Tackling Open Challenges in Offline Reinforcement Learning
August 20, 2020
Posted by George Tucker, Research Scientist and Sergey Levine, Faculty Advisor, Google Research
Quick links
Over the past several years, there has been a surge of interest in reinforcement learning (RL) driven by its high-profile successes in game playing and robotic control. However, unlike supervised learning methods, which learn from massive datasets that are collected once and then reused, RL algorithms use a trial-and-error feedback loop that requires active interaction during learning, collecting data every time a new policy is learned. This approach is prohibitive in many real-world settings, such as healthcare, autonomous driving, and dialogue systems, where trial-and-error data collection can be costly, time consuming, or even irresponsible. Even for problems where some active data collection can be used, the requirement for interactive collection limits dataset size and diversity.
Offline RL (also called batch RL or fully off-policy RL) relies solely on a previously collected dataset without further interaction. It provides a way to utilize previously collected datasets — from previous RL experiments, from human demonstrations, and from hand-engineered exploration strategies — in order to automatically learn decision-making strategies. In principle, while off-policy RL algorithms can be used in the offline setting (fully off-policy), they are generally only successful when used with active environment interaction — without receiving this direct feedback, they often exhibit undesirable performance in practice. Consequently, while offline RL has enormous potential, that potential cannot be reached without resolving significant algorithmic challenges.
In “Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems”, we provide a comprehensive tutorial on approaches for tackling the challenges of offline RL and discuss the many issues that remain. To address these issues, we have designed and released an open-source benchmarking framework, Datasets for Deep Data-Driven Reinforcement Learning (D4RL), as well as a new, simple, and highly effective offline RL algorithm, called conservative Q-learning (CQL).
Benchmarks for Offline RL
In order to understand the capabilities of current approaches and to guide future progress, it is first necessary to have effective benchmarks. A common choice in prior work was to simply use data generated by a successful online RL run. However, while simple, this data collection approach is artificial because it involves training an online RL agent which is prohibitive in many real-world settings as we discussed previously. One wishes to learn a policy that is better than the current best from diverse data sources that provides good coverage of the task. For example, one might have data collected from a hand-designed controller of a robot arm, and use offline RL to train an improved controller. To enable progress in this field under realistic settings, one needs a benchmark suite that accurately reflects these settings, while being simple and accessible enough to enable rapid experimentation.
D4RL provides standardized environments, datasets and evaluation protocols, as well as reference scores for recent algorithms to help accomplish this. This is a “batteries-included” resource, making it ideal for anyone to jump in and get started with minimal fuss.
 |
| Environments in D4RL |
The key design goal for D4RL was to develop tasks that reflect both real-world dataset challenges as well as real-world applications. Previous datasets used data collected either from random agents or agents trained with RL. Instead, by thinking through potential applications in autonomous driving, robotics, and other domains, we considered how real-world applications of offline RL might require handling of data generated from human demonstrations or hard-coded controllers, data collected from heterogeneous sources, and data collected by agents with a variety of different goals.
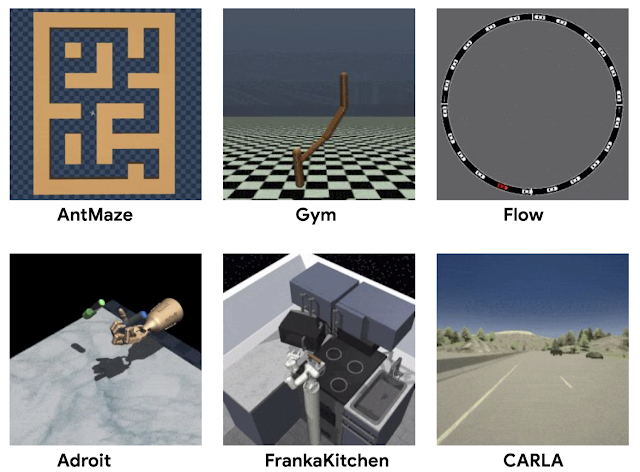
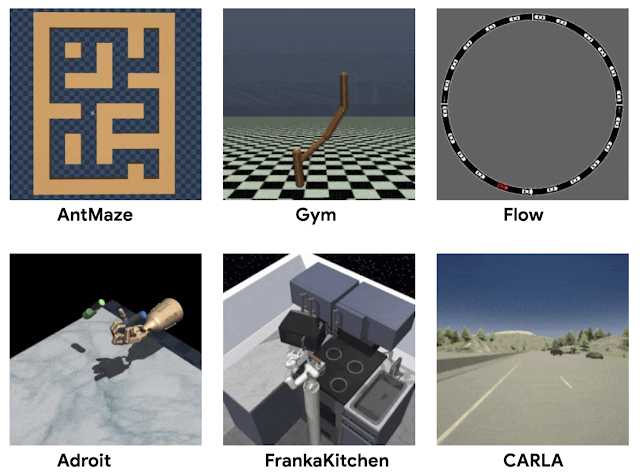
Aside from the widely used MuJoCo locomotion tasks, D4RL includes datasets for more complex tasks. The Adroit domain, which requires manipulating a realistic robotic hand to use a hammer, for example, illustrates the challenges of working with limited human demonstrations, without which these tasks are extremely challenging. Previous work found that existing datasets could not distinguish between competing methods, whereas the Adroit domain reveals clear deficiencies between them.
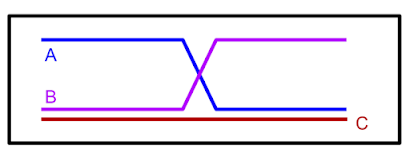
Another common scenario for real-world tasks is one in which the dataset used for training is collected from agents performing a wide range of other activities that are related to, but not specifically targeted towards, the task of interest. For example, data from human drivers may illustrate how to drive a car well, but do not necessarily show how to reach a specific desired destination. In this case, one might like offline RL methods to “stitch” together parts of routes in the driving dataset to accomplish a task that was not actually seen in the data (i.e., navigation). As an illustrative example, given paths labeled “A” and “B” in the picture below, offline RL should be able to “remix” them to produce path C.
 |
| Having only observed paths A and B, they can be combined to form a shortest path (C). |
We constructed a series of increasingly difficult tasks to exercise this “stitching” ability. The maze environments, shown below, require two robots (a simple ball or an “Ant” robot) to navigate to locations in a series of mazes.
 |
| Maze navigation environments in D4RL, which require “stitching” parts of paths to accomplish new navigational goals that were not seen in the dataset. |
A more complex “stitching” scenario is provided by the Franka kitchen domain (based on the Adept environment), where demonstrations from humans using a VR interface comprise a multi-task dataset, and offline RL methods must again “remix” this data.
 |
| The “Franka kitchen” domain requires using data from human demonstrators performing a variety of different tasks in a simulated kitchen. |
Finally, D4RL includes two tasks that are meant to more accurately reflect potential realistic applications of offline RL, both based on existing driving simulators. One is a first-person driving dataset that utilizes the widely used CARLA simulator developed at Intel, which provides photo-realistic images in realistic driving domains, and the other is a dataset from the Flow traffic control simulator (from UC Berkeley), which requires controlling autonomous vehicles to facilitate effective traffic flow.
 |
| D4RL includes datasets based on existing realistic simulators for driving with CARLA (left) and traffic management with Flow (right). |
We have packaged these tasks and standardized datasets into an easy-to-use Python package to accelerate research. Furthermore, we provide benchmark numbers for all tasks using relevant prior methods (BC, SAC, BEAR, BRAC, AWR, BCQ), in order to baseline new approaches. We are not the first to propose a benchmark for offline RL: a number of prior works have proposed simple datasets based on running RL algorithms, and several more recent works have proposed datasets with image observations and other features. However, we believe that the more realistic dataset composition in D4RL makes it an effective way to drive progress in the field.
An Improved Algorithm for Offline RL
As we developed the benchmark tasks, we found that existing methods could not solve the more challenging tasks. The central challenge arises from a distributional shift: in order to improve over the historical data, offline RL algorithms must learn to make decisions that differ from the decisions taken in the dataset. However, this can lead to problems when the consequences of a seemingly good decision cannot be deduced from the data — if no agent has taken this particular turn in the maze, how does one know if it leads to the goal or not? Without handling this distributional shift problem, offline RL methods can extrapolate erroneously, making over-optimistic conclusions about the outcomes of rarely seen actions. Contrast this with the online setting, where reward bonuses modeled after curiosity and surprise optimistically bias the agent to explore all potentially rewarding paths. Because the agent receives interactive feedback, if the action turns out to be unrewarding, then it can simply avoid the path in the future.
To address this, we developed conservative Q-learning (CQL), an offline RL algorithm designed to guard against overestimation while avoiding explicit construction of a separate behavior model and without using importance weights. While standard Q-learning (and actor-critic) methods bootstrap from previous estimates, CQL is unique in that it is fundamentally a pessimistic algorithm: it assumes that if a good outcome was not seen for a given action, that action is likely to not be a good one. The central idea of CQL is to learn a lower bound on the policy’s expected return (called the Q-function), instead of learning to approximate the expected return. If we then optimize our policy under this conservative Q-function, we can be confident that its value is no lower than this estimate, preventing errors from overestimation.
We found that CQL attains state-of-the-art results on many of the harder D4RL tasks: CQL outperformed other approaches on the AntMaze, Kitchen tasks, and 6 out of 8 Adroit tasks. In particular, on the AntMaze tasks, which require navigating through a maze with an “Ant” robot, CQL is often the only algorithm that is able to learn non-trivial policies. CQL also performs well on other tasks, including Atari games. On the Atari tasks from Agarwal et al., CQL outperforms prior methods when data is limited (“1%” dataset). Moreover, CQL is simple to implement on top of existing algorithms (e.g., QR-DQN and SAC), without training additional neural networks.
 |
| Performance of CQL on Atari games with the 1% dataset from Agarwal et al. |
Future Thoughts
We are excited about the fast-moving field of offline RL. While we took a first step towards a standard benchmark, there is clearly still room for improvement. We expect that as algorithms improve, we will need to reevaluate the tasks in the benchmark and develop more challenging tasks. We look forward to working with the community to evolve the benchmark and evaluation protocols. Together, we can bring the rich promises of offline RL to real-world applications.
Acknowledgements
This work was carried out in collaboration with UC Berkeley PhD students Aviral Kumar, Justin Fu, and Aurick Zhou, with contributions from Ofir Nachum from Google Research.
-
Labels:
- Open Source Models & Datasets
Quick links
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets