
Speech-to-Retrieval (S2R): A new approach to voice search
October 7, 2025
Ehsan Variani and Michael Riley, Research Scientists, Google Research
Voice Search is now powered by our new Speech-to-Retrieval engine, which gets answers straight from your spoken query without having to convert it to text first, resulting in a faster, more reliable search for everyone.
Quick links
Voice-based web search has been around a long time and continues to be used by many people, with the underlying technology evolving rapidly to allow for expanded use cases. Google’s initial voice search solution used automatic speech recognition (ASR) to turn the voice input into a text query, and then searched for documents matching that text query. However, a challenge with this cascade modeling approach is that any slight errors in the speech recognition phase can significantly alter the meaning of the query, producing the wrong results.
For example, imagine someone does a voice-based web search for the famous painting, “The Scream”, by Edvard Munch. The search engine uses the typical approach of cascade modeling, first converting the voice query to text via ASR before passing the text to the search system. Ideally, the ASR transcribes the query perfectly. The search system then receives the correct text — “the Scream painting” — and provides relevant results, like the painting’s history, its meaning, and where it’s displayed. However, what if the ASR system mistakes the “m” of “scream” for an “n”? It misinterprets the query as “screen painting” and returns irrelevant results about screen painting techniques instead of details about Munch's masterpiece.
ASR accuracy is key for voice search. See what happens when a system correctly transcribes a query versus when it transcribes it incorrectly.
To prevent such errors in web search systems, what if the system could map directly from speech to the desired retrieval intent, bypassing the textual transcription entirely?
Enter Speech-to-Retrieval (S2R). At its core, S2R is a technology that directly interprets and retrieves information from a spoken query without the intermediate, and potentially flawed, step of having to create a perfect text transcript. It represents a fundamental architectural and philosophical shift in how machines process human speech. Where today's common voice search technologies are focused on the question, "What words were said?", S2R is designed to answer a more powerful question: "What information is being sought?" This post explores the substantial quality gap in current voice search experiences and demonstrates how the S2R model is poised to fill it. In addition, we are open-sourcing the Simple Voice Questions (SVQ) dataset, a collection of short audio questions recorded in 17 different languages and 26 locales, which we used to evaluate the performance potential of S2R. The SVQ dataset is part of the new Massive Sound Embedding Benchmark benchmark.
Evaluating the potential of S2R
When a traditional ASR system converts audio into a single text string, it may lose contextual cues that could help disambiguate the meaning (i.e., information loss). If the system misinterprets the audio early on, that error is passed along to the search engine, which typically lacks the ability to correct it (i.e., error propagation). As a result, the final search result may not reflect the user's intent.
To investigate this relationship, we conducted an experiment designed to simulate an ideal ASR performance. We began by collecting a representative set of test queries reflecting typical voice search traffic. Crucially, these queries were then manually transcribed by human annotators, effectively creating a "perfect ASR" scenario where the transcription is the absolute truth.
We then established two distinct search systems for comparison (see chart below):
- Cascade ASR represents a typical real-world setup, where speech is converted to text by an automatic speech recognition (ASR) system, and that text is then fed to a retrieval system.
- Cascade groundtruth simulates a "perfect" cascade model by sending the flawless ground-truth text directly to the same retrieval system.
The retrieved documents from both systems (cascade ASR and cascade groundtruth) were then presented to human evaluators, or "raters", alongside the original true query. The evaluators were tasked with comparing the search results from both systems, providing a subjective assessment of their respective quality.
We use word error rate (WER) to measure the ASR quality and to measure the search performance, we use mean reciprocal rank (MRR) — a statistical metric for evaluating any process that produces a list of possible responses to a sample of queries, ordered by probability of correctness and calculated as the average of the reciprocals of the rank of the first correct answer across all queries. The difference in MRR and WER between the real-world system and the groundtruth system reveals the potential performance gains across some of the most commonly used voice search languages in the SVQ dataset (shown below).
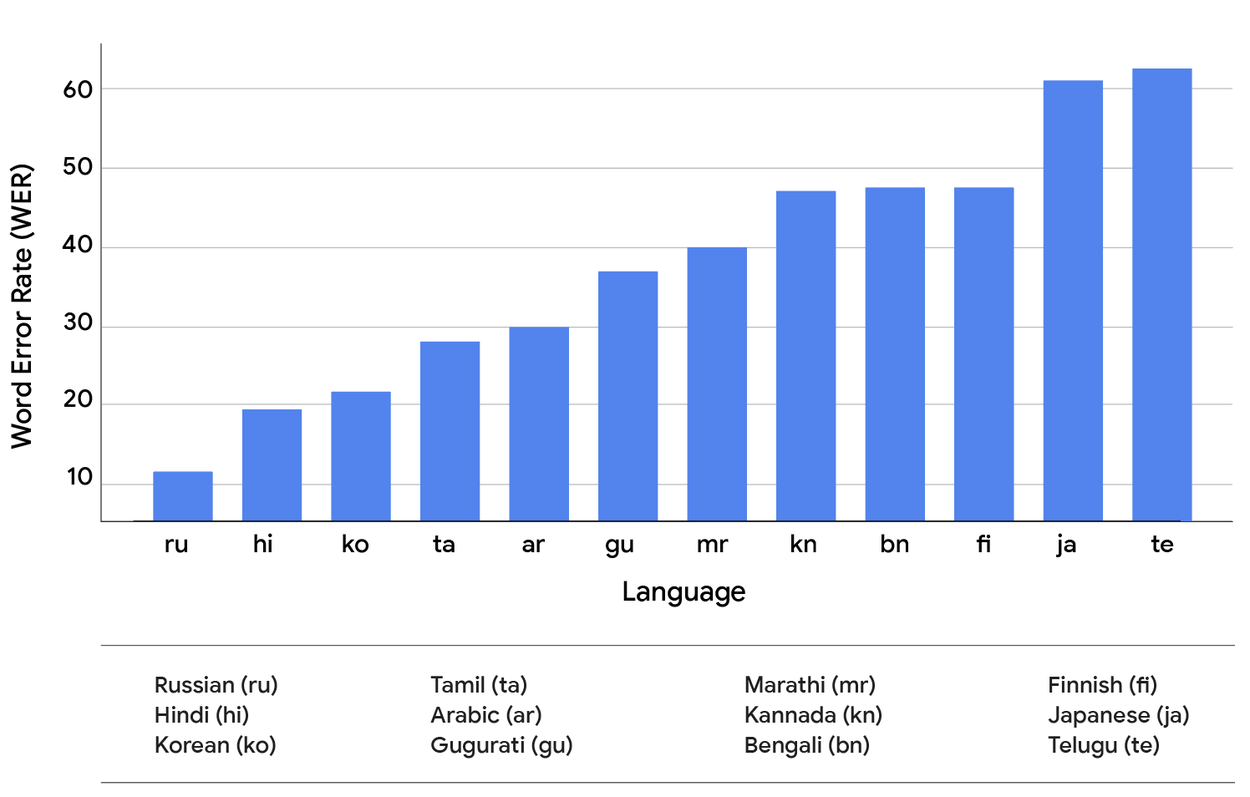
The word error rate (WER) of the ASR model across voice search languages in the SVQ dataset.
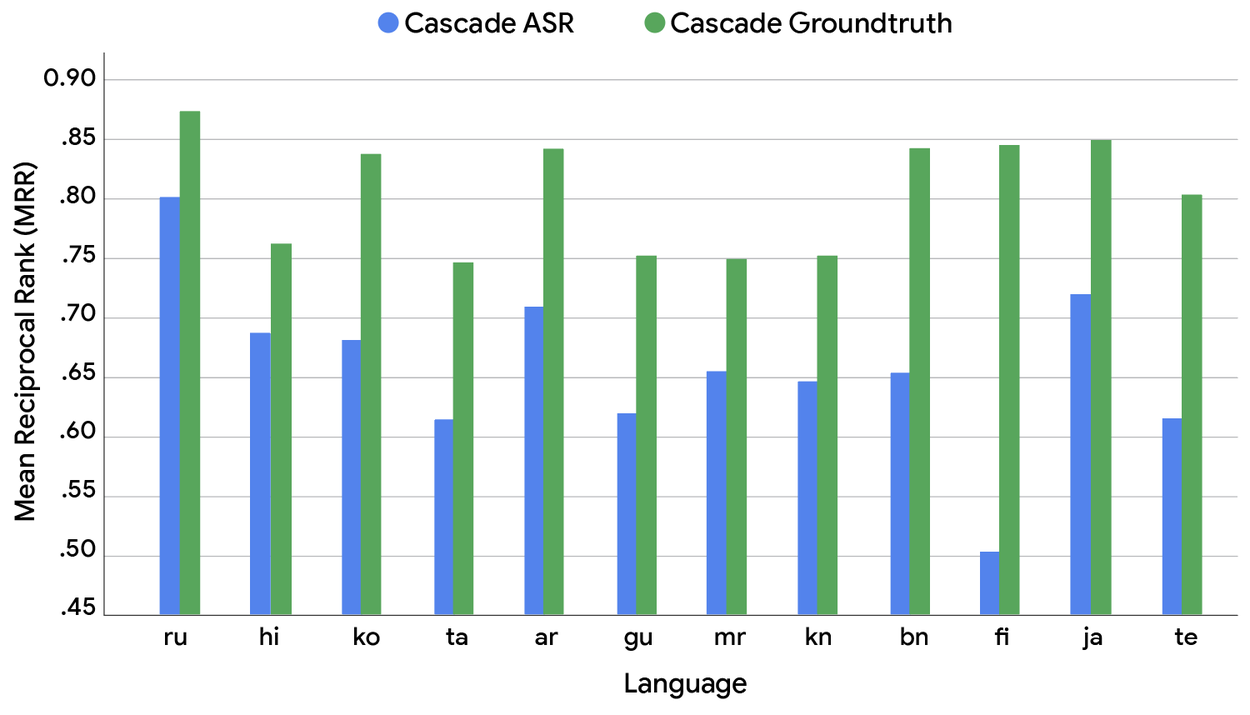
MRR of current real-world (“Cascade ASR”; blue) models vs ground truth (i.e., perfect; “Cascade Groundtruth”; green).
The results of this comparison lead to two critical observations. First, and as can be seen by comparing both charts above, we found that a lower WER does not reliably lead to a higher MRR across different languages. The relationship is complex, suggesting that the impact of transcription errors on downstream tasks is not fully captured by the WER metric. The specific nature of an error — not just its existence — appears to be a critical, language-dependent factor. Second, and more importantly, there’s a significant MRR difference between the two systems across all tested languages. This reveals a substantial performance gap between current cascade designs and what is theoretically possible with perfect speech recognition. This gap represents the clear potential for S2R models to fundamentally improve voice search quality.
The architecture of S2R: From sound to meaning
At the heart of our S2R model is a dual-encoder architecture. This design features two specialized neural networks that learn from vast amounts of data to understand the relationship between speech and information. An audio encoder processes the raw audio of a query, converting it into a rich vector representation that captures its semantic meaning. In parallel, a document encoder learns a similar vector representation for documents.
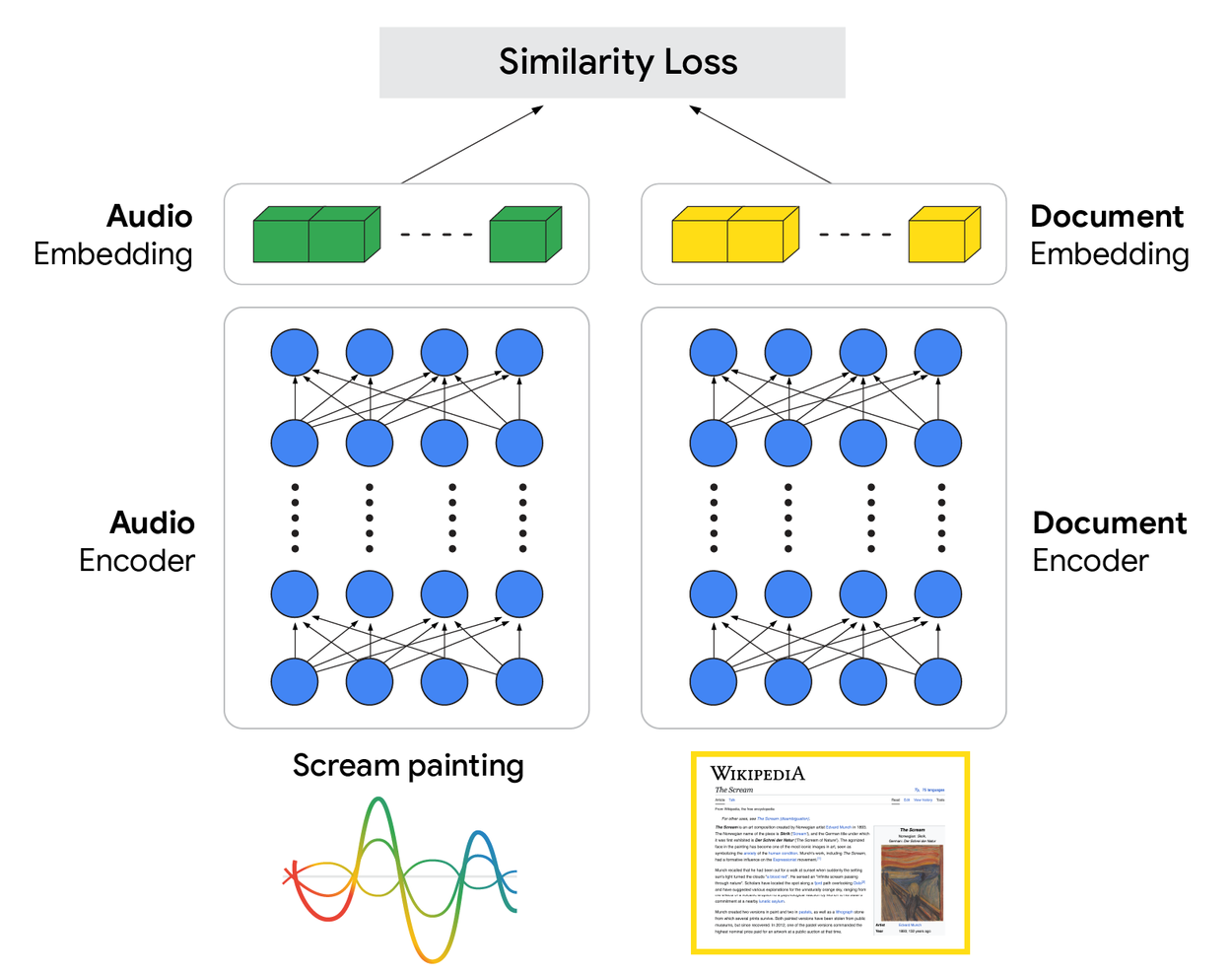
Difference in similarity loss between audio and document embedding.
The key to this model is how it is trained. Using a large dataset of paired audio queries and relevant documents, the system learns to adjust the parameters of both encoders simultaneously.
The training objective ensures that the vector for an audio query is geometrically close to the vectors of its corresponding documents in the representation space. This architecture allows the model to learn something closer to the essential intent required for retrieval directly from the audio, bypassing the fragile intermediate step of transcribing every word, which is the principal weakness of the cascade design.
How the S2R model works
When a user speaks a query, the audio is streamed to the pre-trained audio encoder, which generates a query vector. This vector is then used to efficiently identify a highly relevant set of candidate results from our index through a complex search ranking process.
How S2R processes a spoken query.
The animation above illustrates how S2R understands and answers a spoken query. It starts with a user's voice request for “The Scream painting”. An audio encoder translates the sound into a rich audio embedding, a vector that represents the deep meaning of the query. This embedding is then used to scan a massive index of documents, surfacing initial candidates with high similarity scores, like the Wikipedia page for “The Scream” (0.8) and the Munch Museum website (0.7).
But finding relevant documents is just the beginning. The crucial final step is orchestrated by the search ranking system. This powerful intelligence goes far beyond the initial scores, weaving them together with hundreds of other signals to deeply understand relevance and quality. It weighs all this information in a fraction of a second to choreograph the final ranking, ensuring the most helpful and trustworthy information is presented to the user.
Evaluating S2R
We evaluated the S2R system described above on the SVQ dataset:
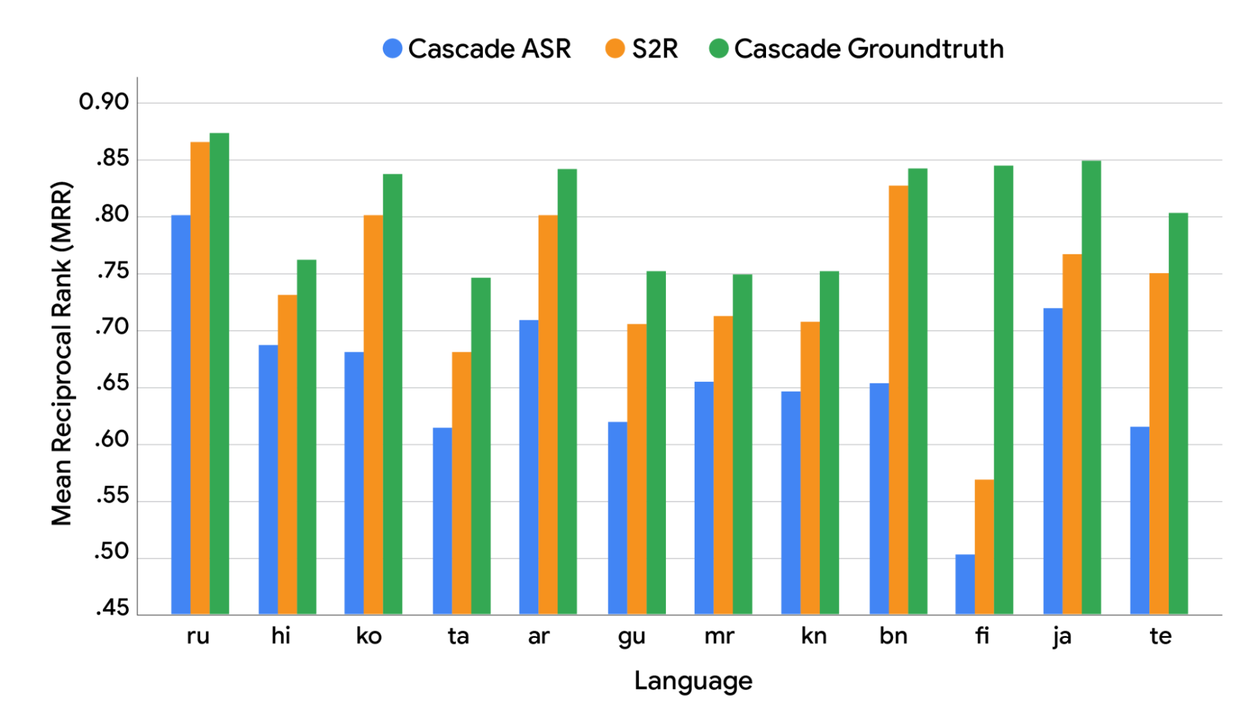
MRR of current real-world (“Cascade ASR”; blue) models vs ground truth (i.e., perfect; “Cascade Groundtruth”; green) and the S2R model's performance ("S2R" orange bar).
The S2R model's performance (orange bar) shows two key results:
- It significantly outperforms the baseline cascade ASR model.
- Its performance approaches the upper bound established by the cascade ground truth model.
While promising, the remaining gap indicates that further research is required.
The new era for voice search is now live
The move to S2R-powered voice search isn’t a theoretical exercise; it’s a live reality. In a close collaboration between Google Research and Search, these advanced models are now serving users in multiple languages, delivering a significant leap in accuracy beyond conventional cascade systems.
To help propel the entire field forward, we are also open-sourcing the SVQ dataset as part of the Massive Sound Embedding Benchmark (MSEB). We believe shared resources and transparent evaluation accelerates progress. In that spirit, we invite the global research community to use this data, test new approaches on public benchmarks, and join the effort to build the next generation of truly intelligent voice interfaces.
Acknowledgements
The authors sincerely thank all who contributed to this project, whose critical input made it possible. We are especially grateful to our colleagues Hawi Abraham, Cyril Allauzen, Tom Bagby, Karthik Kumar Bandi, Stefan Buettcher, Dave Dopson, Lucy Hadden, Georg Heigold, Sanjit Jhala, Shankar Kumar, Ji Ma, Eyal Mizrachi, Pandu Nayak, Pew Putthividhya, David Rybach, Jungshik Shin, Venkat Subramanian, Sundeep Tirumalareddy and Trystan Upstill. We also wish to acknowledge those who helped prepare this post: Mark Simborg for his extensive editing, Kimberly Schwede for the wonderful illustrations, and Mickey Wurts for his valuable assistance.
Quick links
Other posts of interest
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence



