Teaching AI to read a map
February 17, 2026
Artemis Panagopoulou, Student Researcher, and Mohit Goyal, Senior Software Engineer, Google
We propose a system for synthetic data generation to train AI systems to visually follow any route on any map, finally teaching language models to navigate our world.
Look at a map of a shopping mall or a theme park. Within seconds, your brain processes the visual information, identifies your location, and traces the optimal path to your destination. You instinctively understand which lines are walls and which are walkways. This fundamental skill — fine-grained spatial reasoning — is second nature.
For all their incredible advances, multimodal large language models (MLLMs) often struggle with this particular task. While MLLMs can identify a picture of a zoo and list the animals you might find there, they may have a difficult time tracing a valid path from the entrance to the reptile house. They might draw a line straight through an enclosure or a gift shop, failing to respect the basic constraints of the environment. This reveals a critical gap: today’s models are excellent at recognizing what’s in an image, but they falter when they need to understand the geometric and topological relationships between the objects.
To address this challenge, in “MapTrace: Scalable Data Generation for Route Tracing on Maps”, we introduce a new task, dataset, and synthetic data generation pipeline designed to teach MLLMs the fundamental skill of tracing paths on maps. Our work shows that this complex spatial ability, largely absent from pre-trained models, can be explicitly taught through targeted, synthetically-generated data. We also open-source 2M question answer pairs generated with the proposed pipeline utilizing Gemini 2.5 Pro and Imagen-4 Models to encourage the research community to further explore this area.
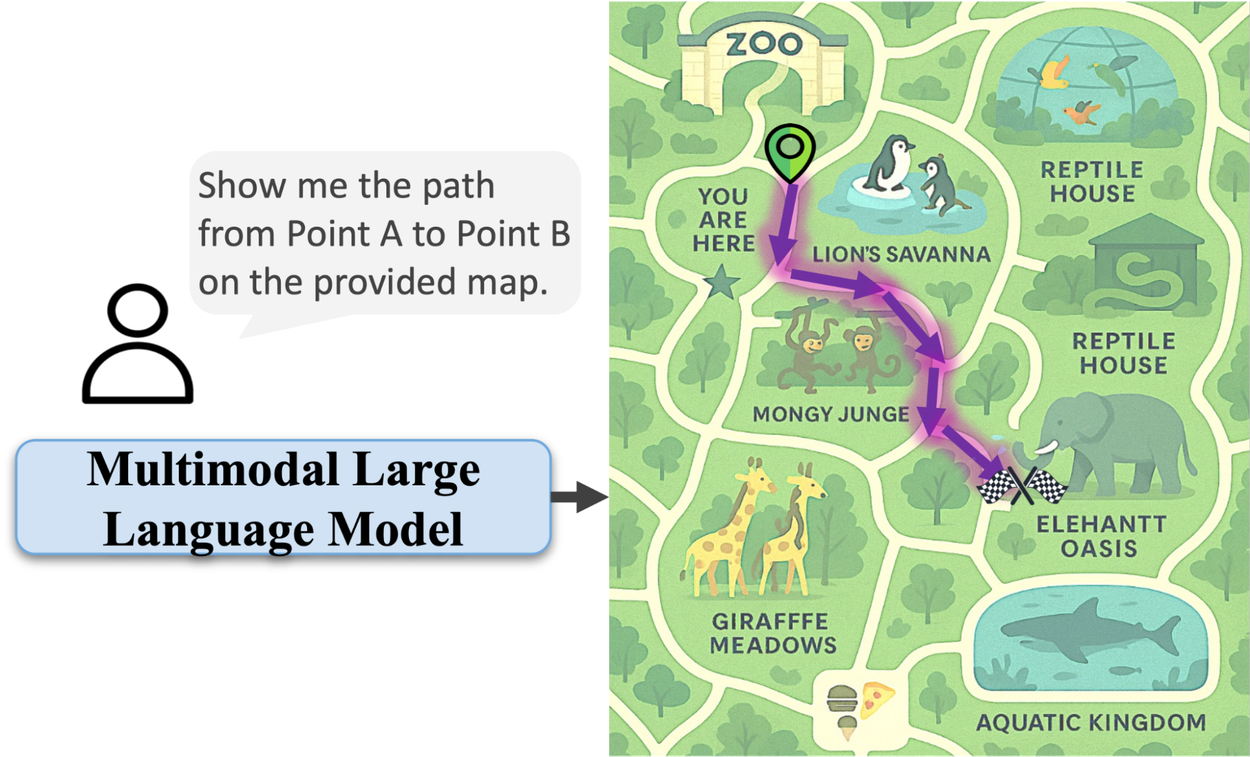
Given a start and end location on a map, the model outputs a valid path that respects map constraints. We observed that the generated images tend to render text incorrectly however we mostly focus on path qualities in this work. We believe that with improvements in image generation models, these artifacts can be easily suppressed in future work.
The challenge: A lack of grounding in the physical world
Why is tracing a path on a map so hard for AI models? It boils down to data. MLLMs learn from vast datasets of images and text. They learn to associate the word "path" with images of sidewalks and trails. However, they rarely see data that explicitly teaches them the rules of navigation — that paths have connectivity, that you can't walk through walls, and that a route is an ordered sequence of connected points.
The most direct way to teach this would be to collect a massive dataset of maps with millions of paths traced by hand. But annotating a single path with pixel-level accuracy is a painstaking process, and scaling it to the level required for training a large model is practically impossible. Furthermore, many of the best examples of complex maps — like those for malls, museums, and theme parks — are proprietary and cannot be easily collected for research.
This data bottleneck has held back progress. Without sufficient training examples, models lack the "spatial grammar" to interpret a map correctly. They see a soup of pixels, not a structured, navigable space.
The solution: A scalable pipeline for synthetic data
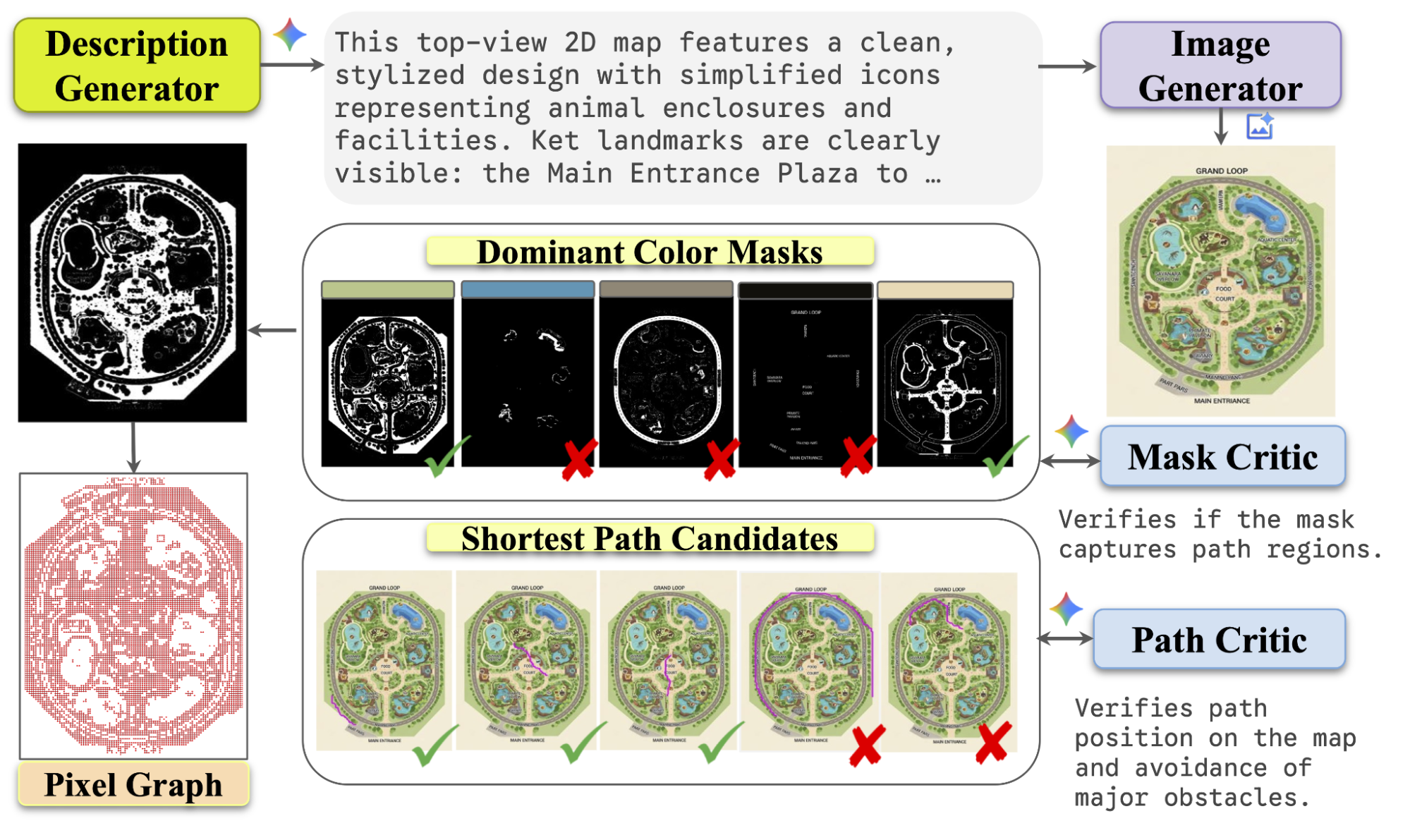
To address this data gap, we designed a fully automated, scalable pipeline that leverages the generative capabilities of Gemini Models to produce diverse high-quality maps. This process allows fine-grained control over data diversity and complexity, generating annotated paths that adhere to intended routes and avoid non-traversable regions without the need for collecting large-scale real-world maps.
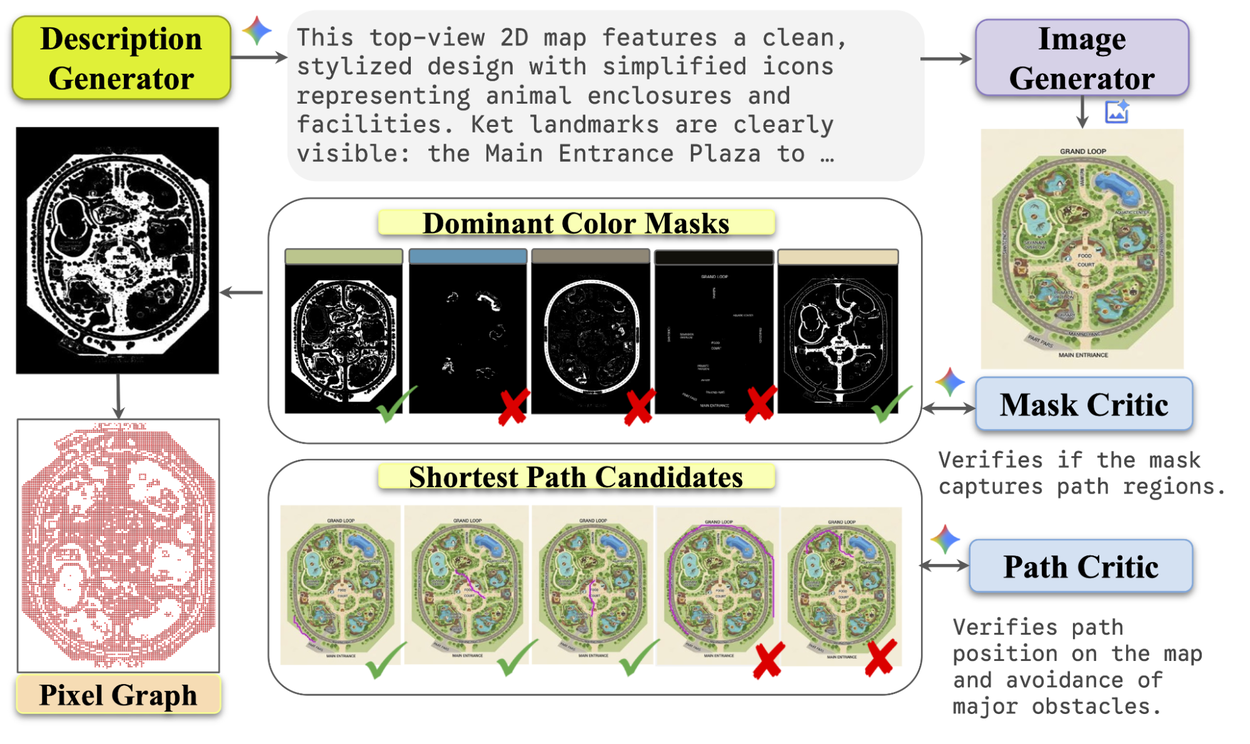
Scalable pipeline for route tracing data on maps.
The pipeline works in four automated and scalable stages, using AI models as both creators and critics to ensure quality and produce pixel-level annotations.
1. Generating diverse maps
First, we use a large language model (LLM) to generate rich, descriptive prompts for different types of maps. The LLM generates everything from "a map of a zoo with interconnected habitats" to "a shopping mall with a central food court" or "a fantasy theme park with winding paths through different themed lands." These text prompts are then fed into a text-to-image model that renders them into complex map images.
2. Identifying traversable paths with an AI "Mask Critic"
Once we have a map image, we need to identify all the "walkable" areas. Our system does this by clustering the pixels by color to create candidate path masks — essentially, a black-and-white map of all the walkways.
But not every shaded region is a valid path. So, we employ another MLLM as a "Mask Critic” used to examine each candidate mask and judge whether it represents a realistic, connected network of paths by looking at both the map image and the mask candidate. If the MLLM identifies the mask candidate as containing mostly valid traversable regions (e.g., paved sidewalks, marked crosswalks, pedestrian-only paths), then it labels the candidate as high quality. Then only these high-quality masks are passed to the next stage.
3. Building a navigable graph
With a clean mask of all traversable areas, we convert that 2D image into a more structured graph format. Think of this as creating a digital version of a road network, where intersections are nodes and the roads between them are edges. This "pixel-graph" captures the connectivity of the map, making it easy to calculate routes computationally.
4. Generating perfect paths with an AI "Path Critic"
Finally, we sample thousands of random start and end points on the graph for each map. We use a classic Dijkstra's algorithm to find the absolute shortest path between these points. Then, we use another MLLM as a "Path Critic" to perform a final quality check. This critic looks at the final generated path overlaid on the map image and gives it a thumbs-up or thumbs-down, ensuring the route is logical, stays within the lines, and looks like a path a human would take.
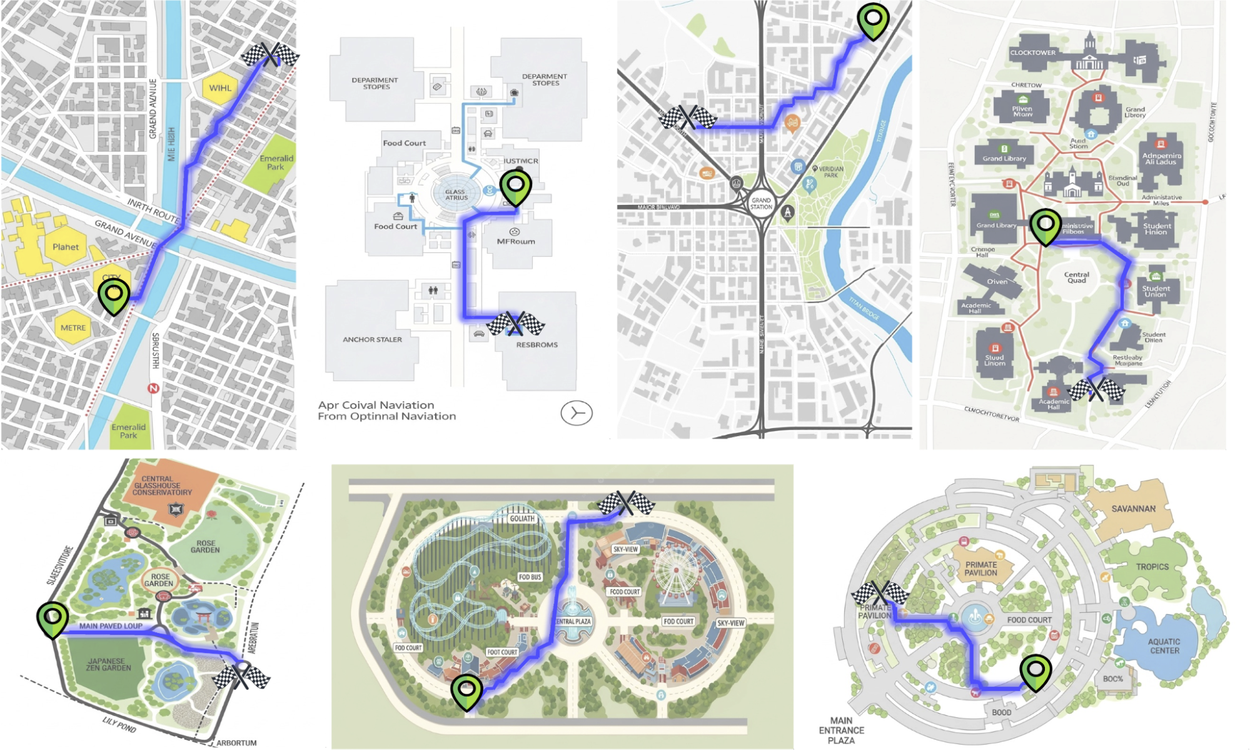
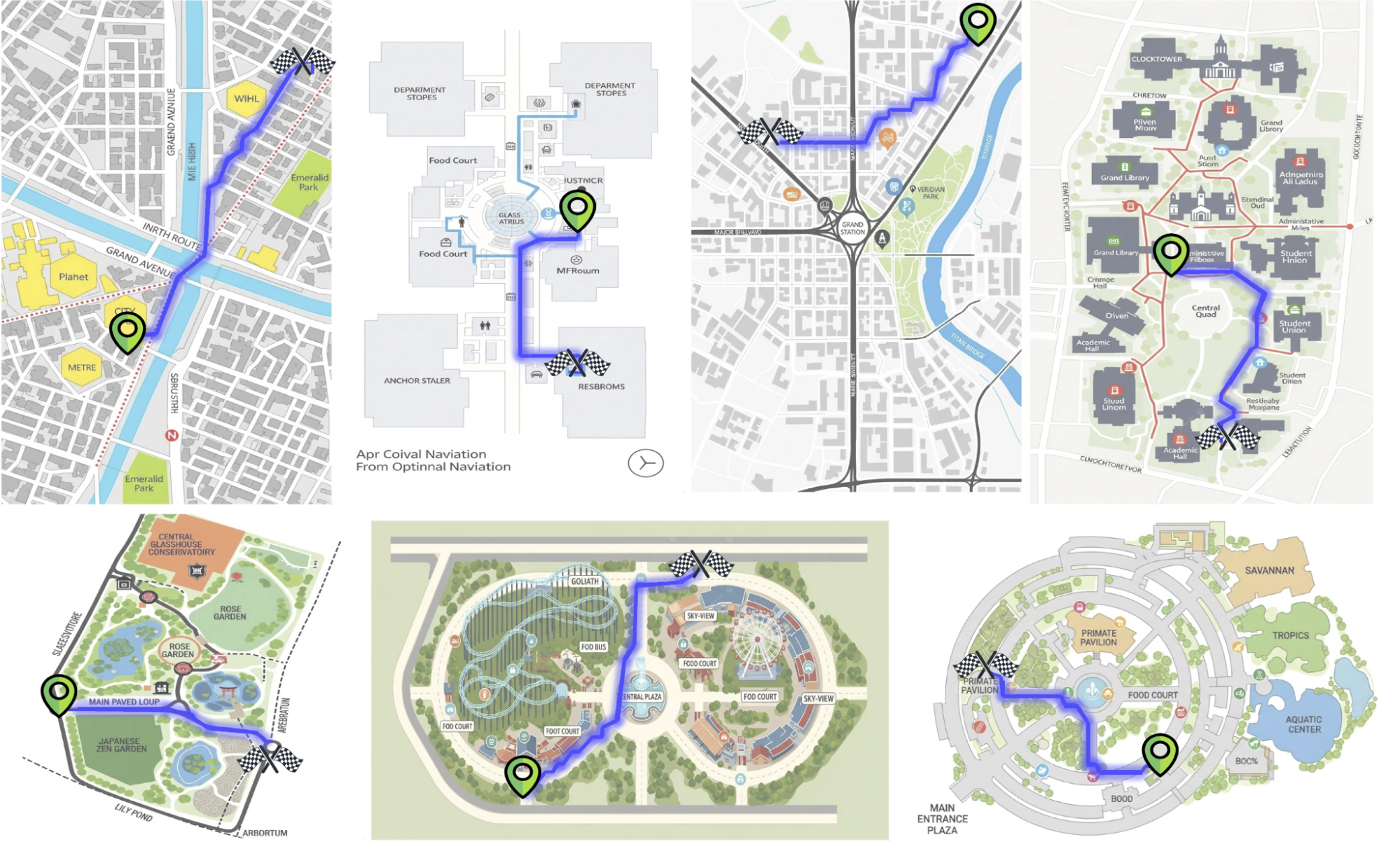
Example Paths generated by the proposed pipeline.
This pipeline enabled us to create a dataset of 2M annotated map images with valid paths. While the generated images occasionally exhibit typographic errors, this study focuses primarily on path fidelity. We anticipate that ongoing advancements in generative modeling will naturally mitigate these artifacts in future iterations.
The results: A clear path to better spatial reasoning
So, does training on this synthetic data actually work? To find out, we fine-tuned several MLLMs on a smaller subset of generated data (23,000 paths) taken from our dataset, including the open Gemma 3 27B and Gemini 2.5 Flash. We then evaluated their performance on MapBench, a popular benchmark composed of real-world maps the MLLMs had not seen during training.
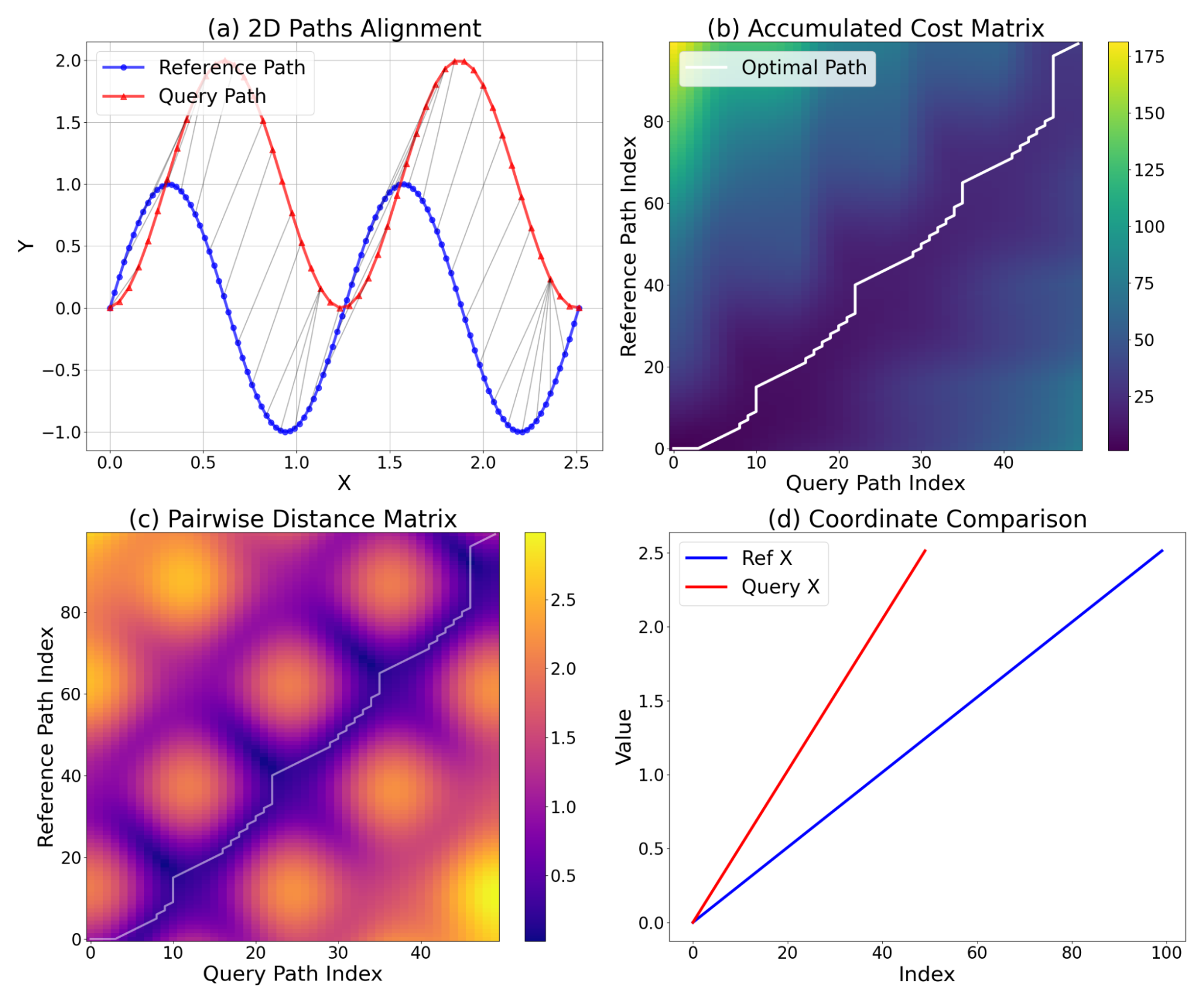
We measured the models’ path-tracing error using the normalized dynamic time warping (NDTW) metric, which is an extension of dynamic time warping used to compare two sequences of coordinates that can vary in speed (or number of points predicted, in this case). The output is then normalized by the total path length to obtain the final normalized metric, i.e., the distance between two paths with a lower value demonstrating better performance. The figure below shows how the NDTW metric is computed, detailing the alignment process. Figure (a) shows the 2D alignment of Reference Path (blue) and Query Path (red, shifted by Y=1.0 for visualization). Gray lines connect matching points identified by DTW, demonstrating the handling of the phase shift and sampling difference. Figure (b) and (c) show the accumulated cost matrix and the Pairwise Euclidean distance matrix, illustrating how the optimal warping path (white) tracks the lowest distance pairs to minimize the total alignment cost. Finally, figure (d) displays a 1D comparison of x-coordinates, highlighting the temporal alignment problem that DTW resolves: the signals have similar shapes but different sampling rates and temporal offsets.
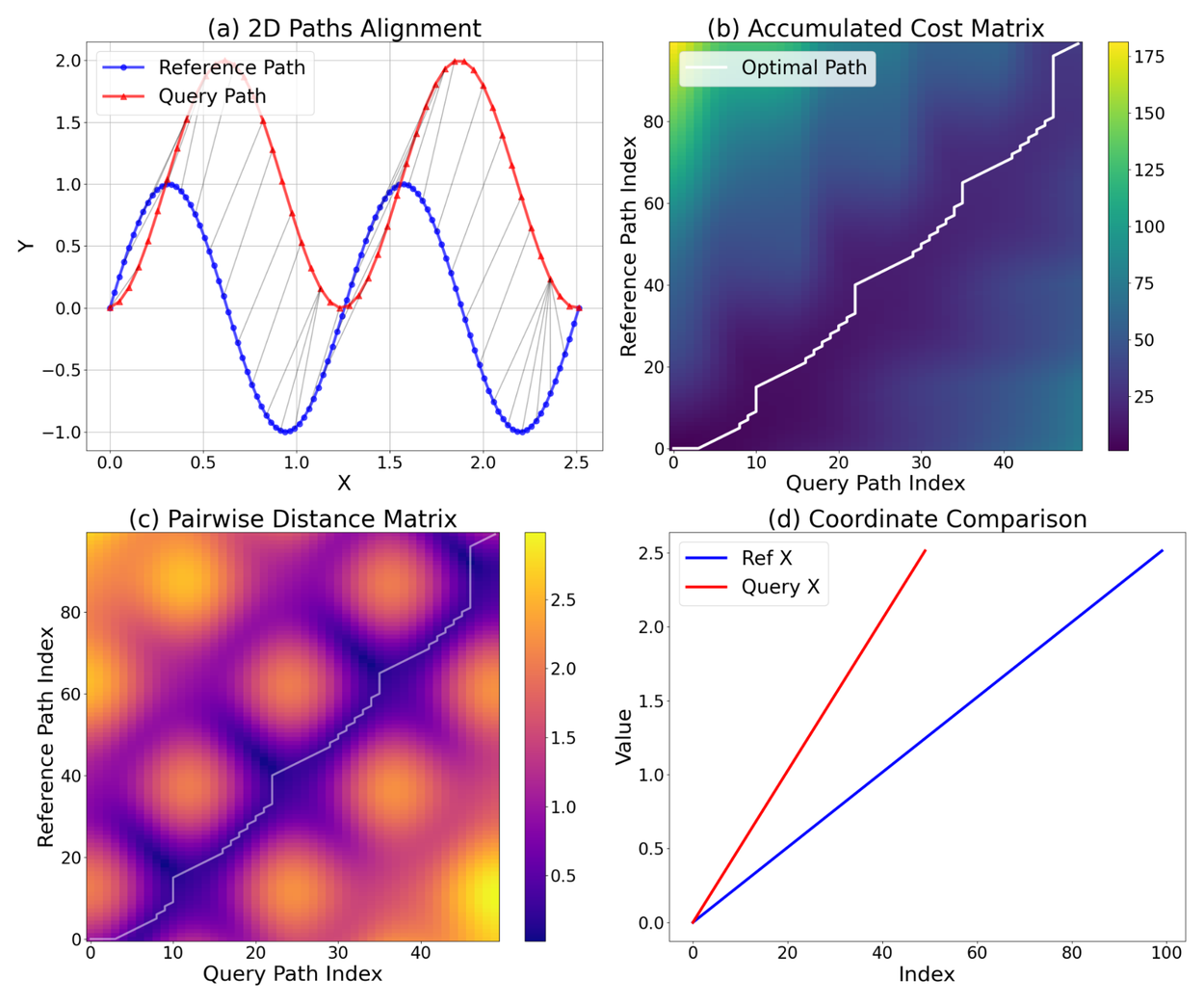
Dynamic time warping (DTW) analysis of two 2D paths.
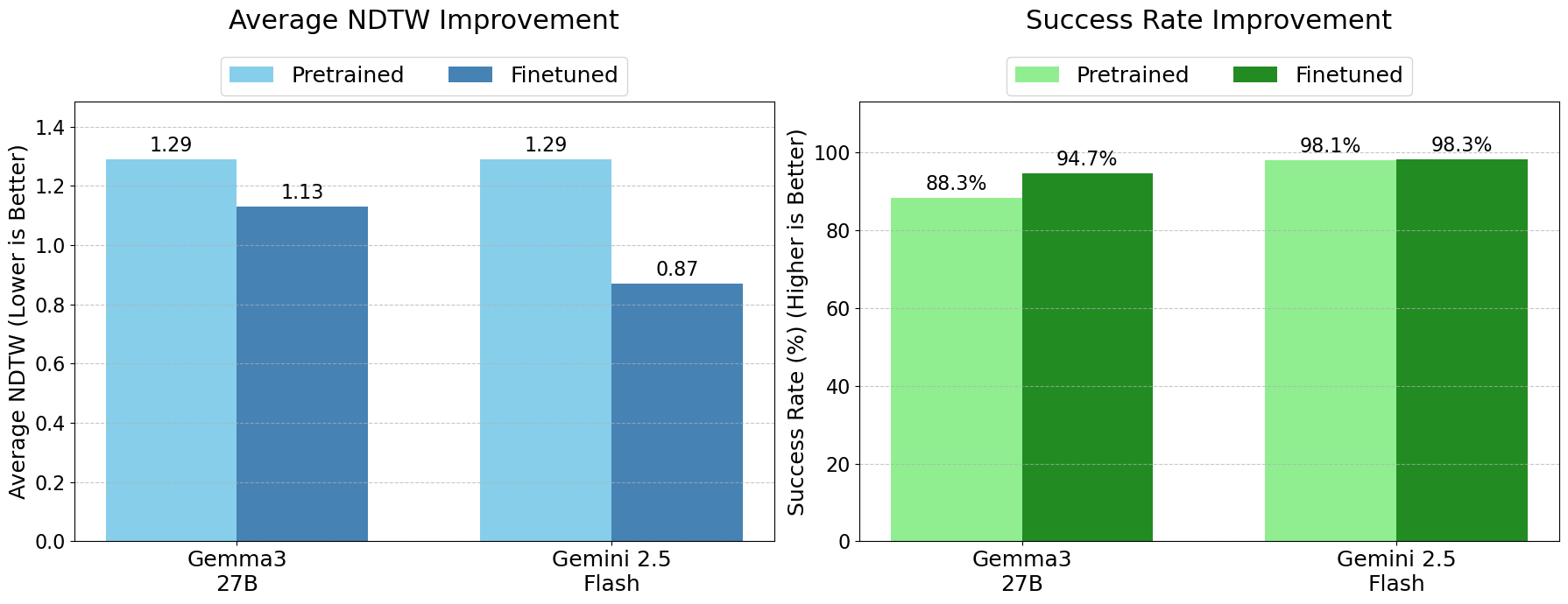
Fine-tuning on our dataset substantially improved the models' abilities across the board. The fine-tuned Gemini 2.5 Flash model, for example, saw its NDTW drop significantly (from 1.29 to 0.87), achieving the best overall performance.
More importantly, the models became far more reliable. The success rate, i.e., the percentage of time the model produced a valid, parsable path, rose for all models. The fine-tuned Gemma model saw a 6.4 point increase in its success rate and improved NDTW (1.29 to 1.13), a dramatic improvement that demonstrates a newfound robustness. This means that after training on our dataset, the models weren't just more accurate when they succeeded; they were far less likely to fail completely.
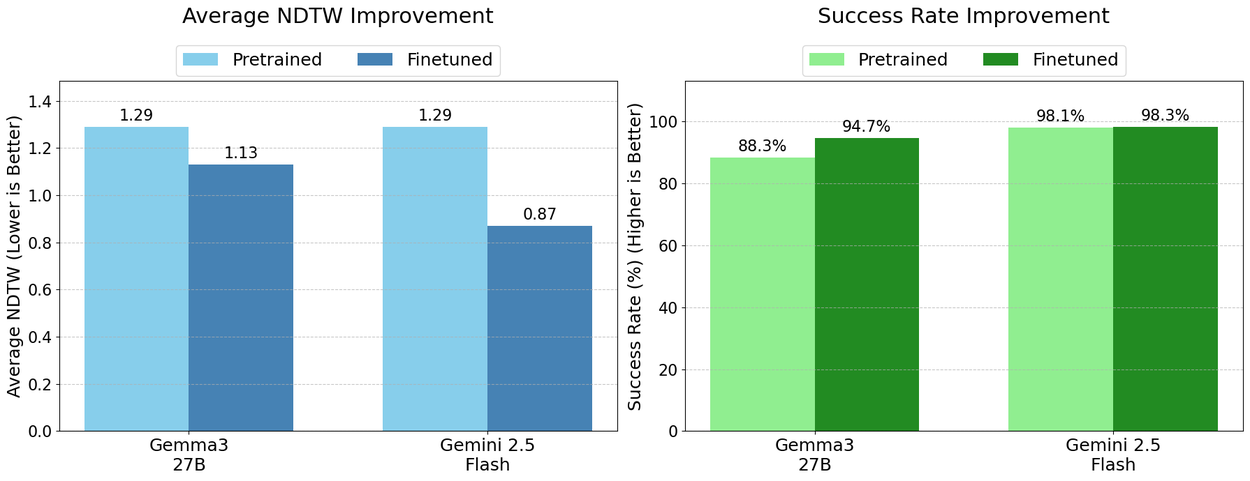
Quantifying the performance improvements on MapBench by training on the generated datasets. We report significant improvements on NDTW as well as the Success Rate (successfully finding a valid path).
These gains confirm our central hypothesis: fine-grained spatial reasoning is not an innate property of MLLMs but an acquired skill. With the right kind of explicit supervision, even if it's synthetically generated, we can teach models to understand and navigate spatial layouts.
Evaluating the performance of AI critics
For the Path Critic, we manually reviewed 120 decisions across 56 randomly sampled maps, achieving 76% accuracy with an 8% false-positive rate (invalid paths labeled as “high quality”). Errors mainly arose from 1) misclassifying background regions as traversable when colors resemble paths, and 2) missing thin valid paths within larger open regions. For the Mask Critic, we inspected 200 judgments over 20 maps, observing 83% accuracy and a 9% false-positive rate. Common errors included 1) background pixels included due to color similarity, 2) small non-path elements (e.g., text) absorbed into otherwise correct masks, and 3) thin valid paths labeled as invalid.
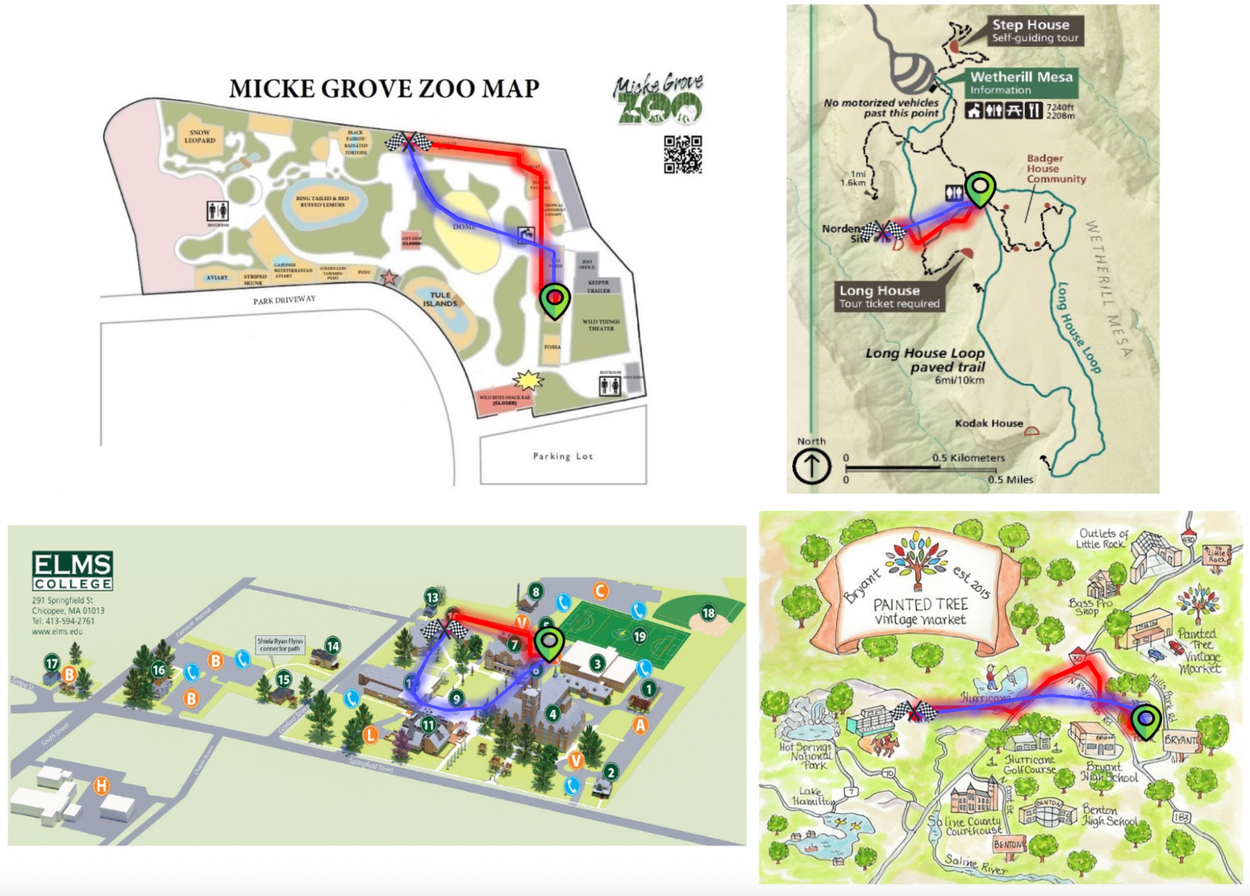
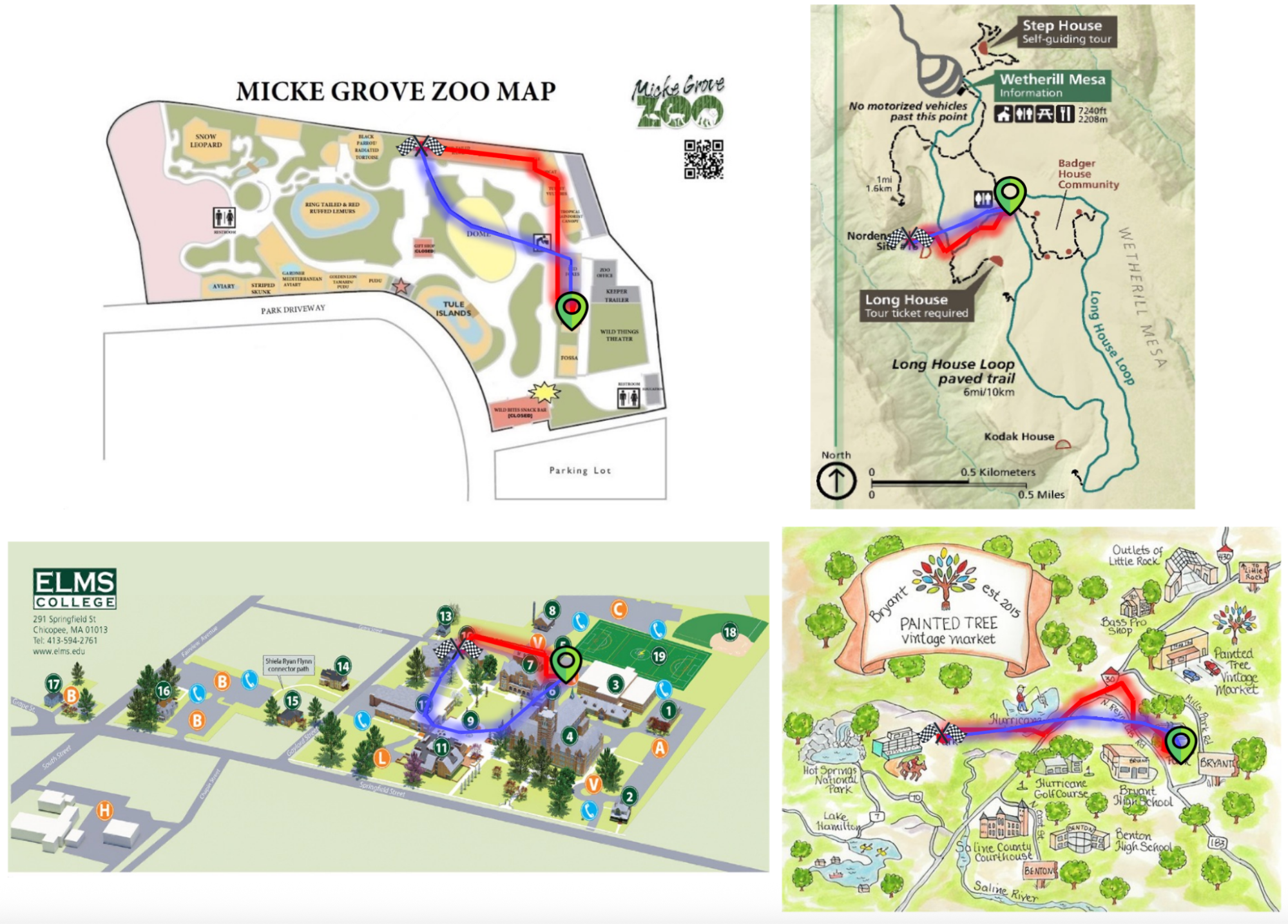
Qualitative examples comparing the fine-tuned Gemini-2.5-Flash (red) to the base model (blue). The fine-tuned model adheres more closely to the intended routes and avoids non-traversable regions.
What's next
The ability to reason about paths and connectivity unlocks a host of future applications. Including:
- More intuitive navigation tools: An AI model that can look at a satellite image or a complex subway map and give you truly intuitive, visually grounded directions.
- Smarter robotics and autonomous agents: Robots that can navigate complex indoor environments like warehouses, hospitals, or airports by simply looking at a floor plan.
- Enhanced accessibility: Tools that can describe a path through a building for a visually impaired person in a clear, step-by-step manner.
Acknowledgments
This research was conducted by Artemis Panagopoulou (while working as a Student Researcher at Google), Mohit Goyal, Soroosh Yazdani, Florian Dubost, Chen Chai, Achin Kulshrestha, and Aveek Purohit.
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets