Time series foundation models can be few-shot learners
September 23, 2025
Rajat Sen, Research Scientist, and Yichen Zhou, Software Engineer, Google Research
We present a novel approach to time-series forecasting that uses continued pre-training to teach a time-series foundation model to adapt to in-context examples at inference time.
Quick links
Time-series forecasting is essential for modern businesses, helping them predict everything from inventory needs to energy demands. Traditionally, this has involved building a separate, specialized model for each task — a process that is slow and requires significant expertise.
The emergence of zero-shot learning offered a solution. Our previous model, TimesFM, was a zero-shot, pre-trained foundation model that could accurately forecast without task-specific training. But what if a few examples could make the forecast even better? For instance, forecasting highway traffic would be more accurate if the model could consider data from other nearby highways or from the same highway a few weeks ago. The standard solution, supervised fine-tuning, which uses curated data to fine-tune an existing model, reintroduces the complexity one hopes to avoid with zero-shot learning.
In our new work, "In-Context Fine-Tuning for Time-Series Foundation Models", presented at ICML 2025, we introduce a novel approach that transforms TimesFM into a few-shot learner. This method uses continued pre-training to teach the model how to learn from a handful of examples at inference time. The result is a powerful new capability that matches the performance of supervised fine-tuning without requiring additional complex training from the user.

Similar to few-shot prompting of an LLM (left), a time-series foundation model should support few-shot prompting with an arbitrary number of related in-context time series examples (right). The orange box encloses the inputs to the models.
Redesigning the model
TimesFM is a patched decoder that tokenizes every 32 contiguous timepoints (a patch) as an input token and applies a transformer stack on top of the sequence of input tokens to generate the output tokens. It then applies a shared multilayer perceptron (MLP) to translate each output token back to a time series of 128 timepoints.
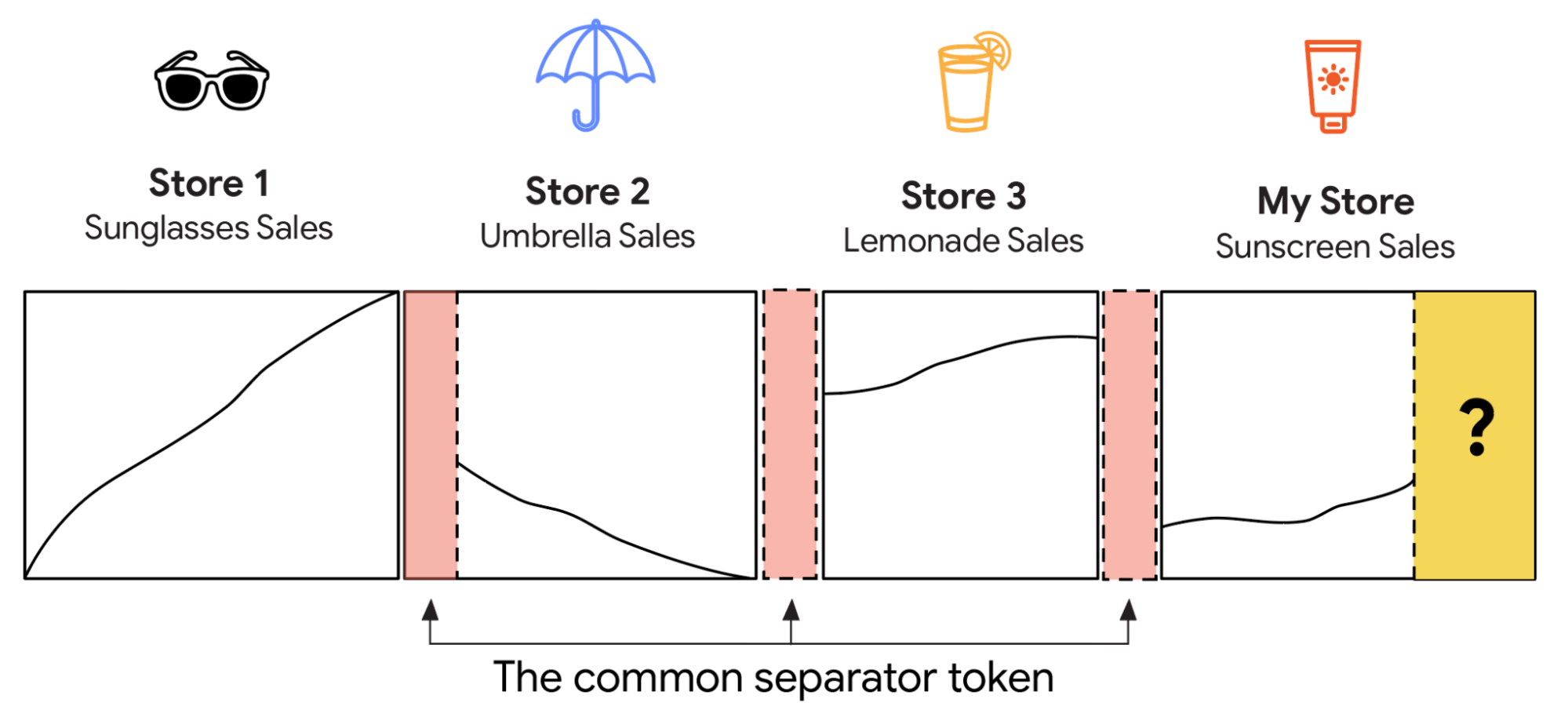
To create TimesFM-ICF (In-Context Fine-tuning), we start with the base TimesFM model and continue the pre-training with new context: the forecast history plus all in-context examples. The first step is to make sure the model doesn’t confuse or conflate the forecasting history and the in-context examples. Imagine you're giving the model a list of numbers that represent a few different things, maybe sunglasses sales figures from one store, then umbrella sales figures from another. If you just merge all those numbers together, the model might get confused, thinking it's one continuous stream of data. For example, if the first store’s sales were going up and the second store’s sales were going down, the model might incorrectly see it as a single up-and-down pattern, rather than two separate, simple trends.
To fix this, we put a special, learnable “common separator token” — like a digital "stop sign" or a "new paragraph" symbol — after each set of numbers. With these separators in place, as soon as the model attends to the separator token of an example it has seen before, it won't mix it up with the data it's currently trying to predict. This theoretically allows the model to learn from patterns in those past examples and apply that knowledge to the current forecast. For instance, the model could learn that "all the store sales are showing consistent, directional trends lately, so I should predict an upward trend for my new store’s sunscreen sales."
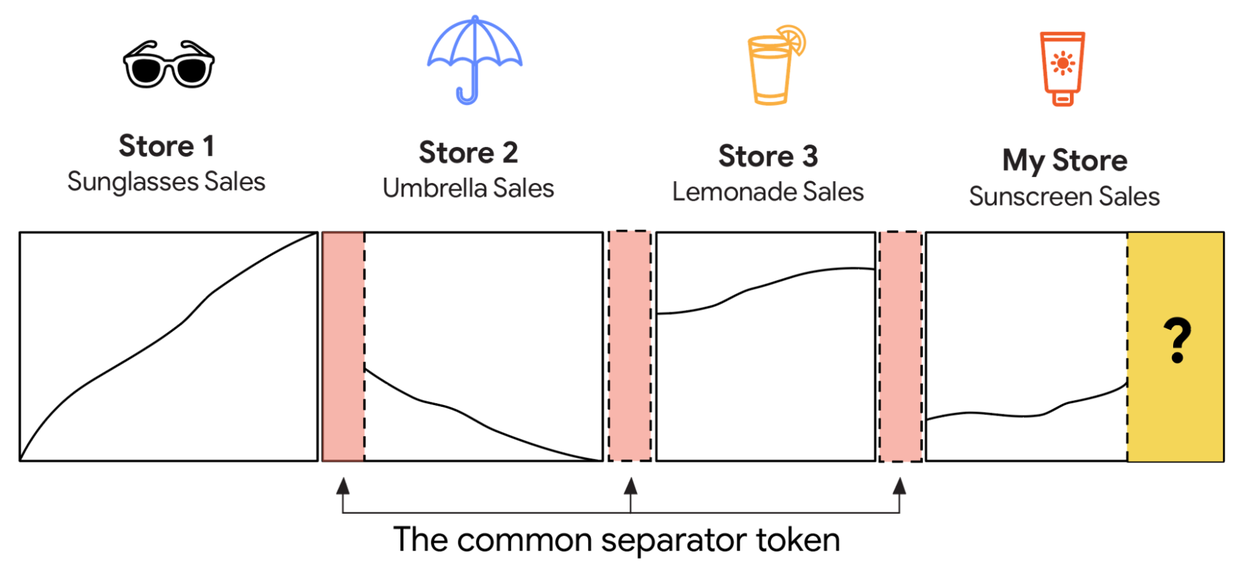
Concatenating in-context examples without separators could confuse the model — multiple monotonic trends might look like a jagged, continuous pattern if concatenated naïvely.
Since the separator tokens and the attention to them are new for TimesFM, our second step involves continuing the pre-training of the base TimesFM model to teach it about the new introductions. The recipe here is actually straightforward: we created a new dataset that includes both in-context examples and separator tokens, and we applied standard decoder-only next-token prediction training. Inputs are passed to the MLP layer, which generates tokens. These are passed to a causal self attention (CSA) layer that "attends to" information from previous tokens in the sequence, a step that's crucial in tasks like time-series forecasting as it prevents the model from looking into the future. The CSA then feeds into a feed-forward network (FFN). We repeat CSA and FFN multiple times (i.e., the stacked transformers) before connecting the result to the output MLP layer.
TimesFM-ICF employs the decoder-only architecture for time-series forecasting with in-context examples. A special common separator token is introduced to disambiguate between the in-context examples and the task history.
Testing the model
We evaluated TimesFM-ICF on 23 datasets that the model had never seen during any phase of its training. Each dataset in this benchmark has multiple time series. When we forecast a time series, we start with its immediate history, then sample sequences from its full history and the histories of other time series in the same dataset as in-context examples. This ensures the in-context examples are relevant and there is no leakage.
The chart below shows the geometric mean (GM) aggregation of the mean absolute scaled errors (MASE) normalized by a naïve repeat of the last seasonal pattern. We focus on two baselines here:
- TimesFM (Base), which is the pre-trained model from which we started.
- TimesFM-FT is TimesFM (Base) with supervised fine-tuning using the train split per dataset and then evaluated on the corresponding test split. This is a strong baseline that reflects the previous best practice for domain adaptation.
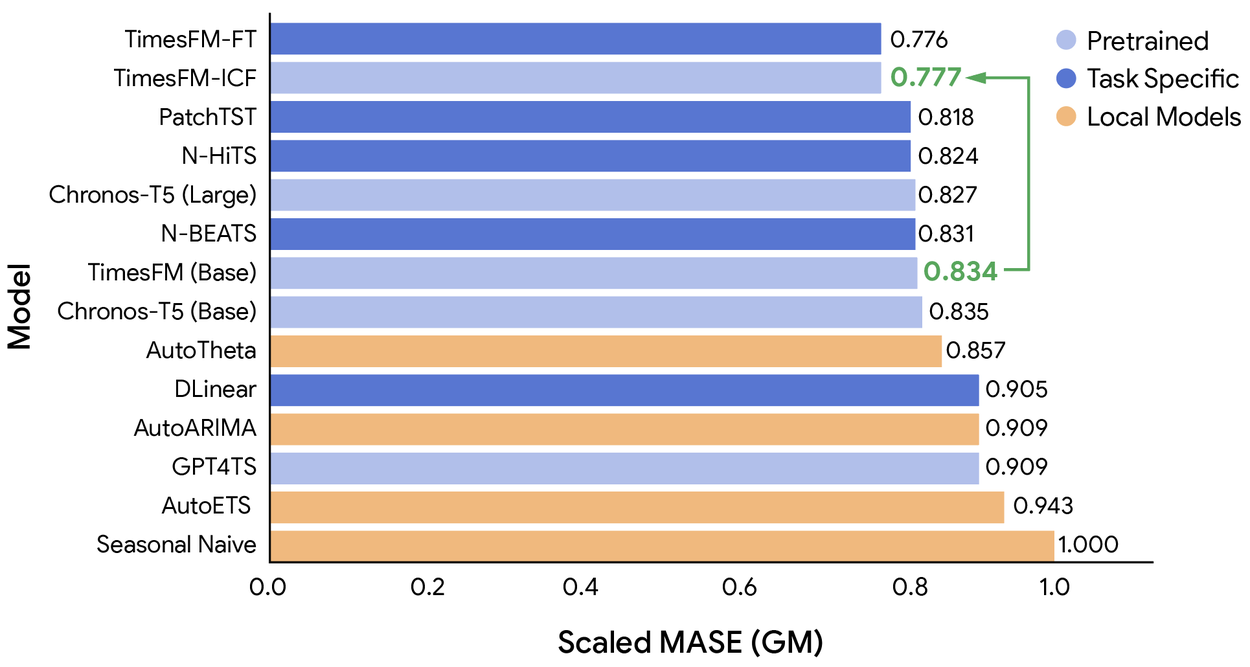
TimesFM-ICF improves the performance of TimesFM (Base) over many task-specific models and achieves the same performance as that of TimesFM-FT, which is a version of TimesFM fine-tuned for each specific dataset, respectively.
TimesFM-ICF is 6.8% more accurate than TimesFM (Base). What’s more surprising and inspiring is that it matches the performance of TimesFM-FT without the hassle of running supervised fine-tuning.
Besides the accuracy improvement, TimesFM-ICF also demonstrates other desirable properties. For example, it is consistent with our expectation that with more in-context examples, a model will make more accurate forecasts at the cost of longer inference time. In addition, TimesFM-ICF shows better utilization of its context when compared to a purely long-context model that does not have the ability to work with in-context examples.
The future: More accessible and powerful forecasting
This new approach has significant real-world applications because it allows businesses to deploy a more robust and adaptable single, powerful forecasting model. Instead of launching a full ML project for new tasks, like forecasting demand for a new product, they can simply feed the model a few new relevant examples. This immediately provides state-of-the-art, specialized forecasts, dramatically cutting costs, accelerating decision-making and innovation, and democratizing access to high-end forecasting.
We're excited by this research's future, particularly developing automated strategies for selecting the most relevant in-context examples. By making foundation models more intelligent and adaptable, we empower more users to make better, data-driven decisions.
Acknowledgements
This research was led by then-student researcher Matthew Faw in collaboration with Google Research colleagues Abhimanyu Das and Ivan Kuznetsov. This blog post was brought to life with the tremendous help from editors Mark Simborg and Kimberly Schwede.
-
Labels:
- Generative AI
- Machine Intelligence
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence

