Teaching Gemini to spot exploding stars with just a few examples
October 20, 2025
Turan Bulmus, Head of GenAI Blackbelts and Solution Architects, Google Cloud, and Dr. Fiorenzo Stoppa, Royal Society Newton International Fellow, University of Oxford
In a publication in Nature Astronomy, we show how Google's Gemini model can be transformed into an expert astronomy assistant that classifies cosmic events with high accuracy and explains its reasoning in plain language, achieving 93% accuracy across three datasets by learning from just 15 annotated examples per survey.
Quick links
Modern astronomy is a treasure hunt on a cosmic scale. Every night, telescopes around the globe scan the skies, searching for fleeting events like exploding stars (supernovae) that give us crucial insights into the workings of the universe. These surveys generate millions of alerts about potential discoveries, but there’s a catch: the vast majority are not real cosmic events but "bogus" signals from satellite trails, cosmic ray hits, or other instrumental artefacts.
For years, astronomers have used specialized machine learning models, like convolutional neural networks (CNNs), to sift through this data. While effective, these models often act as “black boxes,” providing a simple "real" or "bogus" label with no explanation. This forces scientists to either blindly trust the output or spend countless hours manually verifying candidates — a bottleneck that will soon become insurmountable with next-generation telescopes like the Vera C. Rubin Observatory, expected to generate 10 million alerts per night.
This challenge led us to ask a fundamental question: could a general-purpose, multimodal model, designed to understand text and images together, not only match the accuracy of these specialized models but also explain what it sees? In our paper, “Textual interpretation of transient image classifications from large language models”, published in Nature Astronomy, we demonstrate that the answer is a resounding yes. We show how Google’s Gemini model can be transformed into an expert astronomy assistant that can classify cosmic events with high accuracy and, crucially, explain its reasoning in plain language. We accomplished this by employing few-shot learning with Gemini, providing it with just 15 annotated examples per survey and concise instructions to accurately classify and explain cosmic events.
A new approach: Learning from a few examples
Instead of training a specialized model on millions of labeled images, we used a technique called few-shot learning on a general-purpose model. We gave Gemini just 15 annotated examples for each of three major astronomical surveys: Pan-STARRS, MeerLICHT, and ATLAS. Each example consisted of three small images: a new image of the transient alert, a reference image of the same patch of sky from a previous observation, and a difference image that highlights the change between the two. Alongside these images, we provided a concise set of instructions, a short expert-written note explaining the classification, and an interest score (e.g., “high interest” for a likely supernova, “low interest” for a variable star, or “no interest” for a bogus signal) along with an explanation of that score.
The model had to learn to classify transients from a diverse set of telescopes, each with different resolutions, pixel scales, and camera characteristics. As shown below, the same celestial object can appear quite different across these surveys, but Gemini was able to generalize from the few examples provided.

Gemini operates across surveys with diverse pixel scales and resolutions. The same transient is observed in three different surveys, with rows corresponding to Pan-STARRS (top), MeerLICHT (middle) and ATLAS (bottom). Each row includes, from left to right, a new image, a reference image and a difference image. The image stamps are all the same size in pixels (100 × 100) but differ in angular sky coverage due to survey-specific pixel scales: Pan-STARRS (0.25" per pixel), MeerLICHT (0.56" per pixel) and ATLAS (1.8" per pixel).
Guided only by this minimal input, we asked Gemini to classify thousands of new alerts. The model achieved an average accuracy of 93% across the three datasets, which is on par with specialized CNNs that require massive, curated training datasets.
But unlike a traditional classifier, we prompted Gemini not just to output a label but also to generate for every candidate:
- A textual explanation describing the features it observed and the logic behind its decision.
- An interest score to help astronomers prioritize follow-up observations.
This turns the model from a black box into a transparent, interactive partner. Scientists can read the explanation to understand the model’s reasoning, building trust and allowing for more nuanced decision-making.

Gemini provides human-readable transient classifications and follow-up priorities. Each example consists of a new, reference and difference image for a candidate transient, followed by the Gemini classification, textual description and follow-up interest score. The examples shown in the figure are from the MeerLICHT dataset.
Knowing when to ask for help
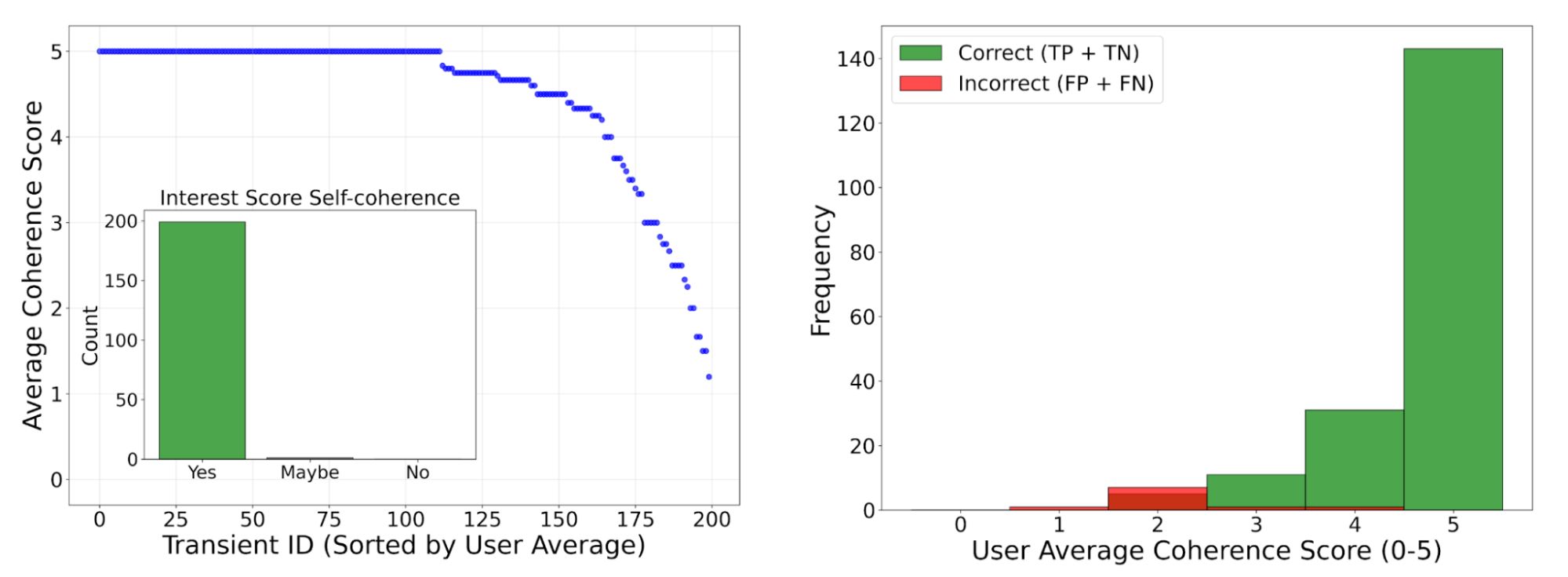
A critical step in building a reliable system is ensuring the quality of its output. We assembled a panel of 12 professional astronomers who reviewed 200 of Gemini’s classifications and explanations. Using a single, anchored 0–5 coherence rubric (0 = hallucination, 5 = perfectly coherent) tied to how well the text matched the new/reference/difference images, plus a simple Yes/Maybe/No check that the follow-up interest score agreed with the explanation, they rated the model’s descriptions as highly coherent and useful, confirming alignment with expert reasoning.
But perhaps our most important finding was that Gemini can effectively assess its own uncertainty. We prompted the model to assign a “coherence score” to its own explanations. We discovered that low-coherence scores were a powerful indicator of an incorrect classification. In other words, the model is good at telling us when it’s likely to be wrong. The details:
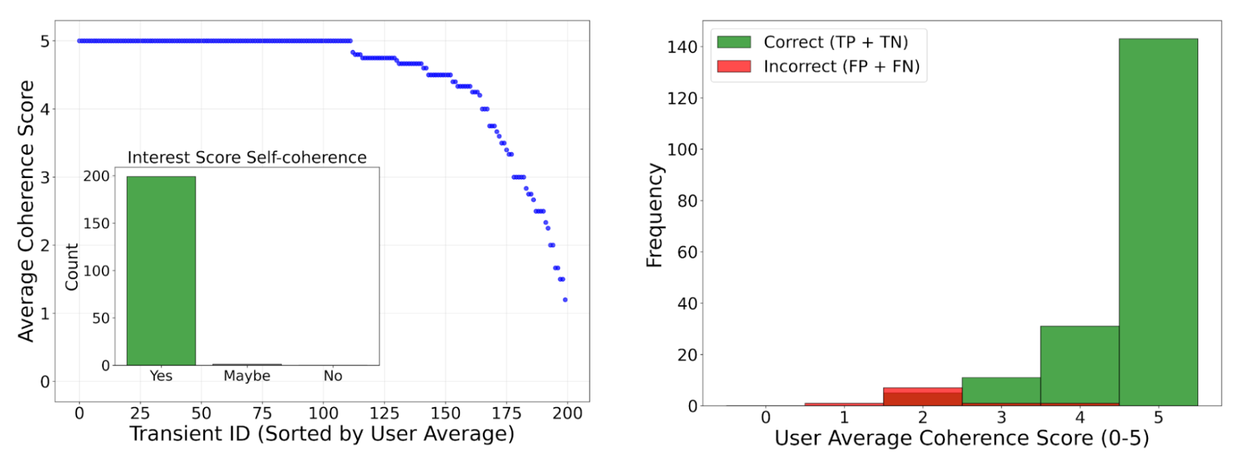
Left: Average coherence scores from 12 astronomers for 200 MeerLICHT transients, sorted by mean score (blue). Most examples received high values (4–5), indicating close alignment with user expectations. Inset: The consistency between the interest score assigned by the model & its own explanation, with nearly all cases marked as self-consistent (i.e., “Yes”). Right: Average user coherence scores, split by the correctness of the classification made by Gemini. Correctly classified examples (TPs & TNs, green) tend to have higher coherence scores than incorrect ones (FPs & FNs, red).
This capability is a game-changer for building reliable "human-in-the-loop" workflows. By automatically flagging its most uncertain cases, the system can focus astronomers' attention where it is most needed. This creates a powerful feedback loop. By reviewing the flagged cases and adding a few of these challenging examples back into the prompt, we can rapidly improve the model’s performance. Using this iterative process, we improved the model's accuracy on the MeerLICHT dataset from ~93.4% to ~96.7%, demonstrating how the system can learn and improve in partnership with human experts.
The future of scientific discovery
We believe this approach marks a step toward a new era of scientific discovery — one accelerated by models that can both reason over complex scientific datasets and explain their outputs in natural language., but by models that can reason, explain their output, and collaborate with researchers.
Because this method requires only a small set of examples and plain-language instructions, it can potentially be rapidly adapted for new scientific instruments, surveys, and research goals across many different fields. We envision this technology as a foundation for "agentic assistants" in science. Such systems could integrate multiple data sources, check their own confidence, request follow-up observations, and escalate only the most promising discoveries to human scientists.
This work shows a path toward systems that learn with us, explain their reasoning, and empower researchers in any field to focus on what matters most: asking the next great question.
Acknowledgements
This research was a collaborative effort. We extend our sincere thanks to our co-authors Steven Bloemen, Stephen J. Smartt, Paul J. Groot, Paul Vreeswijk, and Ken W. Smith.
Quick links
Other posts of interest
-

June 12, 2026
Research into how AI can help users understand skin conditions- Health & Bioscience ·
- Human-Computer Interaction and Visualization
-

June 4, 2026
Towards passive heart health monitoring via smartphone camera- Health & Bioscience ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

June 3, 2026
The next chapter in flood resilience: Open sourcing Google’s hydrology framework- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets