Wisdom: The New Benchmark for Auditory Intelligence- Machine Intelligence ·
- Sound & Accoustics ·
- Speech Processing
-

October 7, 2025
Speech-to-Retrieval (S2R): A new approach to voice search- Machine Intelligence ·
- Natural Language Processing ·
- Product ·
- Speech Processing
-

July 2, 2025
Making group conversations more accessible with sound localization- Human-Computer Interaction and Visualization ·
- Sound & Accoustics ·
- Speech Processing