The Google Brain Team — Looking Back on 2017 (Part 1 of 2)
January 11, 2018
Posted by Jeff Dean, Google Senior Fellow, on behalf of the entire Google Brain Team
Quick links
The Google Brain team works to advance the state of the art in artificial intelligence by research and systems engineering, as one part of the overall Google AI effort. Last year we shared a summary of our work in 2016. Since then, we’ve continued to make progress on our long-term research agenda of making machines intelligent, and have collaborated with a number of teams across Google and Alphabet to use the results of our research to improve people’s lives. This first of two posts will highlight some of our work in 2017, including some of our basic research work, as well as updates on open source software, datasets, and new hardware for machine learning. In the second post we’ll dive into the research we do in specific domains where machine learning can have a large impact, such as healthcare, robotics, and some areas of basic science, as well as cover our work on creativity, fairness and inclusion and tell you a bit more about who we are.
Core Research
A significant focus of our team is pursuing research that advances our understanding and improves our ability to solve new problems in the field of machine learning. Below are several themes from our research last year.
AutoML
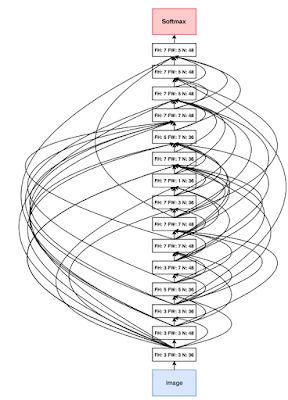
The goal of automating machine learning is to develop techniques for computers to solve new machine learning problems automatically, without the need for human machine learning experts to intervene on every new problem. If we’re ever going to have truly intelligent systems, this is a fundamental capability that we will need. We developed new approaches for designing neural network architectures using both reinforcement learning and evolutionary algorithms, scaled this work to state-of-the-art results on ImageNet classification and detection, and also showed how to learn new optimization algorithms and effective activation functions automatically. We are actively working with our Cloud AI team to bring this technology into the hands of Google customers, as well as continuing to push the research in many directions.
 |
| Convolutional architecture discovered by Neural Architecture Search |
 |
| Object detection with a network discovered by AutoML |
Another theme is on developing new techniques that improve the ability of our computing systems to understand and generate human speech, including our collaboration with the speech team at Google to develop a number of improvements for an end-to-end approach to speech recognition, which reduces the relative word error rate over Google’s production speech recognition system by 16%. One nice aspect of this work is that it required many separate threads of research to come together (which you can find on Arxiv: 1, 2, 3, 4, 5, 6, 7, 8, 9).
 |
| Components of the Listen-Attend-Spell end-to-end model for speech recognition |
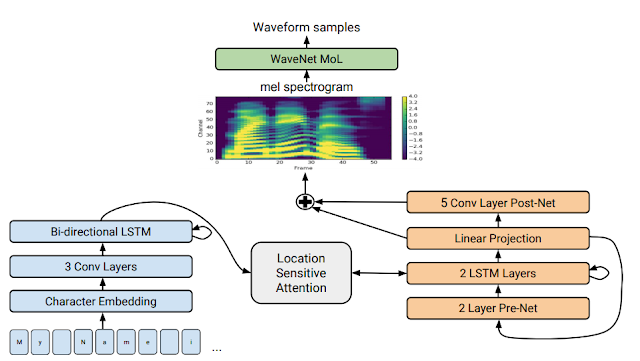 |
| Tacotron 2’s model architecture |
We continued to develop novel machine learning algorithms and approaches, including work on capsules (which explicitly look for agreement in activated features as a way of evaluating many different noisy hypotheses when performing visual tasks), sparsely-gated mixtures of experts (which enable very large models that are still computational efficient), hypernetworks (which use the weights of one model to generate weights for another model), new kinds of multi-modal models (which perform multi-task learning across audio, visual, and textual inputs in the same model), attention-based mechanisms (as an alternative to convolutional and recurrent models), symbolic and non-symbolic learned optimization methods, a technique to back-propagate through discrete variables, and a few new reinforcement learning algorithmic improvements.
Machine Learning for Computer Systems
The use of machine learning to replace traditional heuristics in computer systems also greatly interests us. We have shown how to use reinforcement learning to make placement decisions for mapping computational graphs onto a set of computational devices that are better than human experts. With other colleagues in Google Research, we have shown in “The Case for Learned Index Structures” that neural networks can be both faster and much smaller than traditional data structures such as B-trees, hash tables, and Bloom filters. We believe that we are just scratching the surface in terms of the use of machine learning in core computer systems, as outlined in a NIPS workshop talk on Machine Learning for Systems and Systems for Machine Learning.
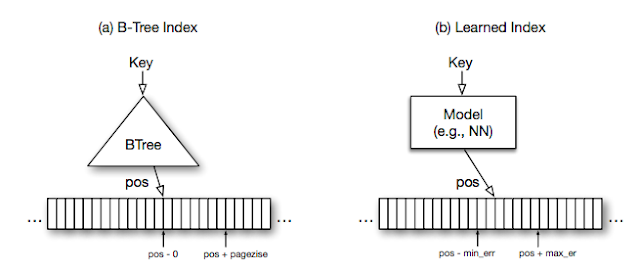 |
| Learned Models as Index Structures |
Machine learning and its interactions with security and privacy continue to be major research foci for us. We showed that machine learning techniques can be applied in a way that provides differential privacy guarantees, in a paper that received one of the best paper awards at ICLR 2017. We also continued our investigation into the properties of adversarial examples, including demonstrating adversarial examples in the physical world, and how to harness adversarial examples at scale during the training process to make models more robust to adversarial examples.
Understanding Machine Learning Systems
While we have seen impressive results with deep learning, it is important to understand why it works, and when it won’t. In another one of the best paper awards of ICLR 2017, we showed that current machine learning theoretical frameworks fail to explain the impressive results of deep learning approaches. We also showed that the “flatness” of minima found by optimization methods is not as closely linked to good generalization as initially thought. In order to better understand how training proceeds in deep architectures, we published a series of papers analyzing random matrices, as they are the starting point of most training approaches. Another important avenue to understand deep learning is to better measure their performance. We showed the importance of good experimental design and statistical rigor in a recent study comparing many GAN approaches that found many popular enhancements to generative models do not actually improve performance. We hope this study will give an example for other researchers to follow in making robust experimental studies.
We are developing methods that allow better interpretability of machine learning systems. And in March, in collaboration with OpenAI, DeepMind, YC Research and others, we announced the launch of Distill, a new online open science journal dedicated to supporting human understanding of machine learning. It has gained a reputation for clear exposition of machine learning concepts and for excellent interactive visualization tools in its articles. In its first year, Distill has published many illuminating articles aimed at understanding the inner working of various machine learning techniques, and we look forward to the many more sure to come in 2018.
 |
| Feature Visualization |
 |
| How to Use t-SNE effectively |
Open datasets like MNIST, CIFAR-10, ImageNet, SVHN, and WMT have pushed the field of machine learning forward tremendously. Our team and Google Research as a whole have been active in open-sourcing interesting new datasets for open machine learning research over the past year or so, by providing access to more large labeled datasets including:
- YouTube-8M: >7 million YouTube videos annotated with 4,716 different classes
- YouTube-Bounding Boxes: 5 million bounding boxes from 210,000 YouTube videos
- Speech Commands Dataset: thousands of speakers saying short command words
- AudioSet: 2 million 10-second YouTube clips labeled with 527 different sound events
- Atomic Visual Actions (AVA): 210,000 action labels across 57,000 video clips
- Open Images: 9M creative-commons licensed images labeled with 6000 classes
- Open Images with Bounding Boxes: 1.2M bounding boxes for 600 classes
 |
| Examples from the YouTube-Bounding Boxes dataset: Video segments sampled at 1 frame per second, with bounding boxes successfully identified around the items of interest. |
 |
| A map showing the broad distribution of TensorFlow users (source) |
In February, we hosted the first ever TensorFlow Developer Summit, with over 450 people attending live in Mountain View and more than 6,500 watching on live streams around the world, including at more than 85 local viewing events in 35 countries. All talks were recorded, with topics ranging from new features, techniques for using TensorFlow, or detailed looks under the hoods at low-level TensorFlow abstractions. We’ll be hosting another TensorFlow Developer Summit on March 30, 2018 in the Bay Area. Sign up now to save the date and stay updated on the latest news.
| This rock-paper-scissors science experiment is a novel use of TensorFlow. We’ve been excited by the wide variety of uses of TensorFlow we saw in 2017, including automating cucumber sorting, finding sea cows in aerial imagery, sorting diced potatoes to make safer baby food, identifying skin cancer, helping to interpret bird call recordings in a New Zealand bird sanctuary, and identifying diseased plants in the most popular root crop on Earth in Tanzania! |
TensorFlow has also benefited from other Google Research teams open-sourcing related work, including TF-GAN, a lightweight library for generative adversarial models in TensorFlow, TensorFlow Lattice, a set of estimators for working with lattice models, as well as the TensorFlow Object Detection API. The TensorFlow model repository continues to grow with an ever-widening set of models.
In addition to TensorFlow, we released deeplearn.js, an open-source hardware-accelerated implementation of deep learning APIs right in the browser (with no need to download or install anything). The deeplearn.js homepage has a number of great examples, including Teachable Machine, a computer vision model you train using your webcam, and Performance RNN, a real-time neural-network based piano composition and performance demonstration. We’ll be working in 2018 to make it possible to deploy TensorFlow models directly into the deeplearn.js environment.
TPUs
 |
| Cloud TPUs deliver up to 180 teraflops of machine learning acceleration |
 |
| Cloud TPU Pods deliver up to 11.5 petaflops of machine learning acceleration |
 |
| Experiments with ResNet-50 training on ImageNet show near-perfect speed-up as the number of TPU devices used increases. |
Thanks for reading!
(In part 2 we’ll discuss our research in the application of machine learning to domains like healthcare, robotics, different fields of science, and creativity, as well as cover our work on fairness and inclusion.)
-
Labels:
- Machine Intelligence
- Product
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯