Testing LLMs on superconductivity research questions
March 16, 2026
Subhashini Venugopalan, Research Scientist, and Eun-ah Kim, Visiting Scientist, Google Research
Can LLMs become expert-level research partners in modern physics? Using high-temperature superconductivity as a case study, physicists tested six LLMs with challenging questions and graded the responses.
Quick links
Artificial intelligence (AI) is now routinely used to compose emails, edit images and summarize information from the web. AI also holds enormous potential to accelerate scientific research. However, its effectiveness in providing scientifically accurate and comprehensive answers to complex questions within specialized domains remains an active area of research, requiring AI to meet an extremely high bar for accuracy and to navigate complex, evolving areas of knowledge.
Our new paper published in the Proceedings of the National Academy of Sciences, “Expert evaluation of LLM world models: A high-Tc superconductivity case study”, assesses whether large language model (LLM) world models could answer expert-level questions in condensed matter physics. In collaboration with Cornell University, we asked six LLMs to answer high-level questions on high-temperature superconductors. A panel of experts then scored the responses on multiple criteria. We found that the top performers were two tools that drew from a closed ecosystem of certified, quality-controlled sources: NotebookLM and a custom-built system. We also identified key areas for improvement in all the systems studied. Results of this test case can help inform development of trustworthy tools to advance scientific discovery.
In previous related work, Google researchers evaluated whether LLMs could perform basic analytic tasks in several scientific fields by referencing research papers in six scientific disciplines. That work introduced CURIE, a benchmark for evaluating LLMs in fields ranging from biodiversity to condensed matter physics to protein sequencing, which includes questions that require analysis rather than just regurgitating facts. Other work explored using LLMs to interpret tables and figures, leveraging them to solve equations in quantum mechanics, and to solve engineering simulation problems using specialized software.
Several other groups across Google are also exploring AI to advance scientific research: as a thought partner for generating new hypotheses; as an agent to write expert-level scientific software; and with an AI-based model for single-cell analysis.
Navigating open research questions
In this work, we explored if LLMs can act as knowledgeable, unbiased thought partners in specialized fields that require in-depth research and an ability to balance competing theories around open scientific questions.
We focused on the underlying mechanisms of high-temperature superconductivity, an open area of inquiry in condensed matter physics since the Nobel Prize-awarded discovery of the phenomenon in 1987. For this study, we centered on a class of copper-containing compounds (known as cuprates). Cuprates can conduct electrons with zero electrical resistance at temperatures significantly higher than traditional superconductor materials, though still cold – their highest known temperature threshold is roughly -140 degrees Celsius. Understanding the underlying mechanism behind this behavior might help to discover more compounds with similar properties, potentially at higher temperatures, and could pave the way to more applications.
Over the decades, physicists have published thousands of studies using various experimental techniques to probe the quantum mechanical properties that lead to superconductivity. Several competing theories have been proposed and pursued by different research groups. The sheer volume of literature makes navigating this knowledge base extremely difficult for a new generation. Students entering the field would benefit from a knowledgeable tutor that has a neutral perspective on the published research.
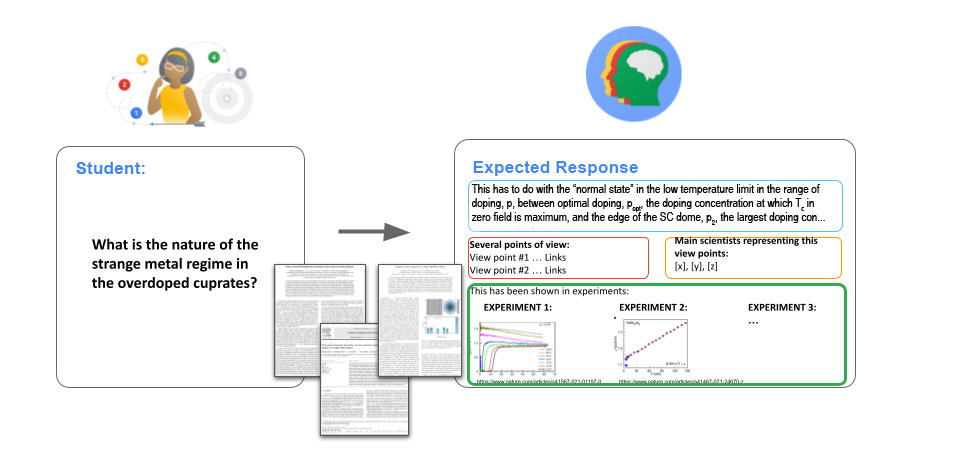
A graduate student or experienced researcher could benefit from a virtual thought partner to get up to speed on high-temperature superconductors or to explore future research directions. The researcher could ask a question and the LLM would provide a balanced response that reflects unresolved issues and debates in the field, along with links to references in the scientific literature. Our new paper assessed six LLMs at this task and found that closed systems with curated references provided more accurate, appropriately referenced answers.
Case study
To compare the impact of using different data sources, the study evaluated four models with full access to the web against two closed systems that drew from a curated database. For the two closed systems, twelve top international experts in the field of high-temperature superconductivity selected 15 scientific review articles to provide an overview of the field with quality-controlled initial source material. The four web-based models had full internet access, including 765 open-access experimental papers and 1,553 open-access theoretical papers.
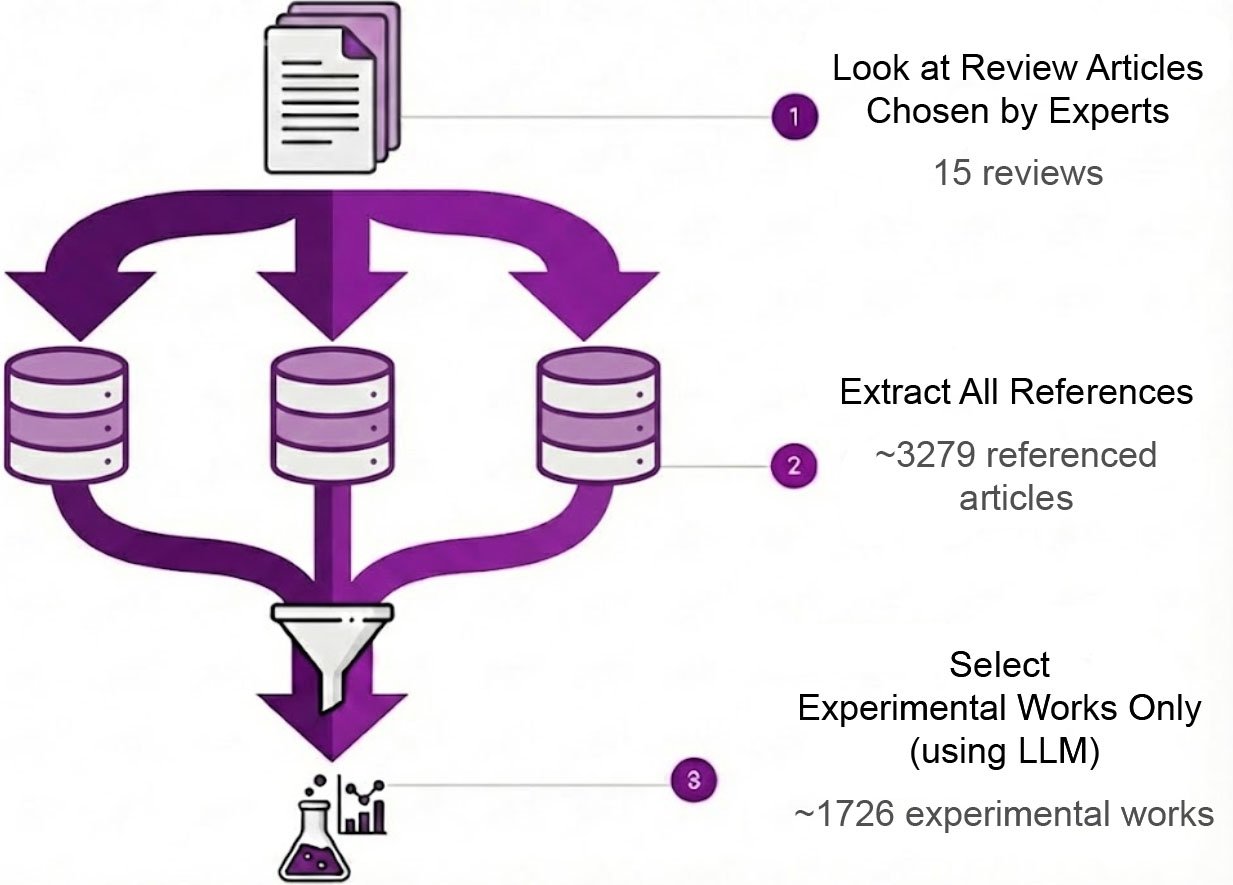
To create the two closed systems, we first assembled 15 expert-suggested review articles in the field of high-temperature superconductivity (top) and then extracted all the roughly 3,300 references cited by those review articles (middle). We then used Gemini to separate experimental studies from theoretical papers (bottom). The two closed systems used a selection of 1,726 sources that included experiment-based papers and review articles.
The expert panel then wrote 67 questions designed to test a model’s deep knowledge of the field, such as “At what level of doping does the Lifshitz transition occur in LSCO?” and “What is the evidence supporting the quantum critical point scenario in cuprates?” Finally, each expert evaluated six different models’ performance on answering those test questions.
Results
We evaluated six LLMs: GPT-4o, Perplexity, Claude 3.5, Gemini Advanced Pro 1.5, Google NotebookLM, and a custom-built retrieval-augmented generation (RAG) system. Using a masked review process, experts individually scored each model’s answers on a scale of 0 to 2 across six metrics:
- Balanced perspective: Whether varying scientific points of view were considered.
- Comprehensiveness: Factual depth without missing relevant experiments.
- Conciseness: Providing a brief and clear answer.
- Evidence: Supported by evidence and links to source material.
- Visual relevance: Quality of any provided images (applicable to the two LLMs that consistently included images).
- Qualitative feedback: Open ended expert comments.
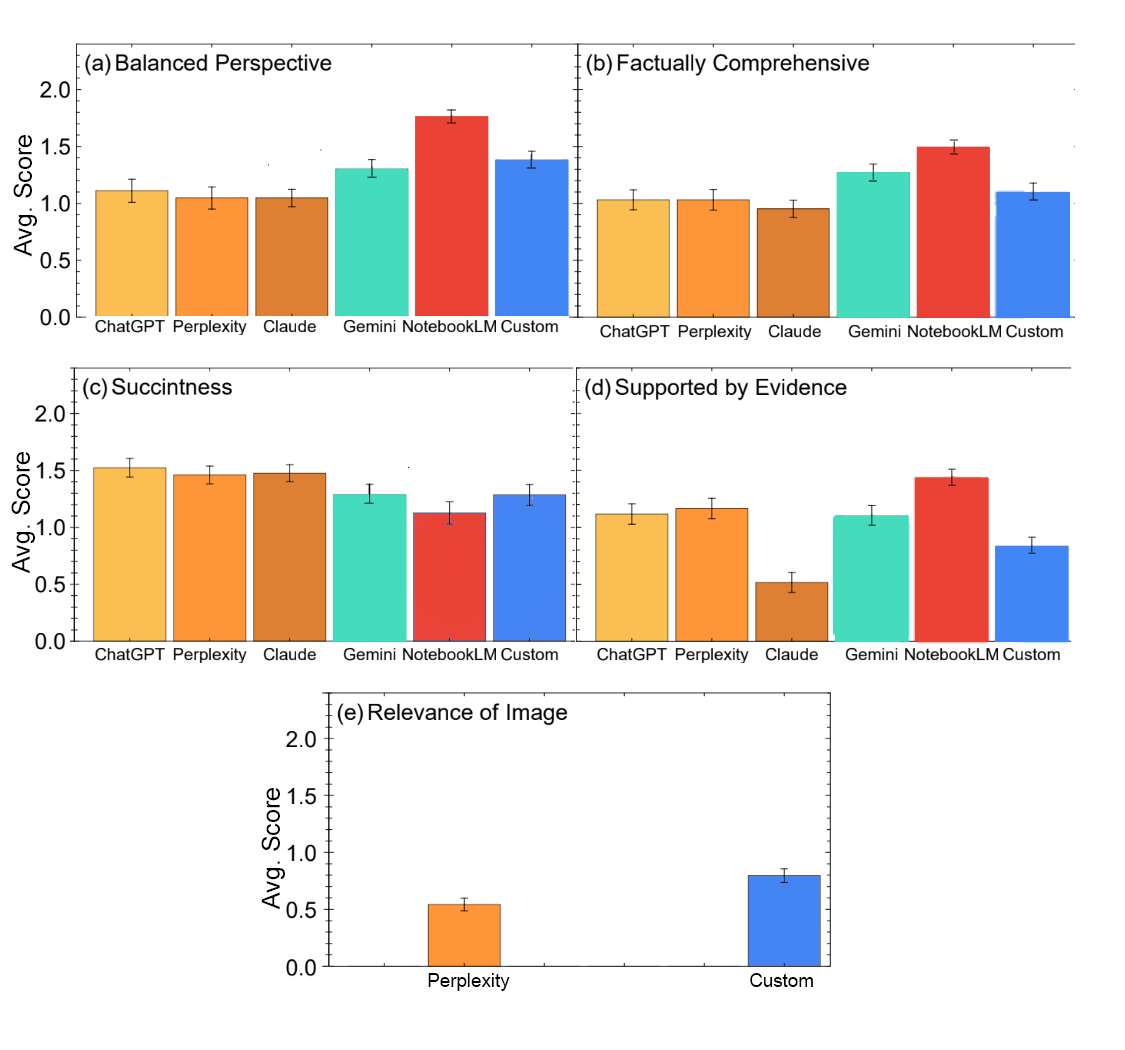
Of the six LLMs, NotebookLM stood out in most aspects of the masked tests. NotebookLM is a product that answers users’ questions based on a library of user-provided documents, in this case, a library of 1,726 sources with experimental papers and review articles. The next-highest overall performer was our custom RAG system containing the same sources. NotebookLM, Gemini and the custom RAG system scored in the top three for providing a balance of perspectives, and for offering comprehensive answers. Despite being the least succinct, NotebookLM scored highest for providing evidence. The relevance of images scores were generally lower, with the custom RAG scoring higher than the other LLM that provided images, Perplexity.
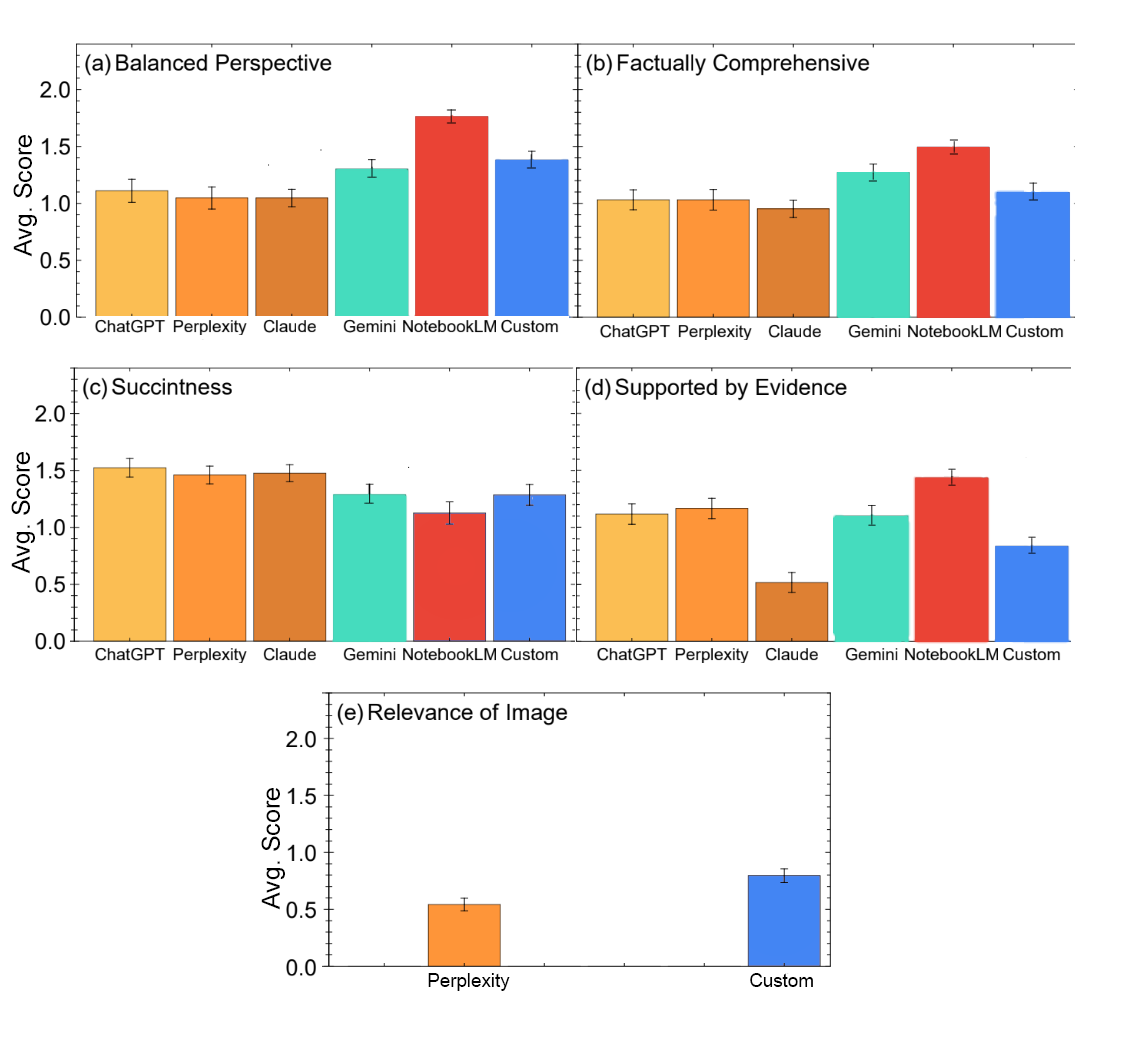
Average scores for six LLMs accessed in late 2024 on answering expert-formulated questions that probed the systems’ knowledge of high-temperature superconductors. Experts graded responses as 2 (good), 1 (ok) or 0 (bad). The LLMs that drew from curated references, specifically NotebookLM (red) and the custom-built system (blue), earned the highest overall scores from human experts.
Conclusion
Several larger conclusions emerge from this test case. The two models that drew from curated databases of experimental literature, NotebookLM and our custom-built tool, outperformed the LLMs trained on unfiltered internet data. In particular, models relying on open web sources tended to mix established theories with highly speculative ones.
The evaluated LLMs (accessed in December 2024) also showed weaknesses in temporal and contextual understanding. For example, they often failed to recognize when a proposed hypothesis was later disproved. They also frequently omitted relevant papers when they didn’t explicitly include the exact language used in the initial query.
Our results broadly highlight the need for LLMs to better understand tables and images, as scientific papers heavily use these formats. While two of the models consistently referenced images, they often relied more on image captions rather than on visual analysis. Enhancing visual reasoning capability, including interpreting images, plots and scale bars, is a major direction for future improvement.
Looking ahead
A reliable AI research partner could help rapidly onboard new graduate students on existing scientific literature and serve as an always-available thought partner. It could also help experienced scientists identify new research directions.
Despite existing limitations, our results suggest that LLMs can reach proficiency in complex fields involving open research questions. However, assessing a model’s capabilities in specialized fields relies on qualified experts whose knowledge is both essential and rare. We continue to work in this area, and will present the CMT-benchmark at ICLR 2026 in April as a more rigorous evaluation of LLMs in the broader field of condensed matter theory. Overall, these efforts required significant time and analysis from experts in physics; we hope the insights they produce can scale to inform the further development of trustworthy AI tools to advance scientific progress.
Acknowledgments
Research described here is a joint effort between Google Research, Cornell University, and Harvard University. We are grateful to the many incredible scientists across Stanford, Johns Hopkins, Flatiron Institute, CUNY, MIT, Cornell, and Harvard that made this study possible: Steven A. Kivelson, N. P. Armitage, Antoine Georges, Olivier Gingras, Dominik Kiese, Chunhan Feng, Vadim Oganesyan, T. Senthil, B.J. Ramshaw, and Subir Sachdev. We thank Haoyu Gao and student researcher Maria Tikhanovskaya for helping shape the study and datasets. We also acknowledge the valuable contributions of Oliver King and Wesley Hutchins for helping set up the study with NotebookLM. We appreciate Stephan Hoyer for thoughtful feedback on early manuscripts of this work. Finally, we thank John Platt and Michael Brenner for continuous support and encouragement that enabled this research.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence