SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition
April 22, 2019
Posted by Daniel S. Park, AI Resident and William Chan, Research Scientist
Quick links
Automatic Speech Recognition (ASR), the process of taking an audio input and transcribing it to text, has benefited greatly from the ongoing development of deep neural networks. As a result, ASR has become ubiquitous in many modern devices and products, such as Google Assistant, Google Home and YouTube. Nevertheless, there remain many important challenges in developing deep learning-based ASR systems. One such challenge is that ASR models, which have many parameters, tend to overfit the training data and have a hard time generalizing to unseen data when the training set is not extensive enough.
In the absence of an adequate volume of training data, it is possible to increase the effective size of existing data through the process of data augmentation, which has contributed to significantly improving the performance of deep networks in the domain of image classification. In the case of speech recognition, augmentation traditionally involves deforming the audio waveform used for training in some fashion (e.g., by speeding it up or slowing it down), or adding background noise. This has the effect of making the dataset effectively larger, as multiple augmented versions of a single input is fed into the network over the course of training, and also helps the network become robust by forcing it to learn relevant features. However, existing conventional methods of augmenting audio input introduces additional computational cost and sometimes requires additional data.
In our recent paper, “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition”, we take a new approach to augmenting audio data, treating it as a visual problem rather than an audio one. Instead of augmenting the input audio waveform as is traditionally done, SpecAugment applies an augmentation policy directly to the audio spectrogram (i.e., an image representation of the waveform). This method is simple, computationally cheap to apply, and does not require additional data. It is also surprisingly effective in improving the performance of ASR networks, demonstrating state-of-the-art performance on the ASR tasks LibriSpeech 960h and Switchboard 300h.
SpecAugment
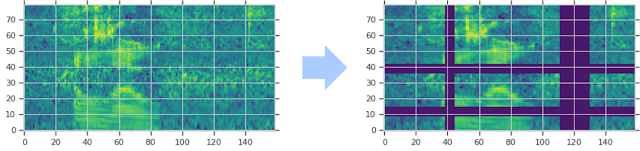
In traditional ASR, the audio waveform is typically encoded as a visual representation, such as a spectrogram, before being input as training data for the network. Augmentation of training data is normally applied to the waveform audio before it is converted into the spectrogram, such that after every iteration, new spectrograms must be generated. In our approach, we investigate the approach of augmenting the spectrogram itself, rather than the waveform data. Since the augmentation is applied directly to the input features of the network, it can be run online during training without significantly impacting training speed.
 |
| A waveform is typically converted into a visual representation (in our case, a log mel spectrogram; steps 1 through 3 of this article) before being fed into a network. |
 |
| The log mel spectrogram is augmented by warping in the time direction, and masking (multiple) blocks of consecutive time steps (vertical masks) and mel frequency channels (horizontal masks). The masked portion of the spectrogram is displayed in purple for emphasis. |
 |
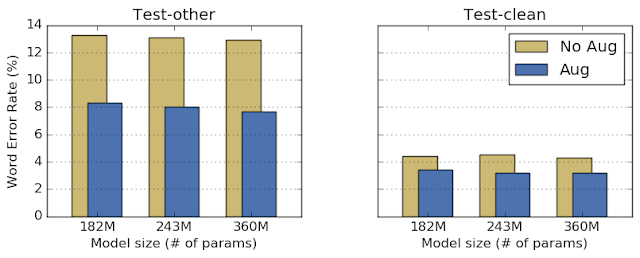
| Performance of networks on the test sets of LibriSpeech with and without augmentation. The LibriSpeech test set is divided into two portions, test-clean and test-other, the latter of which contains noisier audio data. |
 |
| Training, clean (dev-clean) and noisy (dev-other) development set performance with and without augmentation. |
We can now focus on improving training performance, which can be done by adding more capacity to the networks by making them larger. By doing this in conjunction with increasing training time, we were able to get state-of-the-art (SOTA) results on the tasks LibriSpeech 960h and Switchboard 300h.
 |
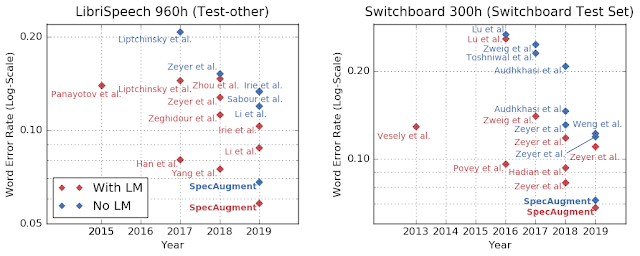
| Word error rates (%) for state-of-the-art results for the tasks LibriSpeech 960h and Switchboard 300h. The test set for both tasks have a clean (clean/Switchboard) and a noisy (other/CallHome) subset. Previous SOTA results taken from Li et. al (2019), Yang et. al (2018) and Zeyer et. al (2018). |
 |
| Performance of various classes of networks on LibriSpeech and Switchboard tasks. The performance of LAS models is compared to classical (e.g., HMM) and other end-to-end models (e.g., CTC/ASG) over time. |
Language models (LMs), which are trained on a bigger corpus of text-only data, have played a significant role in improving the performance of an ASR network by leveraging information learned from text. However, LMs typically need to be trained separately from the ASR network, and can be very large in memory, making it hard to fit on a small device, such as a phone. An unexpected outcome of our research was that models trained with SpecAugment out-performed all prior methods even without the aid of a language model. While our networks still benefit from adding an LM, our results are encouraging in that it suggests the possibility of training networks that can be used for practical purposes without the aid of an LM.
 |
| Word error rates for LibriSpeech and Switchboard tasks with and without LMs. SpecAugment outperforms previous state-of-the-art even before the inclusion of a language model. |
Acknowledgements
We would like to thank the co-authors of our paper Chung-Cheng Chiu, Ekin Dogus Cubuk, Quoc Le, Yu Zhang and Barret Zoph. We also thank Yuan Cao, Ciprian Chelba, Kazuki Irie, Ye Jia, Anjuli Kannan, Patrick Nguyen, Vijay Peddinti, Rohit Prabhavalkar, Yonghui Wu and Shuyuan Zhang for useful discussions.
Quick links
Other posts of interest
-

February 5, 2026
How AI tools can redefine universal design to increase accessibility- Education Innovation ·
- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-

February 3, 2026
Collaborating on a nationwide randomized study of AI in real-world virtual care- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-
January 28, 2026
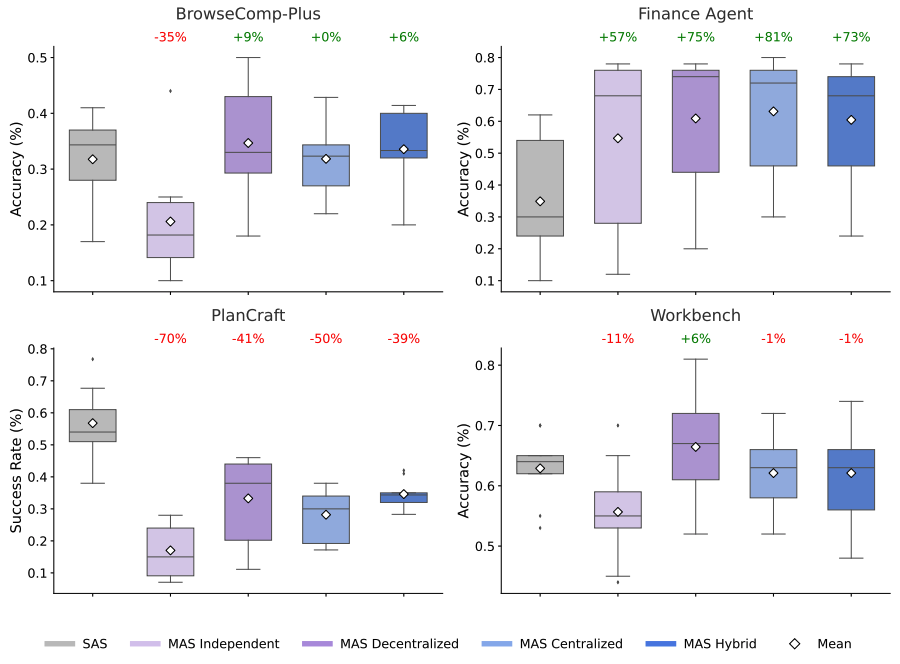
Towards a science of scaling agent systems: When and why agent systems work- Generative AI ·
- Machine Intelligence
×
❮
❯