Speculative RAG: Enhancing retrieval augmented generation through drafting
August 21, 2024
Zilong Wang, Student Researcher, and Chen-Yu Lee, Research Scientist, Cloud AI Team
Quick links
Large language models (LLMs) are increasingly being used to power services that can respond to user inquiries. Yet despite their widespread use, LLMs often struggle with factual inaccuracies and may generate hallucinated content (i.e., descriptions that cannot be verified by a given input), particularly when faced with knowledge-intensive questions that demand up-to-date information or obscure facts. For example, if a user asks, “What are the new features of the latest Google Pixel phone?”, an LLM might generate outdated or inaccurate information.
Retrieval augmented generation (RAG) recently emerged as a promising solution to mitigate these issues. RAG leverages an external knowledge base to retrieve documents with related information, and incorporates this information into its generated content. By retrieving timely and accurate information, RAG effectively reduces factual errors in knowledge-intensive tasks. While RAG improves the accuracy of LLM responses, longer documents require more complex reasoning and can significantly delay response times. Recent studies have explored paths to extend the context length limit of LLMs, yet achieving well-grounded reasoning over such extended contexts remains an open challenge. Consequently, striking a balance between efficiency and effectiveness in RAG has become a central research focus.
In “Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting”, we propose a novel framework that offloads computational burden to a smaller specialist RAG drafter (a specialized LM fine-tuned for RAG), which serves as an efficient and robust RAG module for the existing generalist LM.
Speculative RAG follows the drafting approach described in speculative decoding, a method that accelerates auto-regressive LM inference by using a smaller model to concurrently and rapidly generate multiple subsequent tokens (e.g., words or word segments) verified in parallel with a base model, to improve the effectiveness and efficiency of RAG systems. We demonstrate that Speculative RAG yields significant improvements and achieves state-of-the-art performance in both accuracy and latency on the TriviaQA, MuSiQue, PubHealth, and ARC-Challenge benchmarks.
Speculative RAG
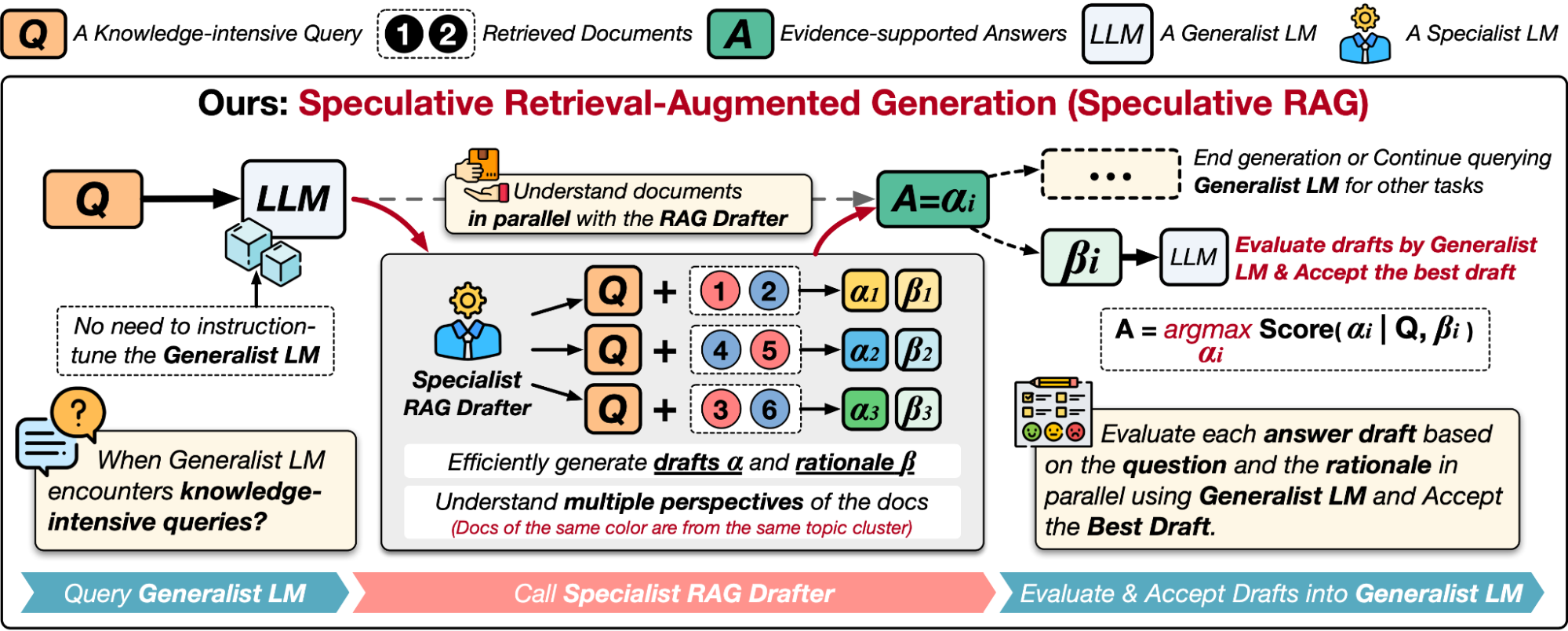
Speculative RAG consists of two components: (1) a specialist RAG drafter, and (2) a generalist RAG verifier. First, the base model’s knowledge retriever retrieves related documents from the knowledge base. Then, Speculative RAG offloads computational burden to the specialist RAG drafter, a small LM specialized in answering questions using retrieved documents and not expected to cope with general problems. This smaller module excels at reasoning over retrieved documents and can rapidly produce responses with their corresponding rationale. It serves as an efficient and robust RAG module for the generalist LM. The specialist drafter enables the generalist verifier to bypass the detailed review of potentially repetitive documents, focusing instead on validating the drafts and selecting the most accurate answer.
For example, when answering, “Which actress or singer starred as Doralee Rhodes in the 1980 film, Nine to Five?”, we retrieve a number of documents from the knowledge base with a retriever. We feed subsets of retrieved documents into the RAG drafter and generate multiple answer drafts with corresponding rationale in parallel. This guarantees a high processing speed of the large number of documents.
We determine that some retrieved documents are not relevant due to the limited capability of the knowledge retriever. In this example, the retrieved documents contain information about both the Nine to Five movie (1980) and the Nine to Five musical (2010). To determine the most accurate draft, the generalist RAG verifier, a general LLM, calculates the conditional generation probability of the answer drafts with rationales and outputs a confidence score. Since answer drafts based on the Nine to Five musical would be inaccurate, the generalist RAG verifier assigns those drafts lower scores and filters them out. Finally, the generalist verifier selects the answer draft with the highest confidence score, which is based on the Nine to Five movie, as the final answer.
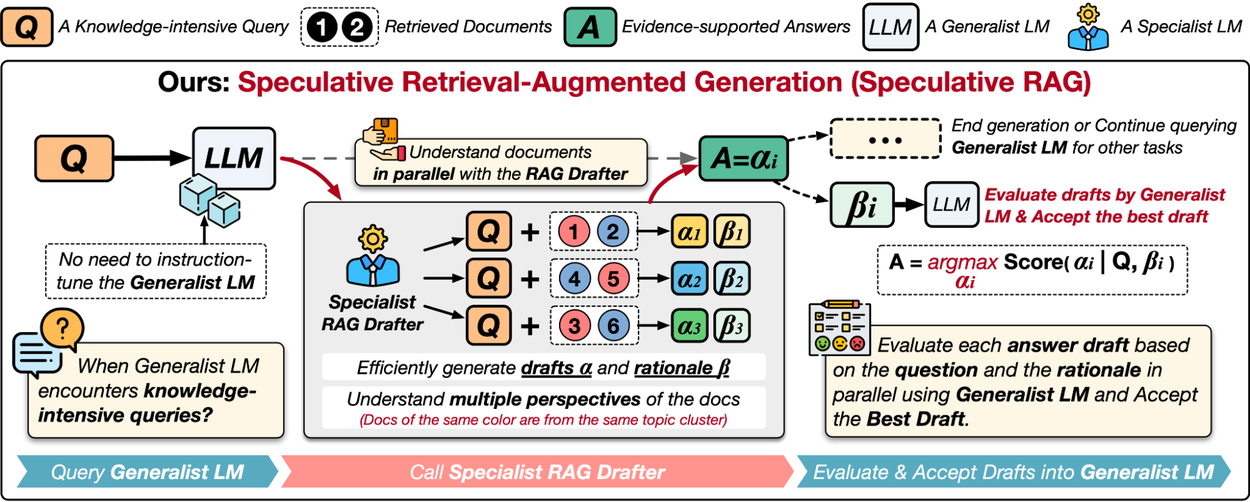
Given a knowledge-intensive query (Q) and retrieved documents, Speculative RAG leverages a generalist LLM to efficiently verify multiple RAG draft answers produced in parallel by a specialized drafter. Each draft is generated from a distinct subset of retrieved documents, providing diverse perspectives while minimizing the number of input tokens per draft.
Results
We evaluate Speculative RAG's effectiveness and efficiency compared to standard RAG systems, Mistral and Mixtral, using retrieved documents from four public RAG benchmarks: TriviaQA, MuSiQue, PubHealth, and ARC-Challenge. In our experiments, we fine-tune the Mistral-7B-v0.1 LM using instruction-following pairs from the Open Instruct dataset and use this as the specialist RAG drafter. We further augmented the training data with documents from Contriever-MS MARCO and generated rationale from Gemini-Ultra. We use a larger LLM, Mixtral-8x7B, as the generalist RAG verifier which doesn’t need further training or tuning.
Better question answering accuracy
We compare Speculative RAG to the standard RAG systems with various backbones (Mistral-7B, Mixtral-8x7B, Mistral-Instruct-7B, and Mixtral-Instruct-8x7B). In comparing standard RAG systems, retrieved documents are directly fed into the LLMs and the LLMs are required to generate the answer by reviewing the long context. Speculative RAG achieves better performance across all benchmarks. For instance, on the PubHealth dataset, Speculative RAG surpasses the best baseline, Mixtral-Instruct-8x7B, by 12.97%.
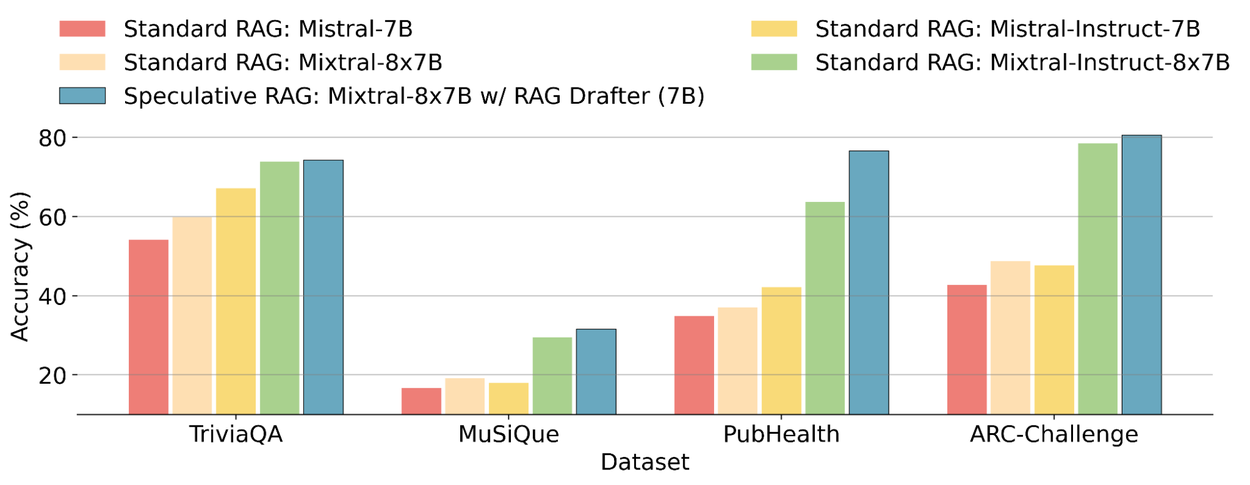
Speculative RAG compared to the standard RAG with various backbone LLMs, including Mistral-7B, Mixtral-8x7B, Mistral-Instruct-7B, and Mixtral-Instruct-8x7B. On all datasets, Speculative RAG achieves the best performance.
Lower latency when handling retrieved documents
Due to the large volume of documents retrieved, latency presents a significant challenge for RAG systems. We analyze the latency of the standard RAG with Mixtral-Instruct-8x7B and Speculative RAG using TriviaQA, MuSiQue, PubHealth, and ARC-Challenge. We randomly sample 100 cases from each dataset and report the average time cost for each case. We use tensor parallelism (i.e., dividing tensors across multiple GPUs) to fit Mixtral-Instruct-8x7B into the GPU memory. We report the latency of Mixtral-Instruct-8x7B under tensor parallelism sizes of 4, 8, and 16. Increasing tensor parallelism does not improve efficiency due to overheads in tensor aggregation and communication. In contrast, Speculative RAG, with its smaller RAG drafter and parallel draft generation, consistently achieves the lowest latency across all datasets. For instance, on the PubHealth dataset, Speculative RAG reduces latency by 51% compared to standard RAG systems.
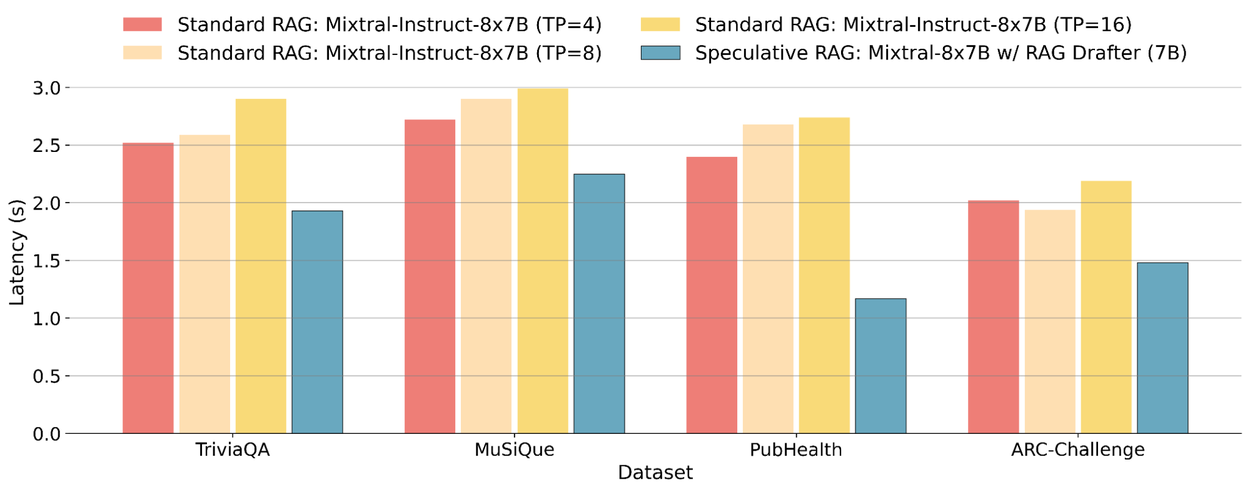
Speculative RAG encodes the retrieved documents in parallel and generates answer drafts with a smaller RAG drafter, significantly improving the efficiency over standard RAG. (TP indicates the tensor parallelism size when running Mixtral-Instruct8x7B for standard RAG).
Conclusion
We present Speculative RAG, a novel approach that decomposes RAG tasks into two separate steps of drafting followed by verification. Speculative RAG delegates the heavy lifting of drafting to a small specialized RAG drafter, while verification is done using a large generalist LM. The parallel generation of multiple drafts from diverse document subsets provides high-quality answer candidates, resulting in substantial improvements in both the quality and speed of the final output generation. We demonstrate the effectiveness of Speculative RAG with accuracy gains up to 12.97% while reducing latency by 51% compared to standard RAG systems. Speculative RAG sheds new light on the potential of collaborative architectures for enhancing RAG performance through task decomposition.
Acknowledgements
This research was conducted by Zilong Wang, Zifeng Wang, Long Le, Huaixiu Steven Zheng, Swaroop Mishra, Vincent Perot, Yuwei Zhang, Anush Mattapalli, Ankur Taly, Jingbo Shang, Chen-Yu Lee, and Tomas Pfister.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence

