Summary report optimization in the Privacy Sandbox Attribution Reporting API
December 4, 2023
Hidayet Aksu, Software Engineer, and Adam Sealfon, Research Scientist, Google
Quick links
In recent years, the Privacy Sandbox initiative was launched to explore responsible ways for advertisers to measure the effectiveness of their campaigns, by aiming to deprecate third-party cookies (subject to resolving any competition concerns with the UK’s Competition and Markets Authority). Cookies are small pieces of data containing user preferences that websites store on a user’s device; they can be used to provide a better browsing experience (e.g., allowing users to automatically sign in) and to serve relevant content or ads. The Privacy Sandbox attempts to address concerns around the use of cookies for tracking browsing data across the web by providing a privacy-preserving alternative.
Many browsers use differential privacy (DP) to provide privacy-preserving APIs, such as the Attribution Reporting API (ARA), that don’t rely on cookies for ad conversion measurement. ARA encrypts individual user actions and collects them in an aggregated summary report, which estimates measurement goals like the number and value of conversions (useful actions on a website, such as making a purchase or signing up for a mailing list) attributed to ad campaigns.
The task of configuring API parameters, e.g., allocating a contribution budget across different conversions, is important for maximizing the utility of the summary reports. In “Summary Report Optimization in the Privacy Sandbox Attribution Reporting API”, we introduce a formal mathematical framework for modeling summary reports. Then, we formulate the problem of maximizing the utility of summary reports as an optimization problem to obtain the optimal ARA parameters. Finally, we evaluate the method using real and synthetic datasets, and demonstrate significantly improved utility compared to baseline non-optimized summary reports.
ARA summary reports
We use the following example to illustrate our notation. Imagine a fictional gift shop called Du & Penc that uses digital advertising to reach its customers. The table below captures their holiday sales, where each record contains impression features with (i) an impression ID, (ii) the campaign, and (iii) the city in which the ad was shown, as well as conversion features with (i) the number of items purchased and (ii) the total dollar value of those items.
Impression and conversion feature logs for Du & Penc.
Mathematical model
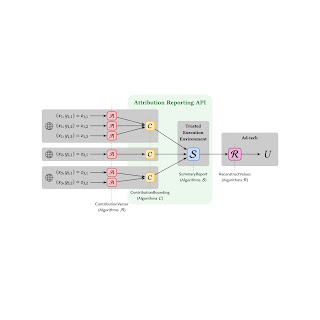
ARA summary reports can be modeled by four algorithms: (1) Contribution Vector, (2) Contribution Bounding, (3) Summary Reports, and (4) Reconstruct Values. Contribution Bounding and Summary Reports are performed by the ARA, while Contribution Vector and Reconstruct Values are performed by an AdTech provider — tools and systems that enable businesses to buy and sell digital advertising. The objective of this work is to assist AdTechs in optimizing summary report algorithms.
The Contribution Vector algorithm converts measurements into an ARA format that is discretized and scaled. Scaling needs to account for the overall contribution limit per impression. Here we propose a method that clips and performs randomized rounding. The outcome of the algorithm is a histogram of aggregatable keys and values.
Next, the Contribution Bounding algorithm runs on client devices and enforces the contribution bound on attributed reports where any further contributions exceeding the limit are dropped. The output is a histogram of attributed conversions.
The Summary Reports algorithm runs on the server side inside a trusted execution environment and returns noisy aggregate results that satisfy DP. Noise is sampled from the discrete Laplace distribution, and to enforce privacy budgeting, a report may be queried only once.
Finally, the Reconstruct Values algorithm converts measurements back to the original scale. Reconstruct Values and Contribution Vector Algorithms are designed by the AdTech, and both impact the utility received from the summary report.
Illustrative usage of ARA summary reports, which include Contribution Vector (Algorithm A), Contribution Bounding (Algorithm C), Summary Reports (Algorithm S), and Reconstruct Values (Algorithm R). Algorithms C and S are fixed in the API. The AdTech designs A and R.
Error metrics
There are several factors to consider when selecting an error metric for evaluating the quality of an approximation. To choose a particular metric, we considered the desirable properties of an error metric that further can be used as an objective function. Considering desired properties, we have chosen 𝜏-truncated root mean square relative error (RMSRE𝜏) as our error metric for its properties. See the paper for a detailed discussion and comparison to other possible metrics.
Optimization
To optimize utility as measured by RMSRE𝜏, we choose a capping parameter, C, and privacy budget, 𝛼, for each slice. The combination of both determines how an actual measurement (such as two conversions with a total value of $3) is encoded on the AdTech side and then passed to the ARA for Contribution Bounding algorithm processing. RMSRE𝜏 can be computed exactly, since it can be expressed in terms of the bias from clipping and the variance of the noise distribution. Following those steps we find out that RMSRE𝜏 for a fixed privacy budget, 𝛼, or a capping parameter, C, is convex (so the error-minimizing value for the other parameter can be obtained efficiently), while for joint variables (C, 𝛼) it becomes non-convex (so we may not always be able to select the best possible parameters). In any case, any off-the-shelf optimizer can be used to select privacy budgets and capping parameters. In our experiments, we use the SLSQP minimizer from the scipy.optimize library.
Synthetic data
Different ARA configurations can be evaluated empirically by testing them on a conversion dataset. However, access to such data can be restricted or slow due to privacy concerns, or simply unavailable. One way to address these limitations is to use synthetic data that replicates the characteristics of real data.
We present a method for generating synthetic data responsibly through statistical modeling of real-world conversion datasets. We first perform an empirical analysis of real conversion datasets to uncover relevant characteristics for ARA. We then design a pipeline that uses this distribution knowledge to create a realistic synthetic dataset that can be customized via input parameters.
The pipeline first generates impressions drawn from a power-law distribution (step 1), then for each impression it generates conversions drawn from a Poisson distribution (step 2) and finally, for each conversion, it generates conversion values drawn from a log-normal distribution (step 3). With dataset-dependent parameters, we find that these distributions closely match ad-dataset characteristics. Thus, one can learn parameters from historical or public datasets and generate synthetic datasets for experimentation.
Overall dataset generation steps with features for illustration.
Experimental evaluation
We evaluate our algorithms on three real-world datasets (Criteo, AdTech Real Estate, and AdTech Travel) and three synthetic datasets. Criteo consists of 15M clicks, Real Estate consists of 100K conversions, and Travel consists of 30K conversions. Each dataset is partitioned into a training set and a test set. The training set is used to choose contribution budgets, clipping threshold parameters, and the conversion count limit (the real-world datasets have only one conversion per click), and the error is evaluated on the test set. Each dataset is partitioned into slices using impression features. For real-world datasets, we consider three queries for each slice; for synthetic datasets, we consider two queries for each slice.
For each query we choose the RMSRE𝝉 𝜏 value to be five times the median value of the query on the training dataset. This ensures invariance of the error metric to data rescaling, and allows us to combine the errors from features of different scales by using 𝝉 per each feature.
Scatter plots of real-world datasets illustrating the probability of observing a conversion value. The fitted curves represent best log-normal distribution models that effectively capture the underlying patterns in the data.
Results
We compare our optimization-based algorithm to a simple baseline approach. For each query, the baseline uses an equal contribution budget and a fixed quantile of the training data to choose the clipping threshold. Our algorithms produce substantially lower error than baselines on both real-world and synthetic datasets. Our optimization-based approach adapts to the privacy budget and data.
RMSREτ for privacy budgets {1, 2, 4, 8, 16, 32, 64} for our algorithms and baselines on three real-world and three synthetic datasets. Our optimization-based approach consistently achieves lower error than baselines that use a fixed quantile for the clipping threshold and split the contribution budget equally among the queries.
Conclusion
We study the optimization of summary reports in the ARA, which is currently deployed on hundreds of millions of Chrome browsers. We present a rigorous formulation of the contribution budgeting optimization problem for ARA with the goal of equipping researchers with a robust abstraction that facilitates practical improvements.
Our recipe, which leverages historical data to bound and scale the contributions of future data under differential privacy, is quite general and applicable to settings beyond advertising. One approach based on this work is to use past data to learn the parameters of the data distribution, and then to apply synthetic data derived from this distribution for privacy budgeting for queries on future data. Please see the paper and accompanying code for detailed algorithms and proofs.
Acknowledgements
This work was done in collaboration with Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, and Avinash Varadarajan. We thank Akash Nadan for his help.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 7, 2026
The power of collaboration: How we can reduce traffic congestion- Algorithms & Theory ·
- Climate & Sustainability ·
- Data Mining & Modeling
-

June 25, 2026
Optimizing cloud economics with linear elastic caching- Algorithms & Theory ·
- Data Management