Understanding Contextual Facial Expressions Across the Globe
May 24, 2021
Posted by Alan Cowen, Visiting Researcher and Gautam Prasad, Software Engineer, Google Research
Quick links
It might seem reasonable to assume that people’s facial expressions are universal — so, for example, whether a person is from Brazil, India or Canada, their smile upon seeing close friends or their expression of awe at a fireworks display would look essentially the same. But is that really true? Is the association between these facial expressions and their relevant context across geographies indeed universal? What can similarities — or differences — between the situations where someone grins or frowns tell us about how people may be connected across different cultures?
Scientists seeking to answer these questions and to uncover the extent to which people are connected across cultures and geography often use survey-based studies that can rely heavily on local language, norms, and values. However, such studies are not scalable, and often end up with small sample sizes and inconsistent findings.
In contrast to survey-based studies, studying patterns of facial movement provides a more direct understanding of expressive behavior. But analyzing how facial expressions are actually used in everyday life would require researchers to go through millions of hours of real-world footage, which is too time-consuming to do manually. In addition, facial expressions and the contexts in which they are exhibited are complicated, requiring large sample sizes in order to make statistically sound conclusions. While existing studies have produced diverging answers to the question of the universality of facial expressions in given contexts, applying machine learning (ML) in order to appropriately scale the research has the potential to provide clarity.
In “Sixteen facial expressions occur in similar contexts worldwide”, published in Nature, we present research undertaken in collaboration with UC Berkeley to conduct the first large-scale worldwide analysis of how facial expressions are actually used in everyday life, leveraging deep neural networks (DNNs) to drastically scale up expression analysis in a responsible and thoughtful way. Using a dataset of six million publicly available videos across 144 countries, we analyze the contexts in which people use a variety of facial expressions and demonstrate that rich nuances in facial behavior — including subtle expressions — are used in similar social situations around the world.
A Deep Neural Network Measuring Facial Expression
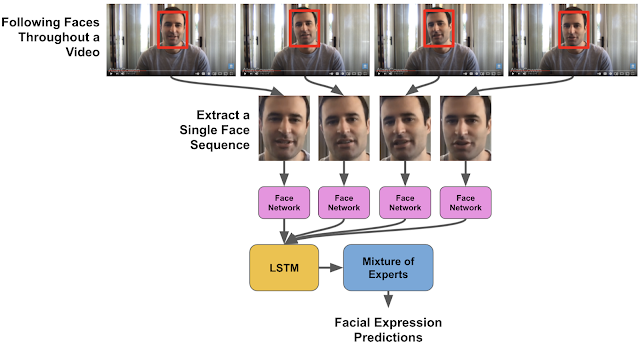
Facial expressions are not static. If one were to examine a person’s expression instant by instant, what might at first appear to be “anger”, may instead end up being “awe”, “surprise” or “confusion”. The interpretation depends on the dynamics of a person’s face as their expression presents itself. The challenge in building a neural network to understand facial expressions, then, is that it must interpret the expression within its temporal context. Training such a system requires a large and diverse, cross-cultural dataset of videos with fully annotated expressions.
To build the dataset, skilled raters manually searched through a broad collection of publicly available videos to identify those likely to contain clips covering all of our pre-selected expression categories. To ensure that the videos matched the region they were assumed to represent, preference in video selection was given to those that included the geographic location of origin. The faces in the videos were then found using a deep convolutional neural network (CNN) — similar to the Google Cloud Face Detection API — that follows faces over the course of the clip using a method based on traditional optical flow. Using an interface similar to Google Crowdsource, annotators then labeled facial expressions across 28 distinct categories if present at any point during the clip. Because the goal was to sample how an average person would perceive an expression, the annotators were not coached or trained, nor were they provided examples or definitions of the target expressions. We discuss additional experiments to evaluate whether the model trained from these annotations was biased below.
 |
| Raters were presented videos with a single face highlighted for their attention. They observed the subject throughout the duration of the clip and annotated the facial expressions they exhibited. (source video) |
The face detection algorithm established a sequence of locations of each face throughout the video. We then used a pre-trained Inception network to extract features representing the most salient aspects of facial expressions from the faces. The features were then fed into a long short-term memory (LSTM) network, a type of recurrent neural network that is able to model how a facial expression might evolve over time due to its ability to remember salient information from the past.
In order to ensure that the model was making consistent predictions across a range of demographic groups, we evaluated the model fairness on an existing dataset that was constructed using similar facial expression labels, targeting a subset of 16 expressions on which it exhibited the best performance.
The model's performance was consistent across all of the demographic groups represented in the evaluation dataset, which provides supporting evidence that the model trained to annotated facial expressions is not measurably biased. The model’s annotations of those 16 facial expressions across 1,500 images can be explored here.
 |
| We modeled the selected face in each video by using a CNN to extract features from the face at each frame, which were then fed into an LSTM network to model the changes in the expression over time. (source video) |
Measuring the Contexts Captured in Videos
To understand the context of facial expressions across millions of videos, we used DNNs that could capture the fine-grained content and automatically recognize the context. The first DNN modeled a combination of text features (title and description) associated with a video along with the actual visual content (video-topic model). In addition, we used a DNN that only relied on text features without any visual information (text-topic model). These models predict thousands of labels describing the videos. In our experiments these models were able to identify hundreds of unique contexts (e.g., wedding, sporting event, or fireworks) showcasing the diversity of the data we used for the analysis.
The Covariation Between Expressions and Contexts Around the World
In our first experiment, we analyzed 3 million public videos captured on mobile phones. We chose to focus on mobile uploads because they are more likely to contain natural expressions. We correlated the facial expressions that occurred in the videos to the context annotations derived from the video-topic model. We found 16 kinds of facial expressions had distinct associations with everyday social contexts that were consistent across the world. For instance, the expressions that people associate with amusement occurred more often in videos with practical jokes; expressions that people associate with awe, in videos with fireworks; and triumph, with sporting events. These results have strong implications for discussions about the relative importance of psychologically relevant context in facial expression, compared to other factors, such as those unique to an individual, culture, or society.
Our second experiment analyzed a separate set of 3 million videos, but this time we annotated the contexts with the text-topic model. The results verified that the findings in the first experiment were not driven by subtle influences of facial expressions in the video on the annotations of the video-topic model. In other words we used this experiment to verify our conclusions from the first experiment given the possibility that the video-topic model could implicitly be factoring in facial expressions when computing its content labels.
 |
| We correlated the expression and context annotations across all of the videos within each region. Each expression was found to have specific associations with different contexts that were preserved across 12 world regions. For example, here, in red, we can see that expressions people associate with awe were found more often in the context of fireworks, pets, and toys than in other contexts. |
In both experiments, the correlations between expressions and contexts appeared to be well-preserved across cultures. To quantify exactly how similar the associations between expressions and contexts were across the 12 different world regions we studied, we computed second-order correlations between each pair of regions. These correlations identify the relationships between different expressions and contexts in each region and then compare them with other regions. We found that 70% of the context–expression associations found in each region are shared across the modern world.
Finally, we asked how many of the 16 kinds of facial expression we measured had distinct associations with different contexts that were preserved around the world. To do so, we applied a method called canonical correlations analysis, which showed that all 16 facial expressions had distinct associations that were preserved across the world.
Conclusions
We were able to examine the contexts in which facial expressions occur in everyday life across cultures at an unprecedented scale. Machine learning allowed us to analyze millions of videos across the world and discover evidence supporting hypotheses that facial expressions are preserved to a degree in similar contexts across cultures.
Our results also leave room for cultural differences. Although the correlations between facial expressions and contexts were 70% consistent around the world, they were up to 30% variable across regions. Neighboring world regions generally had more similar associations between facial expressions and contexts than distant world regions, indicating that the geographic spread of human culture may also play a role in the meanings of facial expressions.
This work shows that we can use machine learning to better understand ourselves and identify common communication elements across cultures. Tools such as DNNs give us the opportunity to provide vast amounts of diverse data in service of scientific discovery, enabling more confidence in the statistical conclusions. We hope our work provides a template for using the tools of machine learning in a responsible way and sparks more innovative research in other scientific domains.
Acknowledgements
Special thanks to our co-authors Dacher Keltner from UC Berkeley, along with Florian Schroff, Brendan Jou, and Hartwig Adam from Google Research. We are also grateful for additional support at Google provided by Laura Rapin, Reena Jana, Will Carter, Unni Nair, Christine Robson, Jen Gennai, Sourish Chaudhuri, Greg Corrado, Brian Eoff, Andrew Smart, Raine Serrano, Blaise Aguera y Arcas, Jay Yagnik, and Carson Mcneil.
-
Labels:
- Machine Perception
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-

October 23, 2025
Google Earth AI: Unlocking geospatial insights with foundation models and cross-modal reasoning- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Machine Perception