Speeding Up Neural Network Training with Data Echoing
May 12, 2020
Posted by Dami Choi, Student Researcher and George Dahl, Senior Research Scientist, Google Research
Quick links
Over the past decade, dramatic increases in neural network training speed have made it possible to apply deep learning techniques to many important problems. In the twilight of Moore's law, as improvements in general purpose processors plateau, the machine learning community has increasingly turned to specialized hardware to produce additional speedups. For example, GPUs and TPUs optimize for highly parallelizable matrix operations, which are core components of neural network training algorithms. These accelerators, at a high level, can speed up training in two ways. First, they can process more training examples in parallel, and second, they can process each training example faster. We know there are limits to the speedups from processing more training examples in parallel, but will building ever faster accelerators continue to speed up training?
Unfortunately, not all operations in the training pipeline run on accelerators, so one cannot simply rely on faster accelerators to continue driving training speedups. For example, earlier stages in the training pipeline like disk I/O and data preprocessing involve operations that do not benefit from GPUs and TPUs. As accelerator improvements outpace improvements in CPUs and disks, these earlier stages will increasingly become a bottleneck, wasting accelerator capacity and limiting training speed.
 |
| An example training pipeline representative of many large-scale computer vision programs. The stages that come before applying the mini-batch stochastic gradient descent (SGD) update generally do not benefit from specialized hardware accelerators. |
In “Faster Neural Network Training with Data Echoing”, we propose a simple technique that reuses (or “echoes”) intermediate outputs from earlier pipeline stages to reclaim idle accelerator capacity. Rather than waiting for more data to become available, we simply utilize data that is already available to keep the accelerators busy.
 |
| Left: Without data echoing, downstream computational capacity is idle 50% of the time. Right: Data echoing with echoing factor 2 reclaims downstream computational capacity. |
Imagine a situation where reading and preprocessing a batch of training data takes twice as long as performing a single optimization step on that batch. In this case, after the first optimization step on the preprocessed batch, we can reuse the batch and perform a second step before the next batch is ready. In the best case scenario, where repeated data is as useful as fresh data, we would see a twofold speedup in training. In reality, data echoing provides a slightly smaller speedup because repeated data is not as useful as fresh data – but it can still provide a significant speedup compared to leaving the accelerator idle.
There are typically several ways to implement data echoing in a given neural network training pipeline. The technique we propose involves duplicating data into a shuffle buffer somewhere in the training pipeline, but we are free to insert this buffer anywhere after whichever stage produces a bottleneck in the given pipeline. When we insert the buffer before batching, we call our technique example echoing, whereas, when we insert it after batching, we call our technique batch echoing. Example echoing shuffles data at the example level, while batch echoing shuffles the sequence of duplicate batches. We can also insert the buffer before data augmentation, such that each copy of repeated data is slightly different (and therefore closer to a fresh example). Of the different versions of data echoing that place the shuffle buffer between different stages, the version that provides the greatest speedup depends on the specific training pipeline.
Data Echoing Across Workloads
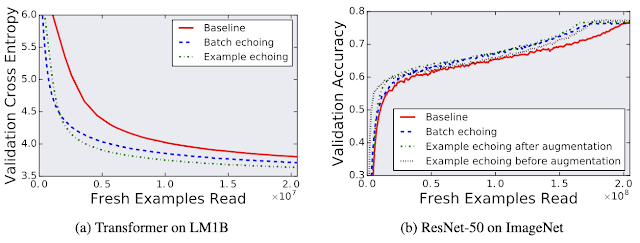
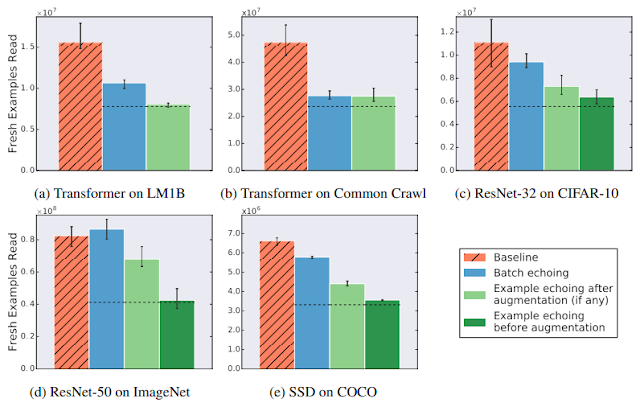
So how useful is reusing data? We tried data echoing on five neural network training pipelines spanning 3 different tasks – image classification, language modeling, and object detection – and measured the number of fresh examples needed to reach a particular performance target. We chose targets to match the best result reliably achieved by the baseline during hyperparameter tuning. We found that data echoing allowed us to reach the target performance with fewer fresh examples, demonstrating that reusing data is useful for reducing disk I/O across a variety of tasks. In some cases, repeated data is nearly as useful as fresh data: in the figure below, example echoing before augmentation reduces the number of fresh examples required almost by the repetition factor.
 |
| Data echoing, when each data item is repeated twice, either reduces or does not change the number of fresh examples needed to reach the target out-of-sample performance. Dashed lines indicate the values we would expect if repeated examples were as useful as fresh examples. |
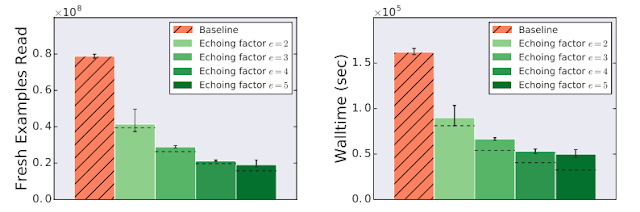
Data echoing can speed up training whenever computation upstream from accelerators dominates training time. We measured the training speedup achieved in a training pipeline bottlenecked by input latency due to streaming training data from cloud storage, which is realistic for many of today’s large-scale production workloads or anyone streaming training data over a network from a remote storage system. We trained a ResNet-50 model on the ImageNet dataset and found that data echoing provides a significant training speedup, in this case, more than 3 times faster when using data echoing.
 |
| Data echoing can reduce training time for ResNet-50 on ImageNet. In this experiment, reading a batch of training data from cloud storage took 6 times longer than the code that used each batch of data to perform a training step. The Echoing factor in the legend refers to the number of times each data item was repeated. Dashed lines indicate the expected values if repeated examples were as useful as fresh examples and there was no overhead from echoing. |
Although one might be concerned that reusing data would harm the model’s final performance, we found that data echoing did not degrade the quality of the final model for any of the workloads we tested.
 |
| Comparing the individual trials that achieved the best out-of-sample performance during training for both with and without data echoing shows that reusing data does not harm final model quality. Here validation cross entropy is equivalent to log perplexity. |
Acknowledgements
The Data Echoing project was conducted by Dami Choi, Alexandre Passos, Christopher J. Shallue, and George E. Dahl while Dami Choi was a Google AI Resident. We would also like to thank Roy Frostig, Luke Metz, Yiding Jiang, and Ting Chen for helpful discussions.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯