The Visual Task Adaptation Benchmark
November 6, 2019
Posted by Neil Houlsby, Research Scientist and Xiaohua Zhai, Research Engineer, Google Research, Zürich
Quick links
Deep learning has revolutionized computer vision, with state-of-the-art deep networks learning useful representations directly from raw pixels, leading to unprecedented performance on many vision tasks. However, learning these representations from scratch typically requires hundreds of thousands of training examples. This burden can be reduced by using pre-trained representations, which have become widely available through services such as TensorFlow Hub (TF Hub) and PyTorch Hub. But their ubiquity can itself be a hindrance. For example, for the task of extracting features from images, there can be over 100 models from which to choose. It is hard to know which methods provide the best representations, since different sub-fields use different evaluation protocols, which do not always reflect the final performance on new tasks.
The overarching goal of representation research is to learn representations a single time on large amounts of generic data without the need to train them from scratch for each task, thus reducing data requirements across all vision tasks. But in order to reach that goal, the research community must have a uniform benchmark against which existing and future methods can be evaluated.
To address this problem, we are releasing "The Visual Task Adaptation Benchmark" (VTAB, available on GitHub), a diverse, realistic, and challenging representation benchmark based on one principle — a better representation is one that yields better performance on unseen tasks, with limited in-domain data. Inspired by benchmarks that have driven progress in other fields of machine learning (ML), such as ImageNet for natural image classification, GLUE for Natural Language Processing, and Atari for reinforcement learning, VTAB follows similar guidelines: (i) minimal constraints on solutions to encourage creativity; (ii) a focus on practical considerations; and (iii) challenging tasks for evaluation.
The Benchmark
VTAB is an evaluation protocol designed to measure progress towards general and useful visual representations, and consists of a suite of evaluation vision tasks that a learning algorithm must solve. These algorithms may use pre-trained visual representations to assist them and must satisfy only two requirements:
- i) They must not be pre-trained on any of the data (labels or input images) used in the downstream evaluation tasks.
- ii) They must not contain hardcoded, task-specific, logic. Alternatively put, the evaluation tasks must be treated like a test set — unseen.
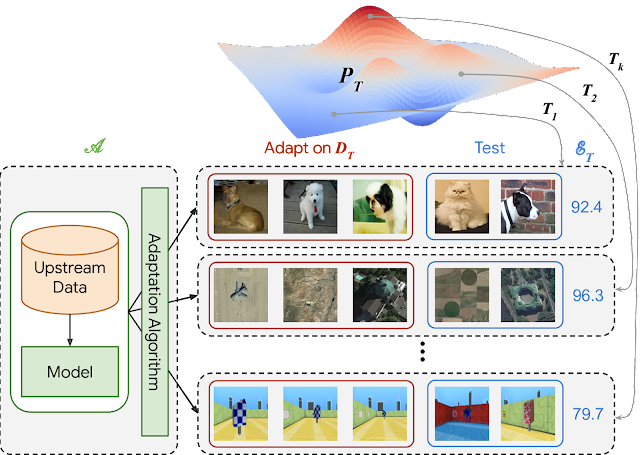
The VTAB protocol begins with the application of an algorithm (A) to a number of independent tasks, drawn from a broad distribution of vision problems. The algorithm may be pre-trained on upstream data to yield a model that contains visual representations, but it must also define an adaptation strategy that consumes a small training set for each downstream task and return a model that makes task-specific predictions. The algorithm’s final score is its average test score across tasks.
 |
| The VTAB protocol. Algorithm A is applied to many tasks T, drawn from a broad distribution of vision problems PT. In the example, pet classification, remote sensing, and maze localization are shown. |
While highly diverse, all of the tasks in VTAB share one common feature — people can solve them relatively easily after training on just a few examples. To assess algorithmic generalization to new tasks with limited data, performance is evaluated using only 1000 examples per task. Evaluation using the full dataset can be performed for comparison with previous publications.
Findings Using VTAB
We performed a large scale study testing a number of popular visual representation learning algorithms against VTAB. The study included generative models (GANs and VAEs), self-supervised models, semi-supervised models and supervised models. All of the algorithms were pre-trained on the ImageNet dataset. We also compared each of these approaches using no pre-trained representations, i.e., training “from-scratch”. The figure below summarizes the main pattern of results.
 |
| Performance of different classes of representation learning algorithms across different task groups: natural, specialized and structured. Each bar shows the average performance of all methods in that class across all tasks in the group. |
The best performing representation learning algorithm, of those we tested, is S4L, which combines both supervised and self-supervised pre-training losses. The figure below contrasts S4L with standard supervised ImageNet pre-training. S4L appears to improve performance particularly on the Structured tasks. However, representation learning yields a much smaller benefit over training from-scratch groups other than the Natural tasks, indicating that there is much progress required to attain a universal visual representation.
 | |
 | |
| Top: Performance of S4L versus from-scratch training. Each bar corresponds to a task. Positive-valued bars indicate tasks where S4L outperforms from-scratch. Negative bars indicate that from-scratch performed better. Bottom: S4L versus Supervised training on ImageNet. Positive bars indicate that S4L performs better. The bar colour indicates the task group: Red=Natural, Green=Specialized, Blue=Structured. We can see that additional self-supervision tends to help on structured tasks beyond just using ImageNet labels. |
The code to run VTAB is available on GitHub, including the 19 evaluation datasets and exact data splits. Having a publicly available set of benchmarks ensures the reproducibility of results. Progress is tracked with the public leaderboard, and the models evaluated are uploaded to TF Hub for public use and reproduction. A shell script is provided to perform adaptation and evaluation on all the tasks, with a standardized evaluation protocol making VTAB readily accessible across the industry. Since VTAB can be executed on both TPU and GPU, it is highly efficient. One can obtain comparable results with a single NVIDIA Tesla P100 accelerator in a few hours.
The Visual Task Adaptation Benchmark has helped us better understand which visual representations generalize to the broad spectrum of vision tasks, and provides direction for future research. We hope these resources are useful in driving progress toward general and practical visual representations, and as a result, affords deep learning to the long tail of vision problems with limited labelled data.
Acknowledgements
The core team behind this work includes Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, Lucas Beyer, Olivier Bachem, Michael Tschannen, Marcin Michalski, Olivier Bousquet, and Sylvain Gelly.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯



