Teaching LLMs to reason like Bayesians
March 4, 2026
Sjoerd van Steenkiste and Tal Linzen, Research Scientists, Google Research
We teach LLMs to reason in a Bayesian manner by training them to mimic the predictions of an optimal Bayesian model.
Quick links
AI systems based on large language models (LLMs) are increasingly used as agents that interact with users and the world. To do this successfully, LLMs need to construct internal representations of the world and estimate the probability that each of these representations is accurate. Take personalized recommendations, for example: the LLM needs to gradually infer the user’s preferences from their choices over the course of multiple interactions.
Bayesian inference defines the optimal way to perform such updates. By implementing this strategy, LLMs could optimize user interactions by updating their estimates of the user’s preferences as new info about the user arrives. But without specific training, LLMs often default to simple heuristics — like assuming everyone wants the cheapest option — instead of inferring a specific user's unique preferences.
In “Bayesian teaching enables probabilistic reasoning in large language models”, we teach the LLMs to reason in a Bayesian manner by training them to mimic the predictions of the Bayesian model, which defines the optimal way to reason about probabilities. We find that this approach not only significantly improves the LLM’s performance on the particular recommendation task on which it is trained, but also enables generalization to other tasks. This suggests that this method teaches the LLM to better approximate Bayesian reasoning. More generally, our results indicate that LLMs can effectively learn reasoning skills from examples and generalize those skills to new domains.
Evaluating LLMs’ Bayesian capabilities
As with humans, to be effective, an LLM’s user interactions require continual updates to its probabilistic estimates of the user’s preferences based on each new interaction with them. Here we ask: do LLMs act as if they have probabilistic estimates that are updated as expected from optimal Bayesian inference? To the extent that the LLM’s behavior deviates from the optimal Bayesian strategy, how can we minimize these deviations?
To test this, we used a simplified flight recommendation task, in which the LLMs interact as assistants with a simulated user for five rounds. In each round, three flight options were presented to both the user and the assistant. Each flight was defined by a departure time, a duration, a number of stops, and a cost. Each simulated user was characterized by a set of preferences: for each feature, they could have a strong or weak preference for high or low values of the feature (e.g., they may prefer longer or shorter flights), or no preference regarding this feature.
We compared the LLMs’ behavior to that of a model, a Bayesian assistant, that follows the optimal Bayesian strategy. This model maintains a probability distribution that reflects its estimates of the user’s preferences, and uses Bayes’ rule to update this distribution as new information about the user’s choices becomes available. Unlike many real-life scenarios, where it’s difficult to specify and implement the Bayesian strategy computationally, in this controlled setting it’s easy to implement and allows us to precisely estimate the extent to which LLMs deviate from it.
The goal of the assistant was to recommend the flight that matches the user’s choice. At the end of each round, the user indicated to the assistant whether or not it chose correctly, and provided it with the correct answer.
How a Bayesian assistant might update its estimates of what flights the user prefers in response to the observed evidence (i.e., the user choice) made available after each round. Crucially, the assistant can not directly access the users’ preferences, which makes this a challenging probabilistic reasoning task.
We evaluated a range of LLMs and found that they all performed significantly worse than the optimal Bayesian Assistant. Most importantly, in contrast to the Bayesian Assistant, which gradually improved its recommendations as it received additional information about the user’s choices, LLMs’ performance often plateaued after a single interaction, pointing to a limited ability to adapt to new information and showing limited or no improvement over multiple interactions with the user.
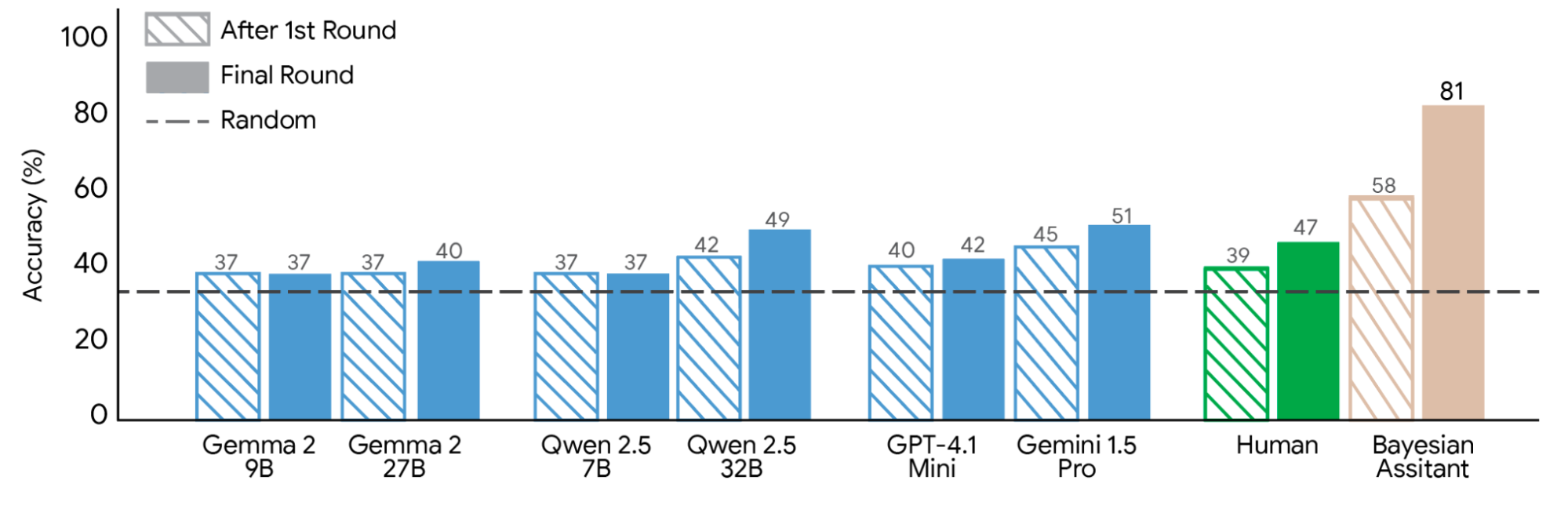
We compared off-the-shelf LLMs from different model families to human participants and the Bayesian Assistant. The LLMs performed considerably worse than the Bayesian Assistant. Human participants demonstrated a greater improvement than most LLMs as they received more information, but they still fell short of the accuracy that characterizes the optimal Bayesian strategy.
We compared the recommendation accuracy of the Bayesian Assistant with human and various off-the-shelf LLMs after the first and final rounds of three sets of interactions with 624 users.
The Bayesian teaching framework
In the Bayesian framework, an agent maintains a prior belief about the state of the world. For an LLM, this "world state" is its internal representation of facts, relationships, and concepts. As the model encounters new information (evidence), it needs to convert its prior belief (or “prior”, the initial guess or probability for something before seeing new evidence) into a “posterior belief” (the updated probability after incorporating new data) that serves as the new prior for the next piece of evidence. This cyclical process allows the agent to continuously refine its understanding of the world.
The challenge is teaching the model how to perform these probabilistic updates. We did this through supervised fine-tuning, where we had the model update its parameters based on a large number of interactions it observed with users.
We explored two strategies to create supervised fine-tuning data. In the first strategy, which we refer to as Oracle teaching, we provided the LLM with interactions between simulated users and an “oracle” assistant that has perfect knowledge of the user’s preferences, and as such always recommends the option that is identical to the user’s choices.
The second strategy, which we call Bayesian teaching, provided the LLM with interactions between the Bayesian Assistant and the user. In this setting, the assistant often chose flights that did not match the user’s preferred choice, especially in early rounds where there was considerable uncertainty about the user’s preferences. We hypothesized that mimicking the Bayesian Assistant’s best guesses would teach the LLM to maintain uncertainty and update its beliefs more effectively than Oracle teaching, where the LLM is trained on the correct choices. This approach can be seen as a form of distillation, where a model is trained by learning to mimic another system.
Results
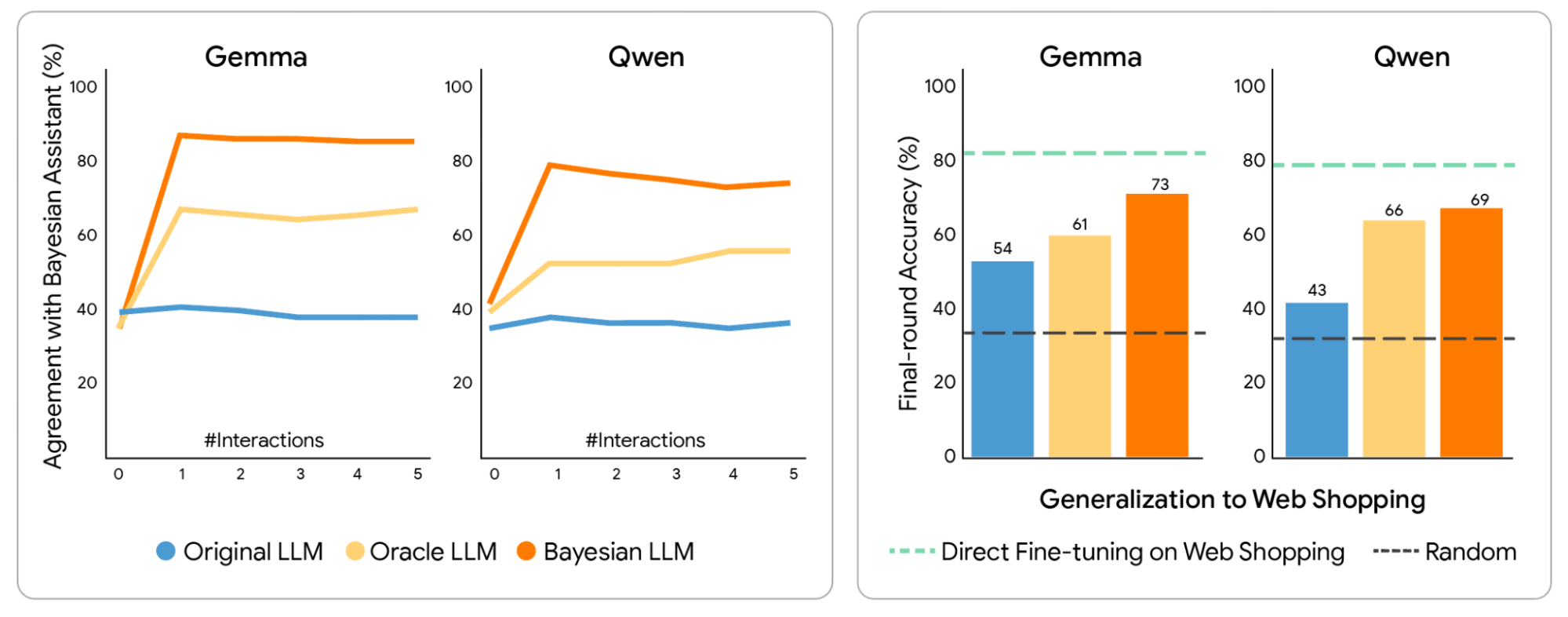
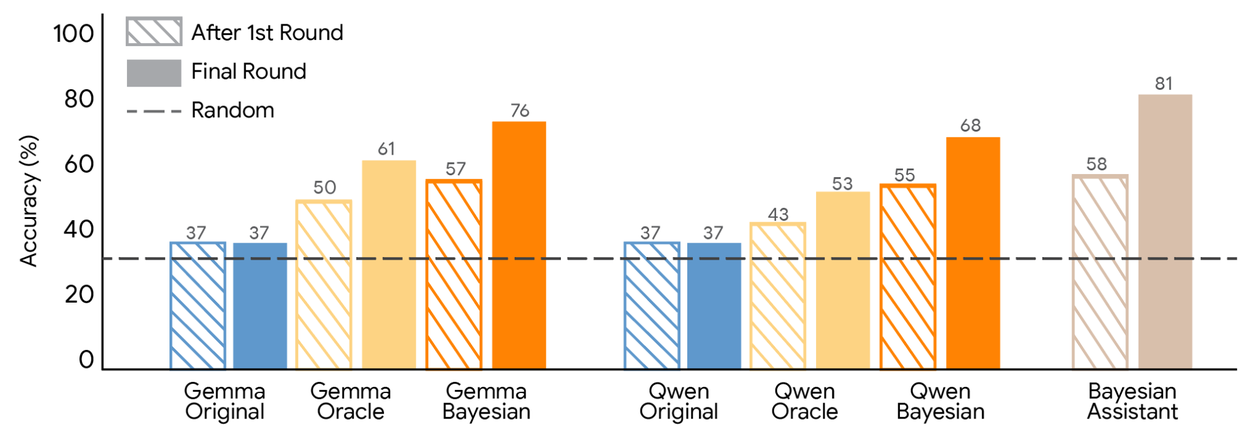
Supervised fine-tuning teaches LLMs to approximate probabilistic inference. We examined the accuracy after the first round and final (fifth) round across different assistants. We compared the original LLMs, LLMs fine-tuned on user interactions with the Bayesian Assistant, and LLMs fine-tuned on user interactions with an oracle, which always provided the correct answer. Both types of fine-tuning significantly improved LLMs’ performance, and Bayesian teaching was consistently more effective than oracle teaching.
Fine-tuned LLMs using Bayesian teaching agreed more with the Bayesian Assistant, and generalized outside the task used for fine-tuning. We showed agreement between the LLMs and the Bayesian Assistant, measured by the proportion of trials where the LLMs made the same predictions as the Bayesian Assistant. Fine-tuning on the Bayesian Assistant’s predictions made the LLMs more Bayesian, with the Bayesian versions of each LLM achieving the highest agreement with the Bayesian Assistant. We also looked at the final-round accuracy for LLMs on the web shopping domain, which was unseen during fine-tuning. The green dashed line in the figure below indicates the performance of the LLM when it was fine-tuned directly on web shopping data, such that no domain generalization was necessary, but which might be more difficult to obtain.
Recommendation accuracy of Gemma and Qwen after fine-tuning on user interactions with the Bayesian assistant or with an oracle.
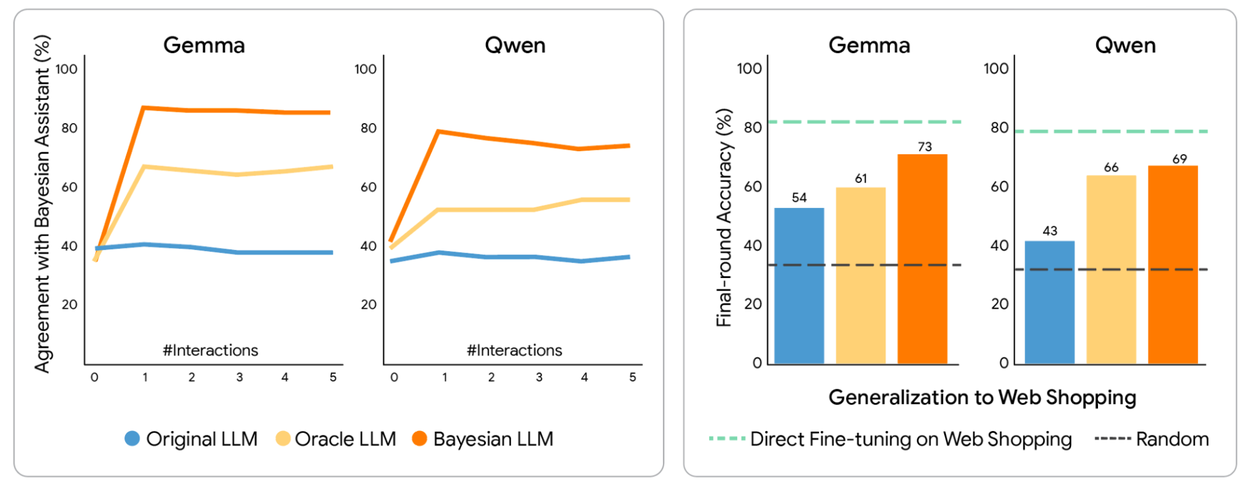
Proportion of trials where the LLMs and the Bayesian assistant made the same predictions (left), and recommendation accuracy in a web shopping domain, not seen during training (right).
Bayesian teaching significantly outperformed Oracle teaching, enabling models to agree with mathematical ideals 80% of the time. These fine-tuned models developed a realistic sensitivity to information, learning to weigh specific user choices more heavily when those choices revealed clearer preferences.
Crucially, these newly acquired skills were not task-specific. Models trained on synthetic flight data successfully transferred their "probabilistic logic" to entirely different domains, such as hotel recommendations and real-world web shopping. This suggests that LLMs can internalize the core principles of Bayesian inference, transforming from static pattern-matchers into adaptive agents capable of cross-domain reasoning.
What’s next for Bayesian teaching?
We tested a range of LLMs and found that they struggled to form and update probabilistic beliefs. We further found that continuing the LLMs’ training through exposure to interactions between users and the Bayesian Assistant — a model that implements the optimal probabilistic belief update strategy — dramatically improved the LLMs’ ability to approximate probabilistic reasoning.
While our findings from our first experiment point to the limitations of particular LLMs, the positive findings of our subsequent fine-tuning experiments can be viewed as a demonstration of the strength of the LLM “post-training” paradigm more generally. By training the LLMs on demonstrations of the optimal strategy to perform the task, we were able to improve their performance considerably, suggesting that they learned to approximate the probabilistic reasoning strategy illustrated by the demonstrations. The LLMs were able to generalize this strategy to domains where it is difficult to encode it explicitly in a symbolic model, demonstrating the power of distilling a classic symbolic model into a neural network.
Quick links
Other posts of interest
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence