Towards a unified model for predicting human responses to diverse visual content
November 12, 2024
Junfeng He, Research Scientist, Google Research, and Peizhao Li, Research Scientist, Google
We present a unified model for understanding and predicting human attention and responses to diverse visual content, including images, UIs, webpages, etc. We show that our single unified model can perform better than or comparably to many existing baseline methods, which are usually dedicated to one or two tasks and datasets.
Quick links
Human attention is intricately linked with and shapes decision-making behavior, such as subjective preferences and ratings. Yet prior research has often studied these in isolation. For example, there’s a large body of work on predictive models of human attention, which are known to be useful for various applications, ranging from reducing visual distraction to optimizing interaction designs and faster (progressive) rendering of very large images. Additionally, there’s a separate body of work on models of explicit, later-stage decision-making behavior such as subjective preferences and aesthetic quality.
Recently, we began to focus our research on whether we can simultaneously predict different types of human interaction and feedback to unlock exciting human-centric applications. In our previous blogpost we demonstrated how a single machine learning (ML) model can predict rich human feedback on generated images (e.g., text-image misalignment, aesthetic quality, problematic regions with artifacts along with an explanation), and use those predictions to evaluate and improve image generation results.
Following up on this effort, in “UniAR: A Unified model for predicting human Attention and Responses on diverse visual content”, we introduce a multimodal model that attempts to unify various tasks of human visual behavior. We find its performance to be comparable to the best-performing domain- and task-specific models. Inspired by the recent progress in large vision-language models, we adopt a multimodal encoder-decoder transformer model to unify the various human behavior modeling tasks.
This model enables a wide variety of applications. For example, it can provide near-instant feedback on the effectiveness of UIs and visual content, enabling designers and content-creation models to optimize their work for human-centric improvements. To the best of our knowledge, this represents the first attempt to unify modeling of both implicit, early-perceptual behavior of what catches people’s attention and explicit, later-stage decision-making on subjective preferences across UIs, including real images, mobile web pages, mobile UIs, and more.
UniAR is a unified approach to predictive modeling of both implicit and explicit human responses on diverse visual content.
Model architecture
The model uses two types of inputs: images and text prompts. Its architecture consists of a vision transformer model for image encoding, a word embedding layer to embed text tokens, and a T5 transformer encoder to fuse image and text representations.
It also has three separate predictors:
- a heatmap predictor for attention (i.e., probability distribution over gaze or where people look) and visual importance (what people think is important),
- a scanpath predictor for the sequence of viewing,
- and a rating predictor for quality (aesthetic) scores of images or webpages.
The text prompt encodes relevant information about the input domain (e.g., natural image, graphic design, webpages), the behavioral task (e.g., predict interaction heatmaps, sequence-of-viewing, aesthetic score), and other task-related information, such as viewing scenarios (e.g., free-viewing, object-searching), target object names, or questions to be answered (e.g., “What event is the infographics about?” or “What is the relationship between the people in the image?”).
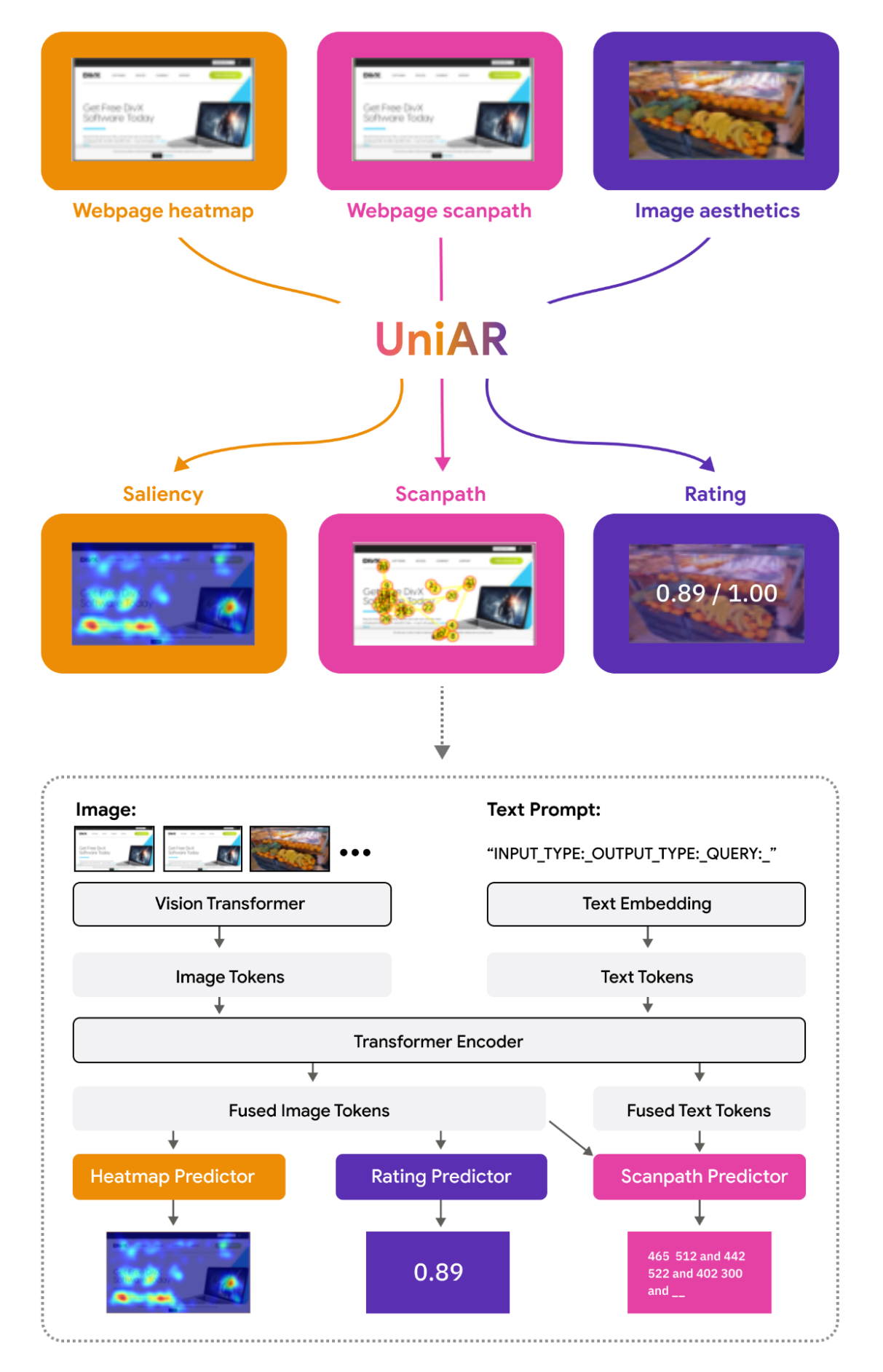
Overview of the UniAR model.
We used both a large-scale natural images dataset (WebLI) and a web and mobile UI images dataset to pre-train the model and ensure that the model can generalize to multiple domains. Captioning tasks for images and UI screen regions are used for pre-training, as in the original papers for the datasets mentioned. For sequence tasks involving prediction of gaze or interaction coordinates, such as scanpath prediction, we also added a pre-training task to predict the coordinates of the bounding box of relevant items, given a text snippet and screenshot (for webpage and mobile interface data).
After pre-training, we further used 11 public datasets to train our model. The datasets included those for natural images (ranging in size from 480 to 1,680 pixels), graphic design, and mobile user interfaces. During training, we randomly sampled from all training datasets with an equal sampling rate. The sample size ranged from 121 to 21,622. Dataset details can be found in the paper.
We integrated specific task instructions into the model via text prompts to enhance the model’s ability to generalize across a variety of visual content and scenarios.
Results
We compare the models using recent benchmarks via typical evaluation metrics: Pearson’s correlation coefficient (CC) to measure the linear relationship in all pixel values between the predicted and ground-truth saliency heatmaps; KL-divergence (KLD) to measure the distribution discrepancy between the predicted heatmap and ground-truth heatmap, with the prediction used as the target distribution; area under ROC curve (AUC) in the variant from Judd et al. [35], treating the heatmap prediction as binary classification with various thresholds; Normalized Scanpath Saliency (NSS) for the average saliency strength (pixel values in the predicted heatmap) at all ground-truth fixation locations; and Spearman’s rank correlation coefficient (SRCC) and Pearson linear correlation coefficient (PLCC), respectively, to quantify the quality of predicted ratings.
In heatmap prediction (see table below), UniAR achieved the best performance compared to strong baselines and outperformed previous best-performance benchmarks in many cases across seven public benchmarks. Notably, it achieved the best result in 17 of all 27 metrics (and ranked among the top two for 22 of 27 metrics) and outperformed previous benchmarks across metrics in the mobile interface and graphic design datasets.
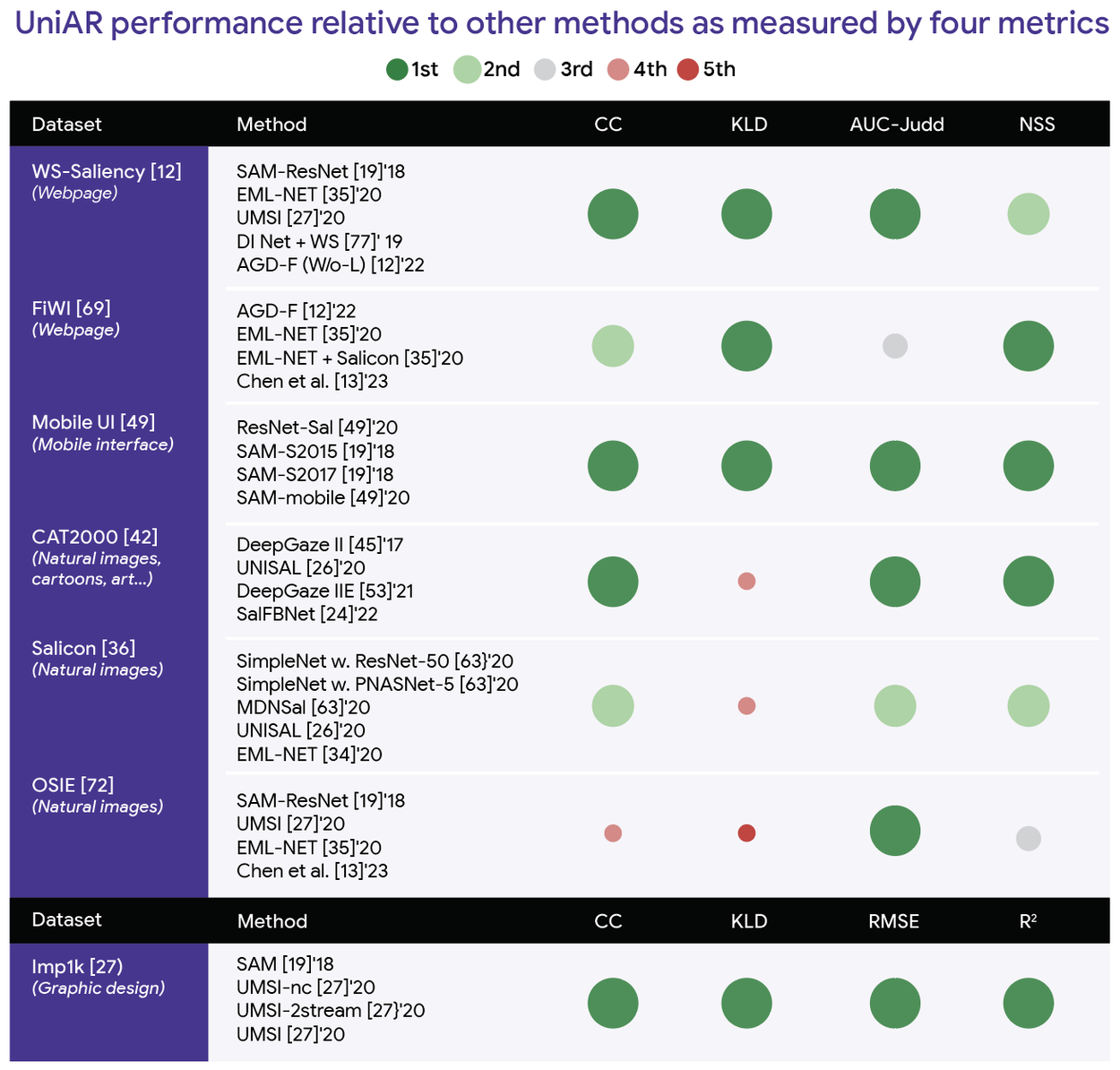
UniAR performance relative to other methods across four metrics for predicting heatmaps of attention and visual importance.
For the preference/rating prediction task (see following figure), our model achieved the best results for PLCC metrics on both datasets.
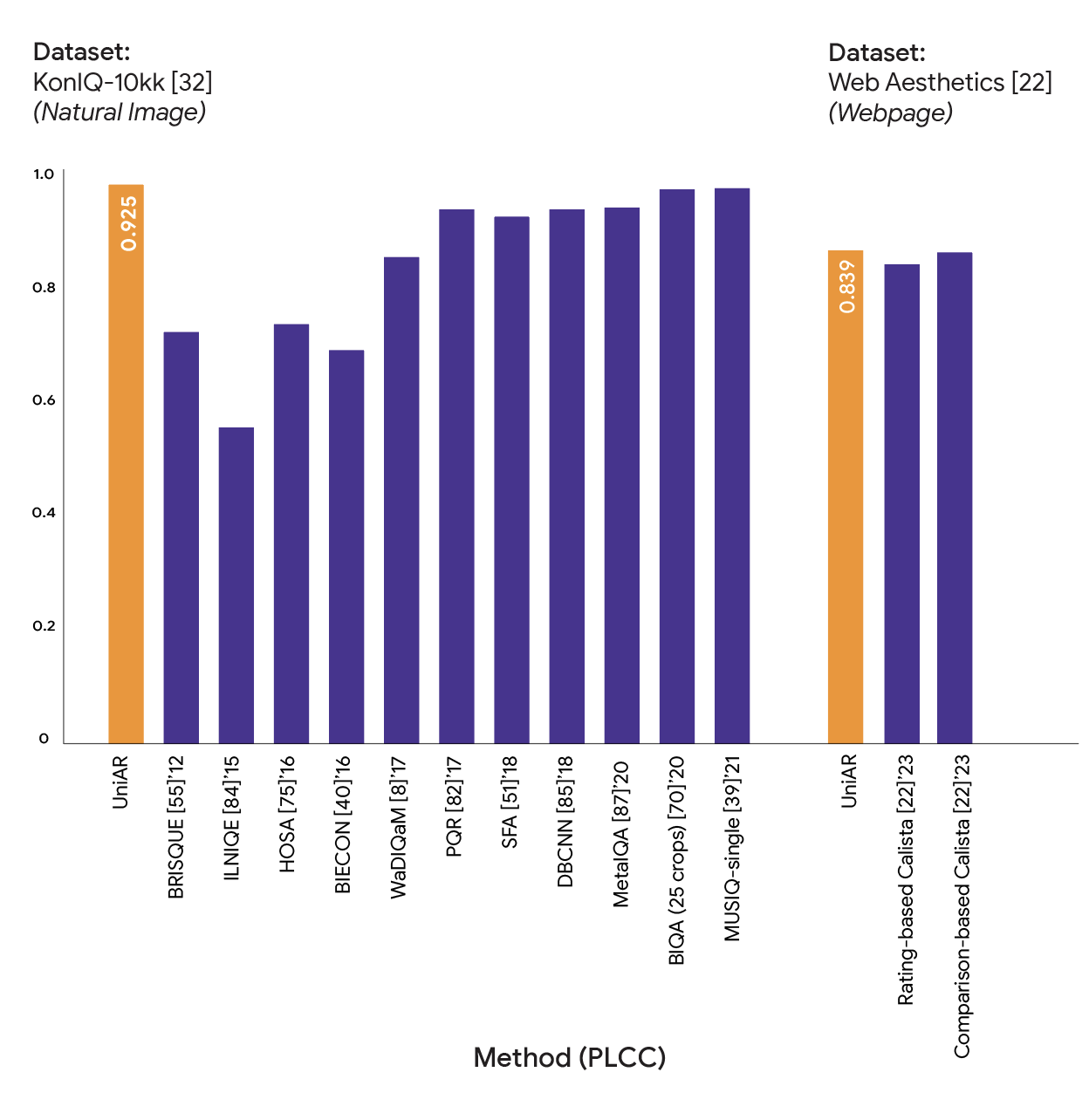
Subjective rating prediction results on natural image dataset KonIQ-10k and webpage dataset Web Aesthetics.
For the scanpath prediction task, our model performed comparably to baselines in both datasets and outperformed baselines on all the metrics on the datasets, achieving the best result in four of the five metrics.
For transferring knowledge between tasks, where we tested the models’ ability to generalize and transfer to unseen tasks and domain combinations, the model showed promising results under some transfer settings (e.g., predicting scanpaths on webpages despite not having seen that task and domain combination during training).
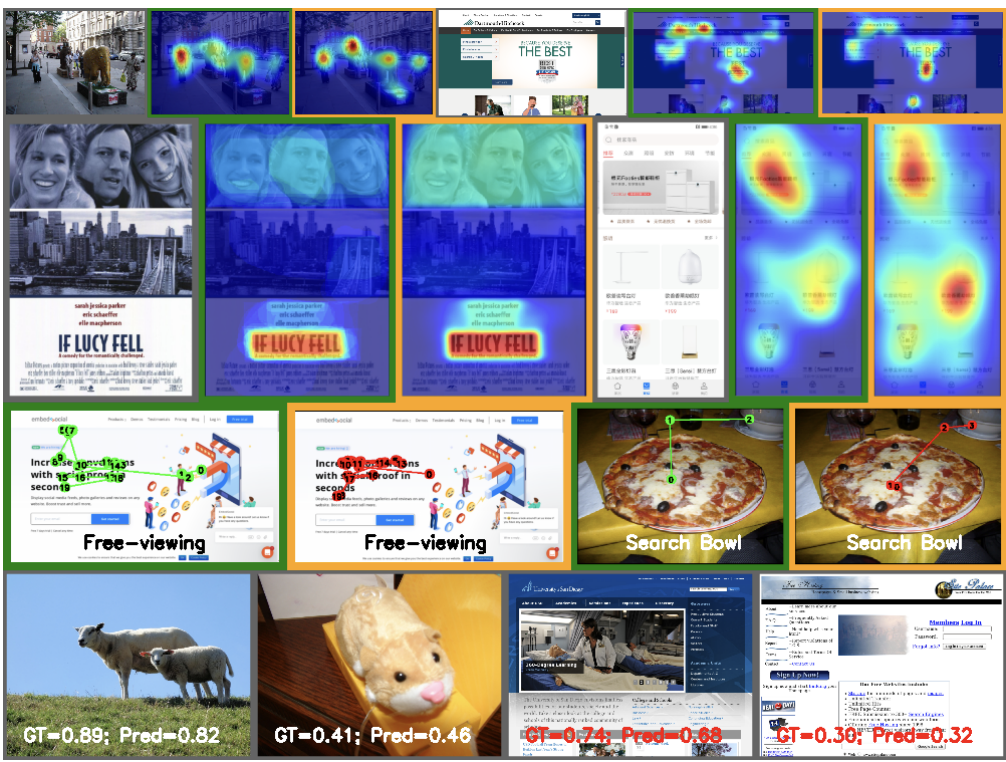
Below we show examples of UniAR’s predictions across different tasks and domains.
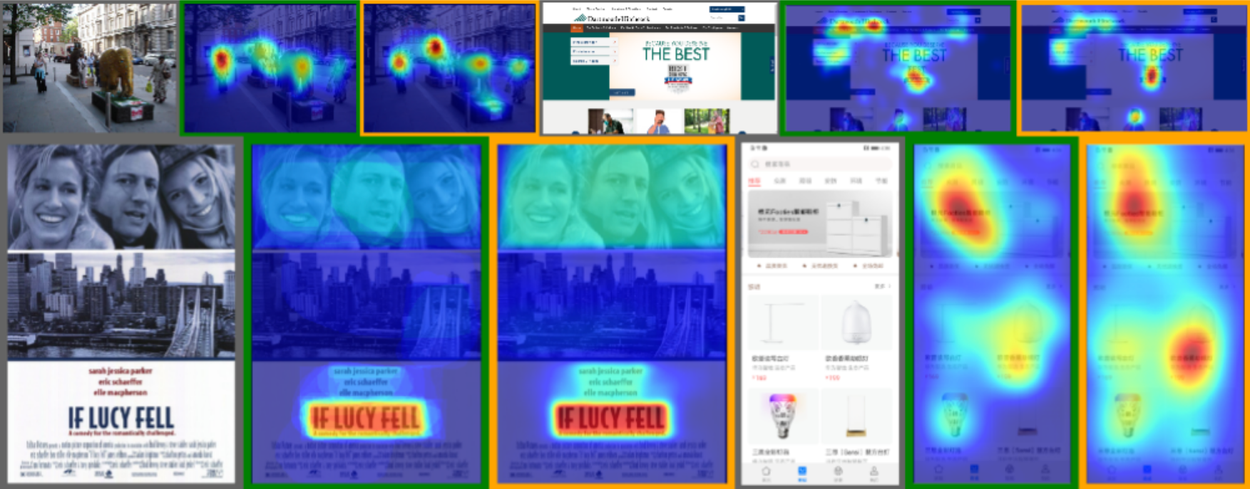
First row: Attention heatmap prediction on natural images (Salicon; left) and webpages (WS-Saliency; right). Second row: Importance heatmap on graphic designs (Imp1k; left), and saliency heatmap on Mobile UI (right). Images with green borders are ground-truth, while images with orange borders are UniAR’s predictions.

Scanpath-sequence during free-viewing of webpages (WS-Scanpath; left) and object-searching within images (COCO-Search18; right). Images with green borders are ground truth, while images with orange borders are UniAR’s predictions.

Aesthetics/quality rating prediction (“Pred”) compared to ground truth (“GT”) for natural images (Koniq-10k; left) and webpages (Web Aesthetics; right).
Limitations
When modeling human preferences and behavior, it is important to acknowledge and carefully consider the limitations of such models:
- Model prediction as a guide: To ensure that model usage remains socially beneficial and responsible, the model predictions are intended as a reference for human preference and not as a replacement.
- Fine-tuning for more targeted predictions: To model the diversity of people’s individual preferences, we propose the creation of fine-tuned model variants based on user groups (e.g., demographics), as part of future work. Since human preferences evolve over time, keeping the model up-to-date with more recent data will allow it to reflect current preferences.
- Expanding datasets: Our model is based on existing, publicly available datasets, including larger crowdsourced datasets. While this makes for a good proof-of-concept and first step, in the future we hope to expand to incorporate data from a wider variety of demographics, including annotators with low vision who interact with content through assistive technologies.
Conclusion
We developed a unified, multimodal model, UniAR, to predict different types of implicit and explicit human responses and feedback to visual content—from attention to subjective preferences—using image-text prompts. Trained on diverse public datasets across natural images, graphic designs, webpages and UIs, this model effectively predicts human attention heatmaps, scanpath sequences, and subjective preferences, and achieves the best performance across multiple benchmarks and tasks. We plan to explore more human behavior tasks and domains in future work.
Acknowledgements
We would like to thank all co-authors of this paper: Gang Li, Rachit Bhargava, Shaolei Shen, Nachiappan Valliappan, Youwei Liang, Hongxiang Gu, Venky Ramachandran, Golnaz Farhadi, Yang Li, Kai J Kohlhoff, and Vidhya Navalpakkam. Moreover, we would also like to thank Mark Simborg, Kimberly Schwede, Tom Small and Tim Fujita for helping prepare this blogpost.
Quick links






