Towards Reliability in Deep Learning Systems
July 14, 2022
Posted by Dustin Tran and Balaji Lakshminarayanan, Research Scientists, Google Research
Quick links
Deep learning models have made impressive progress in vision, language, and other modalities, particularly with the rise of large-scale pre-training. Such models are most accurate when applied to test data drawn from the same distribution as their training set. However, in practice, the data confronting models in real-world settings rarely match the training distribution. In addition, the models may not be well-suited for applications where predictive performance is only part of the equation. For models to be reliable in deployment, they must be able to accommodate shifts in data distribution and make useful decisions in a broad array of scenarios.
In “Plex: Towards Reliability Using Pre-trained Large Model Extensions”, we present a framework for reliable deep learning as a new perspective about a model’s abilities; this includes a number of concrete tasks and datasets for stress-testing model reliability. We also introduce Plex, a set of pre-trained large model extensions that can be applied to many different architectures. We illustrate the efficacy of Plex in the vision and language domains by applying these extensions to the current state-of-the-art Vision Transformer and T5 models, which results in significant improvement in their reliability. We are also open-sourcing the code to encourage further research into this approach.
 |
| Uncertainty — Dog vs. Cat classifier: Plex can say “I don’t know” for inputs that are neither cat nor dog. Robust Generalization — A naïve model is sensitive to spurious correlations (“destination”), whereas Plex is robust. Adaptation — Plex can actively choose the data from which it learns to improve performance more quickly. |
Framework for Reliability
First, we explore how to understand the reliability of a model in novel scenarios. We posit three general categories of requirements for reliable machine learning (ML) systems: (1) they should accurately report uncertainty about their predictions (“know what they don’t know”); (2) they should generalize robustly to new scenarios (distribution shift); and (3) they should be able to efficiently adapt to new data (adaptation). Importantly, a reliable model should aim to do well in all of these areas simultaneously out-of-the-box, without requiring any customization for individual tasks.
- Uncertainty reflects the imperfect or unknown information that makes it difficult for a model to make accurate predictions. Predictive uncertainty quantification allows a model to compute optimal decisions and helps practitioners recognize when to trust the model’s predictions, thereby enabling graceful failures when the model is likely to be wrong.
- Robust Generalization involves an estimate or forecast about an unseen event. We investigate four types of out-of-distribution data: covariate shift (when the input distribution changes between training and application and the output distribution is unchanged), semantic (or class) shift, label uncertainty, and subpopulation shift.
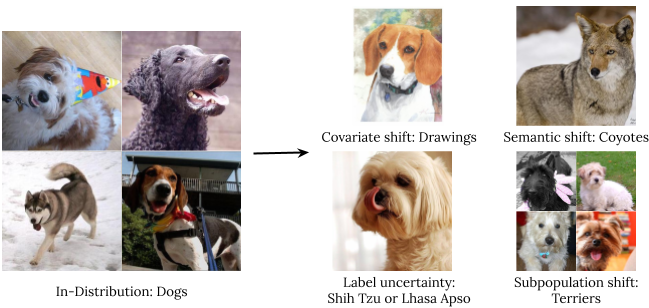
Types of distribution shift using an illustration of ImageNet dogs. - Adaptation refers to probing the model’s abilities over the course of its learning process. Benchmarks typically evaluate on static datasets with pre-defined train-test splits. However, in many applications, we are interested in models that can quickly adapt to new datasets and efficiently learn with as few labeled examples as possible.

 |
| Reliability framework. We propose to simultaneously stress-test the “out-of-the-box” model performance (i.e., the predictive distribution) across uncertainty, robust generalization, and adaptation benchmarks, without any customization for individual tasks. |
We apply 10 types of tasks to capture the three reliability areas — uncertainty, robust generalization, and adaptation — and to ensure that the tasks measure a diverse set of desirable properties in each area. Together the tasks comprise 40 downstream datasets across vision and natural language modalities: 14 datasets for fine-tuning (including few-shot and active learning–based adaptation) and 26 datasets for out-of-distribution evaluation.
Plex: Pre-trained Large Model Extensions for Vision and Language
To improve reliability, we develop ViT-Plex and T5-Plex, building on large pre-trained models for vision (ViT) and language (T5), respectively. A key feature of Plex is more efficient ensembling based on submodels that each make a prediction that is then aggregated. In addition, Plex swaps each architecture’s linear last layer with a Gaussian process or heteroscedastic layer to better represent predictive uncertainty. These ideas were found to work very well for models trained from scratch at the ImageNet scale. We train the models with varying sizes up to 325 million parameters for vision (ViT-Plex L) and 1 billion parameters for language (T5-Plex L) and pre-training dataset sizes up to 4 billion examples.
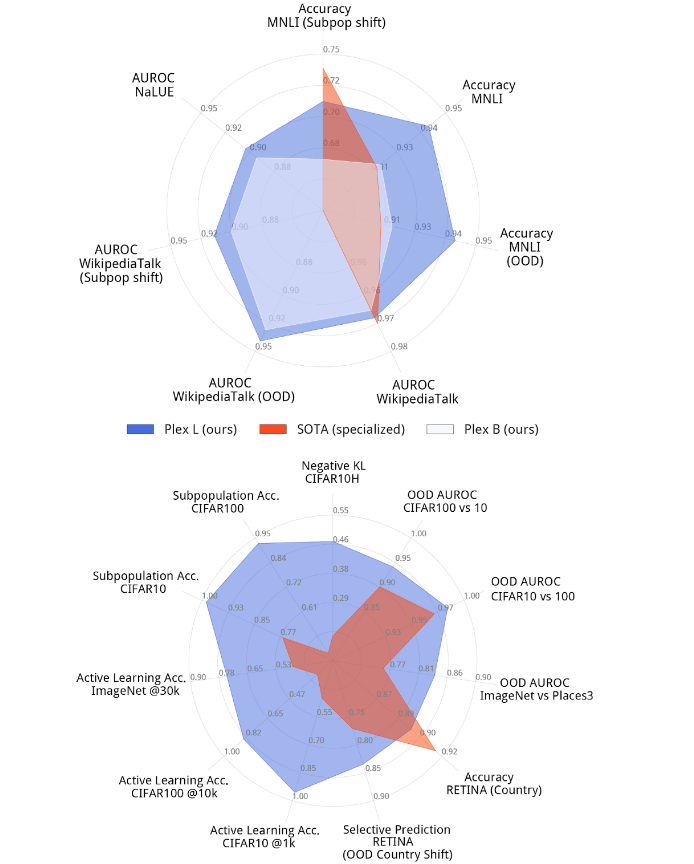
The following figure illustrates Plex’s performance on a select set of tasks compared to the existing state-of-the-art. The top-performing model for each task is usually a specialized model that is highly optimized for that problem. Plex achieves new state-of-the-art on many of the 40 datasets. Importantly, Plex achieves strong performance across all tasks using the out-of-the-box model output without requiring any custom designing or tuning for each task.
 |
| The largest T5-Plex (top) and ViT-Plex (bottom) models evaluated on a highlighted set of reliability tasks compared to specialized state-of-the-art models. The spokes display different tasks, quantifying metric performance on various datasets. |
Plex in Action for Different Reliability Tasks
We highlight Plex’s reliability on select tasks below.
Open Set Recognition
We show Plex’s output in the case where the model must defer prediction because the input is one that the model does not support. This task is known as open set recognition. Here, predictive performance is part of a larger decision-making scenario where the model may abstain from making certain predictions. In the following figure, we show structured open set recognition: Plex returns multiple outputs and signals the specific part of the output about which the model is uncertain and is likely out-of-distribution.
 |
| Structured open set recognition enables the model to provide nuanced clarifications. Here, T5-Plex L can recognize fine-grained out-of-distribution cases where the request’s vertical (i.e., coarse-level domain of service, such as banking, media, productivity, etc.) and domain are supported but the intent is not. |
Label Uncertainty
In real-world datasets, there is often inherent ambiguity behind the ground truth label for each input. For example, this may arise due to human rater ambiguity for a given image. In this case, we’d like the model to capture the full distribution of human perceptual uncertainty. We showcase Plex below on examples from an ImageNet variant we constructed that provides a ground truth label distribution.
 |
| Plex for label uncertainty. Using a dataset we construct called ImageNet ReaL-H, ViT-Plex L demonstrates the ability to capture the inherent ambiguity (probability distribution) of image labels. |
Active Learning
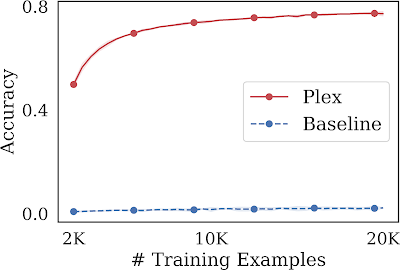
We examine a large model’s ability to not only learn over a fixed set of data points, but also participate in knowing which data points to learn from in the first place. One such task is known as active learning, where at each training step, the model selects promising inputs among a pool of unlabeled data points on which to train. This procedure assesses an ML model’s label efficiency, where label annotations may be scarce, and so we would like to maximize performance while minimizing the number of labeled data points used. Plex achieves a significant performance improvement over the same model architecture without pre-training. In addition, even with fewer training examples, it also outperforms the state-of-the-art pre-trained method, BASE, which reaches 63% accuracy at 100K examples.
 |
| Active learning on ImageNet1K. ViT-Plex L is highly label efficient compared to a baseline that doesn’t leverage pre-training. We also find that active learning’s data acquisition strategy is more effective than uniformly selecting data points at random. |
Learn more
Check out our paper here and an upcoming contributed talk about the work at the ICML 2022 pre-training workshop on July 23, 2022. To encourage further research in this direction, we are open-sourcing all code for training and evaluation as part of Uncertainty Baselines. We also provide a demo that shows how to use a ViT-Plex model checkpoint. Layer and method implementations use Edward2.
Acknowledgements
We thank all the co-authors for contributing to the project and paper, including Andreas Kirsch, Clara Huiyi Hu, Du Phan, D. Sculley, Honglin Yuan, Jasper Snoek, Jeremiah Liu, Jie Ren, Joost van Amersfoort, Karan Singhal, Kehang Han, Kelly Buchanan, Kevin Murphy, Mark Collier, Mike Dusenberry, Neil Band, Nithum Thain, Rodolphe Jenatton, Tim G. J. Rudner, Yarin Gal, Zachary Nado, Zelda Mariet, Zi Wang, and Zoubin Ghahramani. We also thank Anusha Ramesh, Ben Adlam, Dilip Krishnan, Ed Chi, Neil Houlsby, Rif A. Saurous, and Sharat Chikkerur for their helpful feedback, and Tom Small and Ajay Nainani for helping with visualizations.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence