
Solving virtual machine puzzles: How AI is optimizing cloud computing
October 17, 2025
Pratik Worah, Research Scientist, Google Research, and Martin Maas, Research Scientist, Google DeepMind
We present LAVA, a new scheduling algorithm that continuously re-predicts and adapts to the actual lifetimes of virtual machines to optimize resource efficiency in large cloud data centers.
Quick links
Imagine a puzzle game similar to Tetris with pieces rapidly falling onto a stack. Some fit perfectly. Others don’t. The goal is to pack the blocks as tightly and efficiently as possible. This game is a loose analogy to the challenge faced by cloud data centers several times every second as they try to allocate processing jobs (called virtual machines or VMs) as efficiently as possible. But in this case, the “pieces” (or VMs) appear and disappear, some with a lifespan of only minutes, and others, days. In spite of the initially unknown VM lifespans, we still want to fill as much of the physical servers as possible with these VMs for the sake of efficiency. If only we knew the approximate lifespan of a job, we could clearly allocate much better.
At the scale of large data centers, efficient resource use is especially critical for both economic and environmental reasons. Poor VM allocation can lead to "resource stranding", where a server's remaining resources are too small or unbalanced to host new VMs, effectively wasting capacity. Poor VM allocation also reduces the number of "empty hosts", which are essential for tasks like system updates and provisioning large, resource-intensive VMs.
This classic bin packing problem is made more complex by this incomplete information about VM behavior. AI can help with this problem by using learned models to predict VM lifetimes. However, this often relies on a single prediction at the VM's creation. The challenge with this approach is that a single misprediction can tie up an entire host for an extended period, degrading efficiency.
In “LAVA: Lifetime-Aware VM Allocation with Learned Distributions and Adaptation to Mispredictions”, we introduce a trio of algorithms — non-invasive lifetime aware scoring (NILAS), lifetime-aware VM allocation (LAVA), and lifetime-aware rescheduling (LARS) — which are designed to solve the bin packing problem of efficiently fitting VMs onto physical servers. This system uses a process we call “continuous reprediction”, which means it doesn’t rely on the initial, one-time guess of a VM’s lifespan made at its creation. Instead, the model constantly and automatically updates its prediction for a VM's expected remaining lifetime as the VM continues to run.
The secret life of VMs: Repredictions and probability distributions
One of the key insights driving this research is the recognition that VM lifetimes are often unpredictable and follow a long-tailed distribution. For example, while the vast majority of VMs (88%) live for less than an hour, these short-lived VMs consume only a tiny fraction (2%) of the total resources. This means that the placement of a small number of long-lived VMs has a disproportionately large impact on overall resource efficiency.
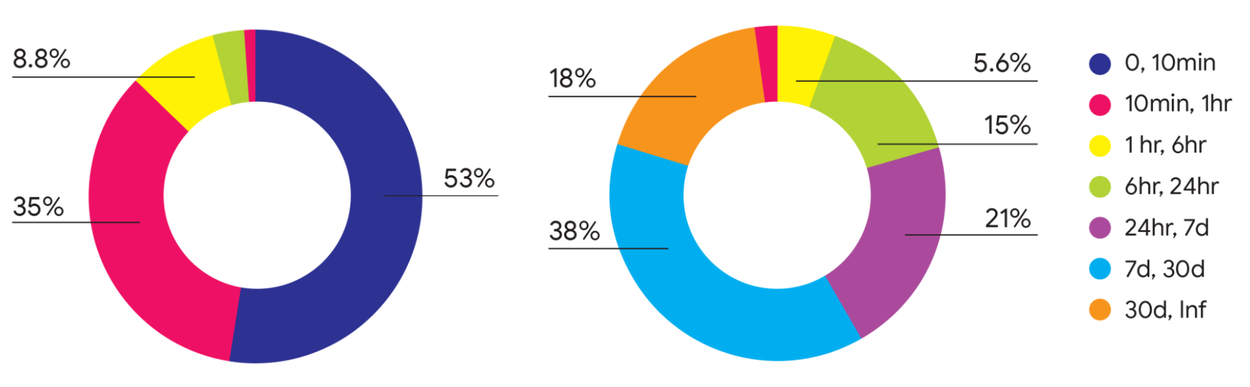
Distribution of VM lifetimes of scheduled VMs (left) vs. their resource consumption (right). Interestingly, the shortest jobs (0–10 min, dark blue), which account for 53% by number, take a negligible fraction of resources. In contrast, the longest running jobs (>30 days, orange), which take considerable resources (18%), amount to a negligible fraction by number.
Instead of trying to predict a single, average lifetime, which can be misleading for VMs with bi-modal or highly varied lifespans, we designed an ML model that predicts a probability distribution for a VM's lifetime. This approach, inspired by survival analysis, allows the model to capture the inherent uncertainty of a VM's behavior.
More importantly, our system uses this distribution to continuously update its predictions. We ask, “Given a VM has been running for five days, what is its expected remaining lifetime?” As a VM continues to run, the system gains more information, and its lifetime prediction becomes more accurate. Our algorithms are specifically co-designed to leverage these repredictions, actively responding to mispredictions and improving the accuracy over time.

Lifetime distribution of VM lifetimes. When the VM is scheduled, the expected (average) lifetime is 0.2 days. After it has run for 1 day, the expected remaining lifetime is 4 days. After 7 days, the expected remaining lifetime is 10 days.
A new class of scheduling algorithms
With this new, more robust prediction model, we developed three novel algorithms to improve VM allocation.
1. Non-Invasive Lifetime Aware Scheduling (NILAS)
NILAS is a non-invasive algorithm that incorporates lifetime predictions into an existing scoring function. It ranks potential hosts for a new VM by considering the repredicted exit times of all existing VMs on that host. By prioritizing hosts where all VMs are expected to exit at a similar time, NILAS aims to create more empty machines. Our use of repredictions is less sensitive to prediction accuracy and allows NILAS to correct for errors. The NILAS algorithm has been deployed on our large-scale cluster manager, Borg, where it significantly improves VM allocation.
2. Lifetime-Aware VM Allocation (LAVA)
LAVA is a more fundamental departure from existing scheduling mechanisms. While NILAS aims to pack VMs with similar lifetimes, LAVA does the opposite: it puts shorter-lived VMs on hosts with one or more long-lived VMs. The goal is to fill in resource gaps with short-lived VMs that are at least an order of magnitude shorter than the host’s anticipated lifespan, so that they exit quickly without extending the host’s overall lifespan. LAVA also actively adapts to mispredictions by increasing a host’s anticipated lifespan if a VM outlives its expected deadline. Simulations show that this strategy minimizes fragmentation and ensures that hosts are eventually freed up.
3. Lifetime-Aware Rescheduling (LARS)
LARS uses our lifetime predictions to minimize VM disruptions during defragmentation and maintenance. When a host needs to be defragmented, LARS sorts the VMs on that host by their predicted remaining lifetime and migrates the longest-lived VMs first. Shorter-lived VMs exit naturally before migration. Simulations with LARS indicate it has the potential to reduce the total number of migrations required by around 4.5%.
Addressing the challenge of deployment at scale
Developing powerful models and algorithms is only one part of the solution. Getting them to work reliably at large scale required us to rethink our approach to model deployment.
A common practice is to serve machine learning models on dedicated inference servers. However, this would have created a circular dependency, as these servers would themselves run on our cluster scheduling system. A failure in the model serving layer could then cause a cascading failure in the scheduler itself, which is unacceptable for a mission-critical system.
Our solution was to compile the model directly into the Borg scheduler binary. This approach eliminated the circular dependency and ensured that the model was tested and rolled out with the same rigorous process as any other code change to the scheduler. This also yielded an additional benefit: the model's median latency is just 9 microseconds (µs), which is 780 times faster than a comparable approach that uses separate model servers. This low latency is crucial for running repredictions frequently and for using the model in performance-sensitive tasks, like maintenance and defragmentation.
We also found that for our largest zones, the number of required predictions could become a bottleneck. We addressed this by introducing a host lifetime score cache, which only updates predictions when a VM is added or removed from a host, or when a host's expected lifetime expires. This caching mechanism ensures high performance and allows us to deploy our system fleet-wide.
Results
Our NILAS algorithm has been running in Google's production data centers since early 2024. The results are clear and significant.
- Increased empty hosts: Our production pilots and fleet-wide rollouts have shown an increase in empty hosts by 2.3–9.2 percentage points (pp). This metric directly correlates with efficiency, as a 1 pp improvement is typically equivalent to saving 1% of a cluster's capacity.
- Reduced resource stranding: In some pilot experiments, NILAS reduced CPU stranding by approximately 3% and memory stranding by 2%. This means more of a host's resources are available to be used by new VMs.
Simulations running LAVA suggest it will provide a further ~0.4 pp improvement over NILAS. Similarly, simulations with LARS indicate that it has the potential to reduce the number of VM live migrations needed for maintenance by 4.5%.
Conclusion
We believe this work is a foundational step towards a future where data center management is increasingly optimized by machine learning systems. The techniques we developed, particularly the use of repredictions and the co-design of models and systems, are generalizable to other tasks. We have demonstrated that it is possible to integrate advanced machine learning techniques into the lowest layers of a system’s infrastructure stack without sacrificing reliability or latency, while still delivering significant efficiency gains.
Acknowledgements
LAVA is a large collaborative project that spanned multiple teams across Google, including Google Cloud, Google DeepMind, Google Research, and SystemsResearch@Google. Key contributors include Jianheng Ling, Pratik Worah, Yawen Wang, Yunchuan Kong, Anshul Kapoor, Chunlei Wang, Clifford Stein, Diwakar Gupta, Jason Behmer, Logan A. Bush, Prakash Ramanan, Rajesh Kumar, Thomas Chestna, Yajing Liu, Ying Liu, Ye Zhao, Kathryn S. McKinley, Meeyoung Park, and Martin Maas.
Quick links
Other posts of interest
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence

