The C4_200M Synthetic Dataset for Grammatical Error Correction
August 10, 2021
Posted by Felix Stahlberg and Shankar Kumar, Research Scientists, Google Research
Quick links
Grammatical error correction (GEC) attempts to model grammar and other types of writing errors in order to provide grammar and spelling suggestions, improving the quality of written output in documents, emails, blog posts and even informal chats. Over the past 15 years, there has been a substantial improvement in GEC quality, which can in large part be credited to recasting the problem as a "translation" task. When introduced in Google Docs, for example, this approach resulted in a significant increase in the number of accepted grammar correction suggestions.
One of the biggest challenges for GEC models, however, is data sparsity. Unlike other natural language processing (NLP) tasks, such as speech recognition and machine translation, there is very limited training data available for GEC, even for high-resource languages like English. A common remedy for this is to generate synthetic data using a range of techniques, from heuristic-based random word- or character-level corruptions to model-based approaches. However, such methods tend to be simplistic and do not reflect the true distribution of error types from actual users.
In “Synthetic Data Generation for Grammatical Error Correction with Tagged Corruption Models”, presented at the EACL 16th Workshop on Innovative Use of NLP for Building Educational Applications, we introduce tagged corruption models. Inspired by the popular back-translation data synthesis technique for machine translation, this approach enables the precise control of synthetic data generation, ensuring diverse outputs that are more consistent with the distribution of errors seen in practice. We used tagged corruption models to generate a new 200M sentence dataset, which we have released in order to provide researchers with realistic pre-training data for GEC. By integrating this new dataset into our training pipeline, we were able to significantly improve on GEC baselines.
Tagged Corruption Models
The idea behind applying a conventional corruption model to GEC is to begin with a grammatically correct sentence and then to “corrupt” it by adding errors. A corruption model can be easily trained by switching the source and target sentences in existing GEC datasets, a method that previous studies have shown that can be very effective for generating improved GEC datasets.
 |
| A conventional corruption model generates an ungrammatical sentence (red) given a clean input sentence (green). |
The tagged corruption model that we propose builds on this idea by taking a clean sentence as input along with an error type tag that describes the kind of error one wishes to reproduce. It then generates an ungrammatical version of the input sentence that contains the given error type. Choosing different error types for different sentences increases the diversity of corruptions compared to a conventional corruption model.
 |
| Tagged corruption models generate corruptions (red) for the clean input sentence (green) depending on the error type tag. A determiner error may lead to dropping the “a”, whereas a noun-inflection error may produce the incorrect plural “sheeps”. |
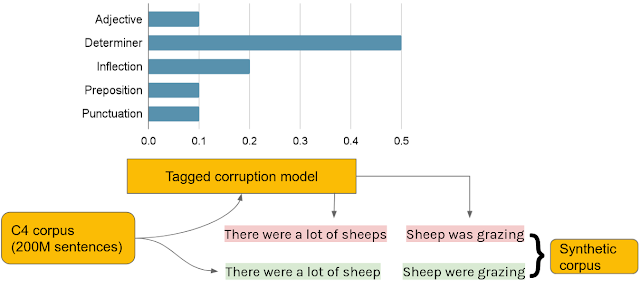
To use this model for data generation we first randomly selected 200M clean sentences from the C4 corpus, and assigned an error type tag to each sentence such that their relative frequencies matched the error type tag distribution of the small development set BEA-dev. Since BEA-dev is a carefully curated set that covers a wide range of different English proficiency levels, we expect its tag distribution to be representative for writing errors found in the wild. We then used a tagged corruption model to synthesize the source sentence.
 |
| Synthetic data generation with tagged corruption models. The clean C4 sentences (green) are paired with the corrupted sentences (red) in the synthetic GEC training corpus. The corrupted sentences are generated using a tagged corruption model by following the error type frequencies in the development set (bar chart). |
Results
In our experiments, tagged corruption models outperformed untagged corruption models on two standard development sets (CoNLL-13 and BEA-dev) by more than three F0.5-points (a standard metric in GEC research that combines precision and recall with more weight on precision), advancing the state-of-the-art on the two widely used academic test sets, CoNLL-14 and BEA-test.
In addition, the use of tagged corruption models not only yields gains on standard GEC test sets, it is also able to adapt GEC systems to the proficiency levels of users. This could be useful, for example, because the error tag distribution for native English writers often differs significantly from the distributions for non-native English speakers. For example, native speakers tend to make more punctuation and spelling mistakes, whereas determiner errors (e.g., missing or superfluous articles, like “a”, “an” or “the”) are more common in text from non-native writers.
Conclusion
Neural sequence models are notoriously data-hungry, but the availability of annotated training data for grammatical error correction is rare. Our new C4_200M corpus is a synthetic dataset containing diverse grammatical errors, which yields state-of-the-art performance when used to pre-train GEC systems. By releasing the dataset we hope to provide GEC researchers with a valuable resource to train strong baseline systems.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing