TurboQuant: Redefining AI efficiency with extreme compression
March 24, 2026
Amir Zandieh, Research Scientist, and Vahab Mirrokni, VP and Google Fellow, Google Research
We introduce a set of advanced theoretically grounded quantization algorithms that enable massive compression for large language models and vector search engines.
Quick links
Vectors are the fundamental way AI models understand and process information. Small vectors describe simple attributes, such as a point in a graph, while “high-dimensional” vectors capture complex information such as the features of an image, the meaning of a word, or the properties of a dataset. High-dimensional vectors are incredibly powerful, but they also consume vast amounts of memory, leading to bottlenecks in the key-value cache, a high-speed "digital cheat sheet" that stores frequently used information under simple labels so a computer can retrieve it instantly without having to search through a slow, massive database.
Vector quantization is a powerful, classical data compression technique that reduces the size of high-dimensional vectors. This optimization addresses two critical facets of AI: it enhances vector search, the high-speed technology powering large-scale AI and search engines, by enabling faster similarity lookups; and it helps unclog key-value cache bottlenecks by reducing the size of key-value pairs, which enables faster similarity searches and lowers memory costs. However, traditional vector quantization usually introduces its own "memory overhead” as most methods require calculating and storing (in full precision) quantization constants for every small block of data. This overhead can add 1 or 2 extra bits per number, partially defeating the purpose of vector quantization.
Today, we introduce TurboQuant (to be presented at ICLR 2026), a compression algorithm that optimally addresses the challenge of memory overhead in vector quantization. We also present Quantized Johnson-Lindenstrauss (QJL), and PolarQuant (to be presented at AISTATS 2026), which TurboQuant uses to achieve its results. In testing, all three techniques showed great promise for reducing key-value bottlenecks without sacrificing AI model performance. This has potentially profound implications for all compression-reliant use cases, including and especially in the domains of search and AI.
How TurboQuant works
TurboQuant is a compression method that achieves a high reduction in model size with zero accuracy loss, making it ideal for supporting both key-value (KV) cache compression and vector search. It accomplishes this via two key steps:
- High-quality compression (the PolarQuant method): TurboQuant starts by randomly rotating the data vectors. This clever step simplifies the data's geometry, making it easy to apply a standard, high-quality quantizer (a tool that maps a large set of continuous values, like precise decimals, to a smaller, discrete set of symbols or numbers, like integers: examples include audio quantization and jpeg compression) to each part of the vector individually. This first stage uses most of the compression power (the majority of the bits) to capture the main concept and strength of the original vector.
- Eliminating hidden errors: TurboQuant uses a small, residual amount of compression power (just 1 bit) to apply the QJL algorithm to the tiny amount of error left over from the first stage. The QJL stage acts as a mathematical error-checker that eliminates bias, leading to a more accurate attention score.
To fully understand how TurboQuant achieves this efficiency, we take a closer look into how the QJL and PolarQuant algorithms work.
QJL: The zero-overhead, 1-bit trick
QJL uses a mathematical technique called the Johnson-Lindenstrauss Transform to shrink complex, high-dimensional data while preserving the essential distances and relationships between data points. It reduces each resulting vector number to a single sign bit (+1 or -1). This algorithm essentially creates a high-speed shorthand that requires zero memory overhead. To maintain accuracy, QJL uses a special estimator that strategically balances a high-precision query with the low-precision, simplified data. This allows the model to accurately calculate the attention score (the process used to decide which parts of its input are important and which parts can be safely ignored).
PolarQuant: A new “angle” on compression
PolarQuant addresses the memory overhead problem using a completely different approach. Instead of looking at a memory vector using standard coordinates (i.e., X, Y, Z) that indicate the distance along each axis, PolarQuant converts the vector into polar coordinates using a Cartesian coordinate system. This is comparable to replacing "Go 3 blocks East, 4 blocks North" with "Go 5 blocks total at a 37-degree angle”. This results in two pieces of information: the radius, which signifies how strong the core data is, and the angle indicating the data’s direction or meaning). Because the pattern of the angles is known and highly concentrated, the model no longer needs to perform the expensive data normalization step because it maps data onto a fixed, predictable "circular" grid where the boundaries are already known, rather than a "square" grid where the boundaries change constantly. This allows PolarQuant to eliminate the memory overhead that traditional methods must carry.
PolarQuant acts as a high-efficiency compression bridge, converting Cartesian inputs into a compact Polar "shorthand" for storage and processing. The mechanism begins by grouping pairs of coordinates from a d-dimensional vector and mapping them onto a polar coordinate system. Radii are then gathered in pairs for recursive polar transformations — a process that repeats until the data is distilled into a single final radius and a collection of descriptive angles.
Experiments and results
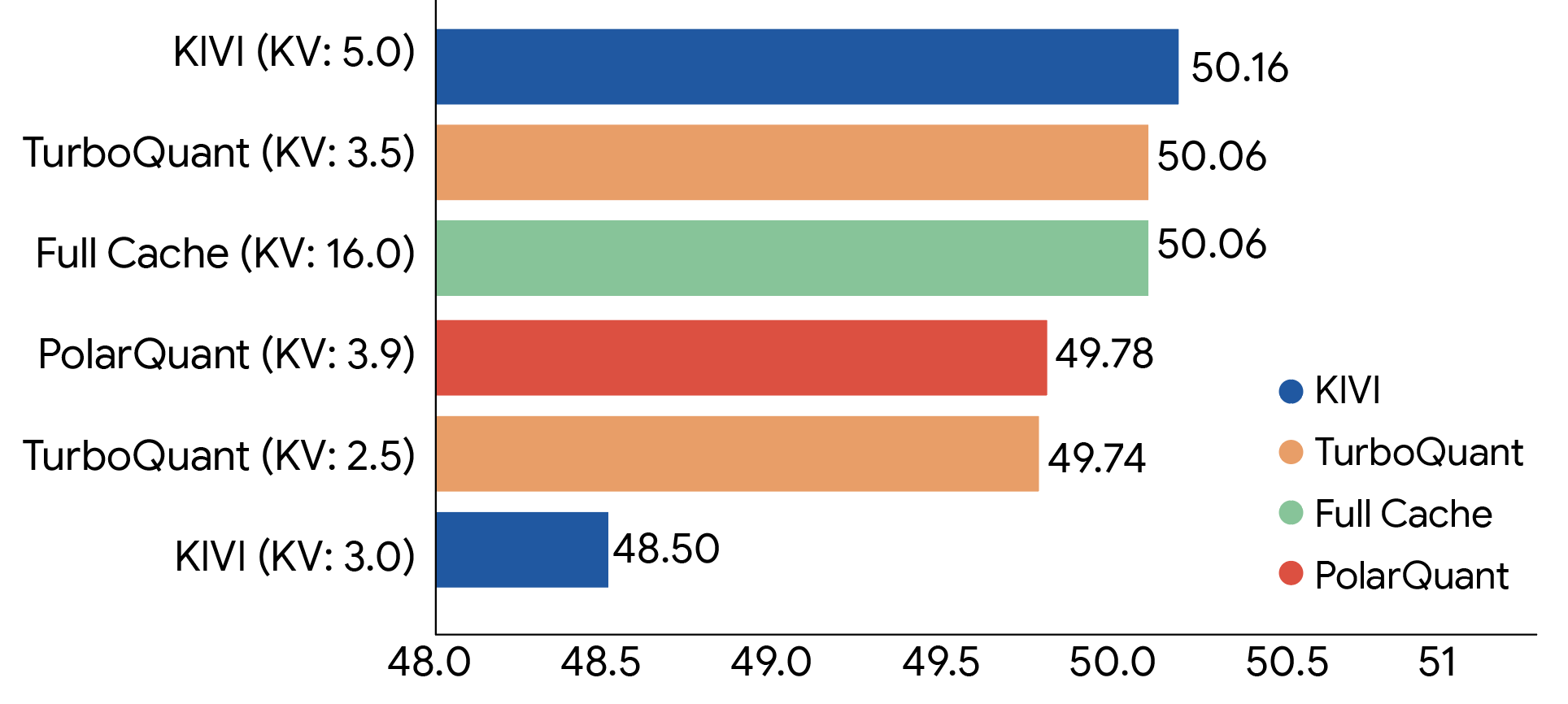
We rigorously evaluated all three algorithms across standard long-context benchmarks including: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval using open-source LLMs (Gemma and Mistral). The experimental data demonstrate that TurboQuant achieves optimal scoring performance in terms of both dot product distortion and recall while simultaneously minimizing the key-value (KV) memory footprint. The chart below shows the aggregated performance scores across diverse tasks, including question answering, code generation, and summarization for TurboQuant, PolarQuant and the KIVI baseline.
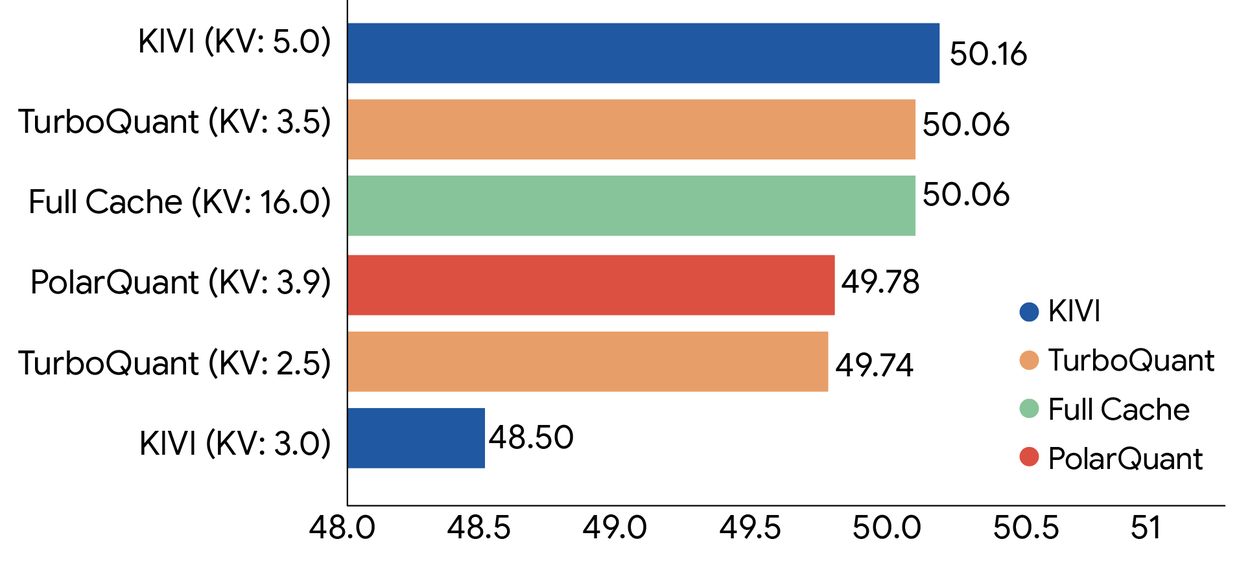
TurboQuant demonstrates robust KV cache compression performance across the LongBench benchmark relative to various compression methods on the Llama-3.1-8B-Instruct model (bitwidths are indicated in brackets).
The results for long-context “needle-in-haystack” tasks (i.e., tests designed to see if a model can find one specific, tiny piece of information buried inside a massive amount of text) are shown below. Again, TurboQuant achieves perfect downstream results across all benchmarks while reducing the key value memory size by a factor of at least 6x. PolarQuant is also nearly loss-less for this task.
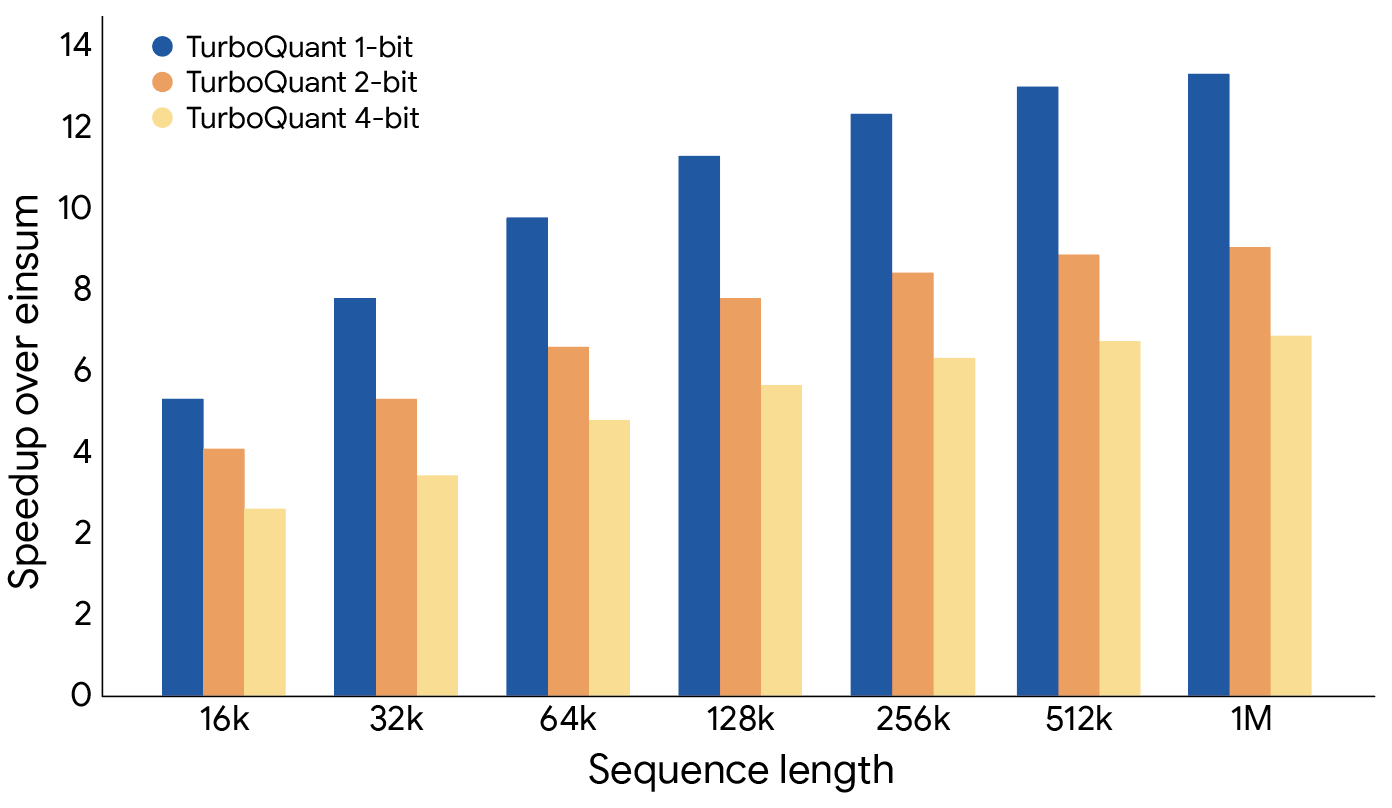
TurboQuant proved it can quantize the key-value cache to just 3 bits without requiring training or fine-tuning and causing any compromise in model accuracy, all while achieving a faster runtime than the original LLMs (Gemma and Mistral). It is exceptionally efficient to implement and incurs negligible runtime overhead. The following plot illustrates the speedup in computing attention logits using TurboQuant: specifically, 4-bit TurboQuant achieves up to 8x performance increase over 32-bit unquantized keys on H100 GPU accelerators.
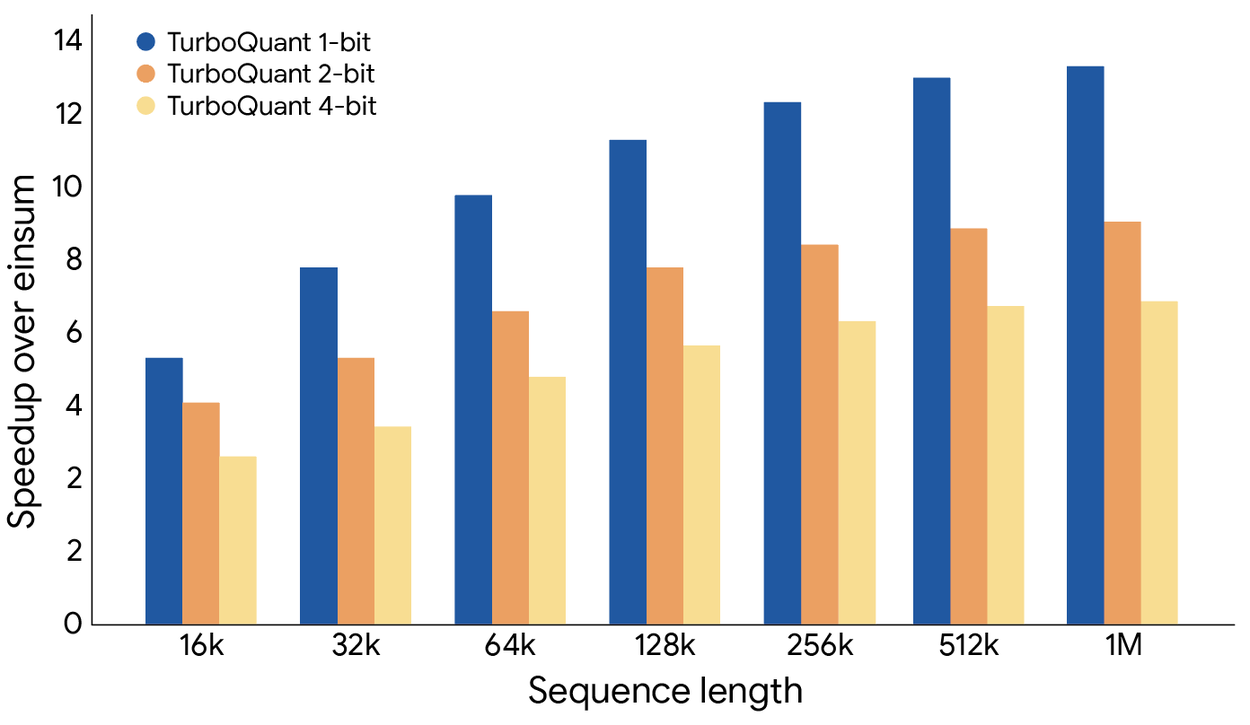
TurboQuant illustrates a substantial performance increase in computing attention logits within the key-value cache across various bit-width levels, measured relative to the highly optimized JAX baseline.
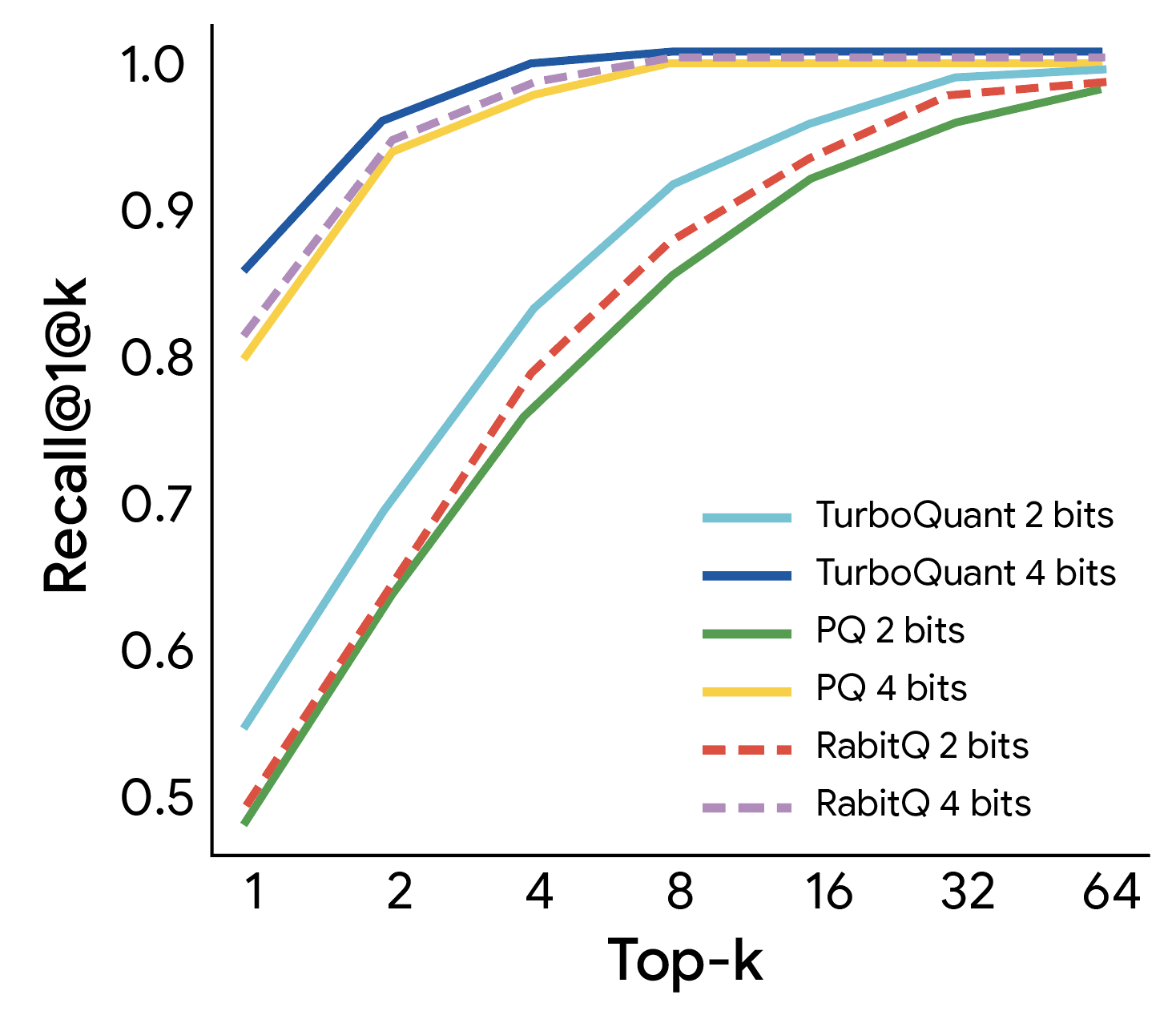
This makes it ideal for supporting use cases like vector search where it dramatically speeds up index building process. We evaluated TurboQuant's efficacy in high-dimensional vector search against state-of-the-art methods (PQ and RabbiQ) using the 1@k recall ratio, which measures how frequently the algorithm captures the true top inner product result within its top-k approximations. TurboQuant consistently achieves superior recall ratios compared to baseline methods, despite those baselines utilizing inefficient large codebooks and dataset-specific tuning (figure below). This confirms TurboQuant's robustness and efficiency for high-dimensional search tasks.
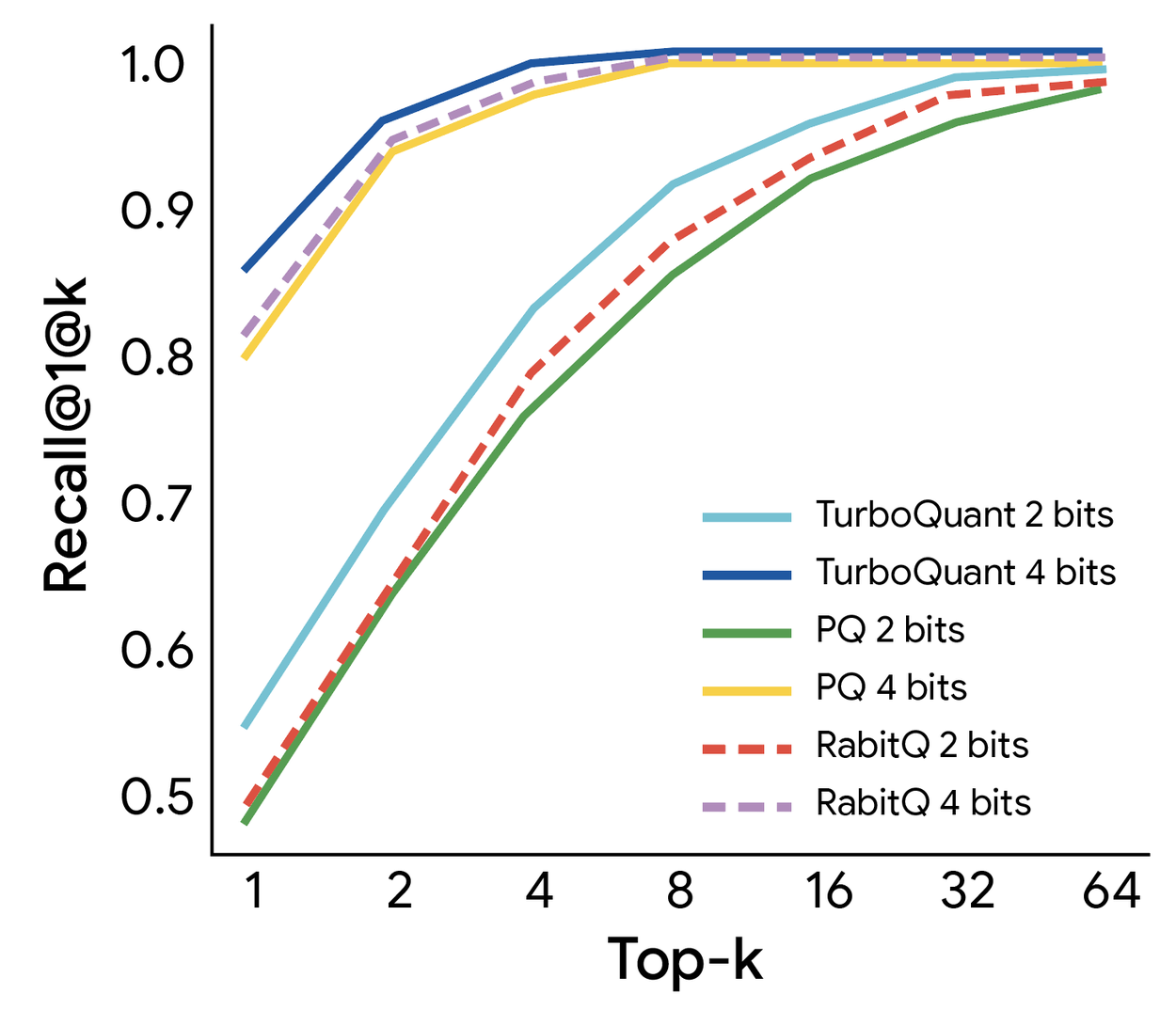
TurboQuant demonstrates robust retrieval performance, achieving the optimal 1@k recall ratio on the GloVe dataset (d=200) relative to various state-of-the-art quantization baselines.
TurboQuant demonstrates a transformative shift in high-dimensional search. By setting a new benchmark for achievable speed, it delivers near-optimal distortion rates in a data-oblivious manner. This allows our nearest neighbor engines to operate with the efficiency of a 3-bit system while maintaining the precision of much heavier models. See the paper for more details.
Looking ahead
TurboQuant, QJL, and PolarQuant are more than just practical engineering solutions; they’re fundamental algorithmic contributions backed by strong theoretical proofs. These methods don't just work well in real-world applications; they are provably efficient and operate near theoretical lower bounds. This rigorous foundation is what makes them robust and trustworthy for critical, large-scale systems.
While a major application is solving the key-value cache bottleneck in models like Gemini, the impact of efficient, online vector quantization extends even further. For example, modern search is evolving beyond just keywords to understand intent and meaning. This requires vector search — the ability to find the "nearest" or most semantically similar items in a database of billions of vectors.
Techniques like TurboQuant are critical for this mission. They allow for building and querying large vector indices with minimal memory, near-zero preprocessing time, and state-of-the-art accuracy. This makes semantic search at Google's scale faster and more efficient. As AI becomes more integrated into all products, from LLMs to semantic search, this work in fundamental vector quantization will be more critical than ever.
Acknowledgements
This line of research was conducted in collaboration with Praneeth Kacham, researcher at Google; Insu Han, Assistant Professor at KAIST; and Majid Daliri, PhD student at NYU; Lars Gottesbüren, researcher at Google; and Rajesh Jayaram, researcher at Google.
Quick links
Other posts of interest
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing