SmartReply for YouTube Creators
July 1, 2020
Posted by Rami Al-Rfou, Research Scientist, Google Research
Quick links
It has been more than 4 years since SmartReply was launched, and since then, it has expanded to more users with the Gmail launch and Android Messages and to more devices with Android Wear. Developers now use SmartReply to respond to reviews within the Play Developer Console and can set up their own versions using APIs offered within MLKit and TFLite. With each launch there has been a unique challenge in modeling and serving that required customizing SmartReply for the task requirements.
We are now excited to share an updated SmartReply built for YouTube and implemented in YouTube Studio that helps creators engage more easily with their viewers. This model learns comment and reply representation through a computationally efficient dilated self-attention network, and represents the first cross-lingual and character byte-based SmartReply model. SmartReply for YouTube is currently available for English and Spanish creators, and this approach simplifies the process of extending the SmartReply feature to many more languages in the future.


The initial release of SmartReply for Inbox encoded input emails word-by-word with a recurrent neural network, and then decoded potential replies with yet another word-level recurrent neural network. Despite the expressivity of this approach, it was computationally expensive. Instead, we found that one can achieve the same ends by designing a system that searches through a predefined list of suggestions for the most appropriate response.
This retrieval system encoded the message and its suggestion independently. First, the text was preprocessed to extract words and short phrases. This preprocessing included, but was not limited to, language identification, tokenization, and normalization. Two neural networks then simultaneously and independently encoded the message and the suggestion. This factorization allowed one to pre-compute the suggestion encodings and then search through the set of suggestions using an efficient maximum inner product search data structure. This deep retrieval approach enabled us to expand SmartReply to Gmail and since then, it has been the foundation for several SmartReply systems including the current YouTube system.
Beyond Words
The previous SmartReply systems described above relied on word level preprocessing that is well tuned for a limited number of languages and narrow genres of writing. Such systems face significant challenges in the YouTube case, where a typical comment might include heterogeneous content, like emoji, ASCII art, language switching, etc. In light of this, and taking inspiration from our recent work on byte and character language modeling, we decided to encode the text without any preprocessing. This approach is supported by research demonstrating that a deep Transformer network is able to model words and phrases from the ground up just by feeding it text as a sequence of characters or bytes, with comparable quality to word-based models.
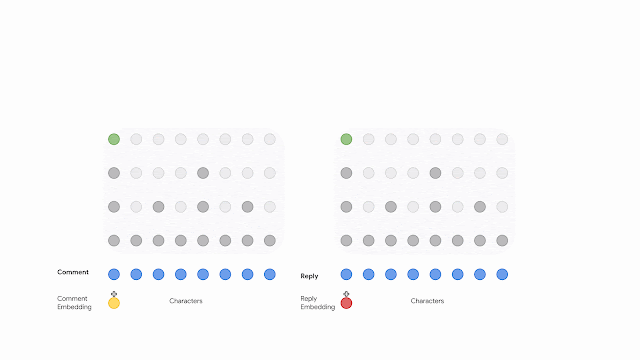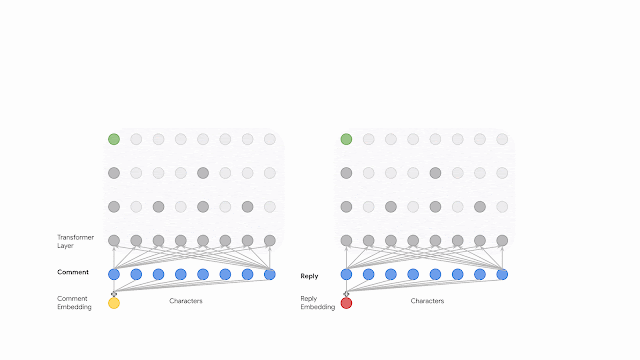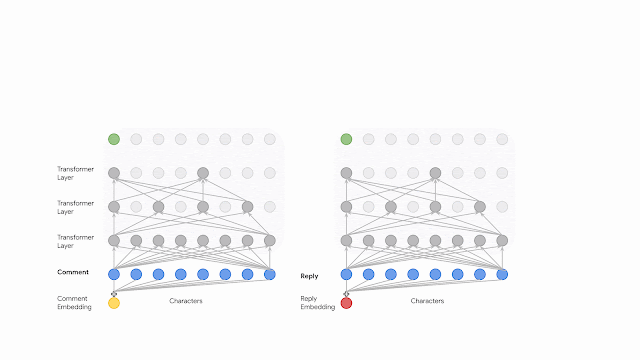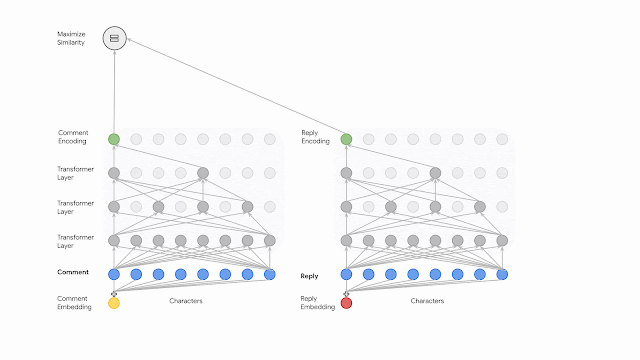
Although initial results were promising, especially for processing comments with emoji or typos, the inference speed was too slow for production due to the fact that character sequences are longer than word equivalents and the computational complexity of self-attention layers grows quadratically as a function of sequence length. We found that shrinking the sequence length by applying temporal reduction layers at each layer of the network, similar to the dilation technique applied in WaveNet, provides a good trade-off between computation and quality.
The figure below presents a dual encoder network that encodes both the comment and the reply to maximize the mutual information between their latent representations by training the network with a contrastive objective. The encoding starts with feeding the transformer a sequence of bytes after they have been embedded. The input for each subsequent layer will be reduced by dropping a percentage of characters at equal offsets. After applying several transformer layers the sequence length is greatly truncated, significantly reducing the computational complexity. This sequence compression scheme could be substituted by other operators such as average pooling, though we did not notice any gains from more sophisticated methods, and therefore, opted to use dilation for simplicity.
 |
| A dual encoder network that maximizes the mutual information between the comments and their replies through a contrastive objective. Each encoder is fed a sequence of bytes and is implemented as a computationally efficient dilated transformer network. |
Instead of training a separate model for each language, we opted to train a single cross-lingual model for all supported languages. This allows the support of mixed-language usage in the comments, and enables the model to utilize the learning of common elements in one language for understanding another, such as emoji and numbers. Moreover, having a single model simplifies the logistics of maintenance and updates. While the model has been rolled out to English and Spanish, the flexibility inherent in this approach will enable it to be expanded to other languages in the future.
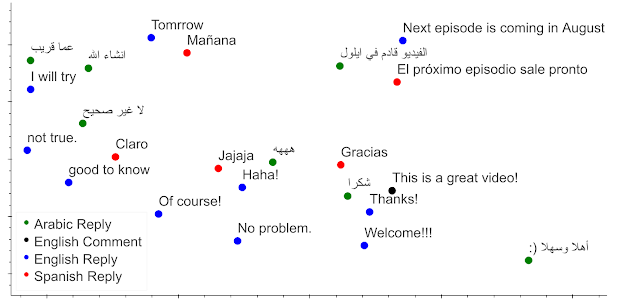
Inspecting the encodings of a multilingual set of suggestions produced by the model reveals that the model clusters appropriate replies, regardless of the language to which they belong. This cross-lingual capability emerged without exposing the model during training to any parallel corpus. We demonstrate in the figure below for three languages how the replies are clustered by their meaning when the model is probed with an input comment. For example, the English comment “This is a great video,” is surrounded by appropriate replies, such as “Thanks!” Moreover, inspection of the nearest replies in other languages reveal them also to be appropriate and similar in meaning to the English reply. The 2D projection also shows several other cross-lingual clusters that consist of replies of similar meaning. This clustering demonstrates how the model can support a rich cross-lingual user experience in the supported languages.
 |
| A 2D projection of the model encodings when presented with a hypothetical comment and a small list of potential replies. The neighborhood surrounding English comments (black color) consists of appropriate replies in English and their counterparts in Spanish and Arabic. Note that the network learned to align English replies with their translations without access to any parallel corpus. |
Our goal is to help creators, so we have to make sure that SmartReply only makes suggestions when it is very likely to be useful. Ideally, suggestions would only be displayed when it is likely that the creator would reply to the comment and when the model has a high chance of providing a sensible and specific response. To accomplish this, we trained auxiliary models to identify which comments should trigger the SmartReply feature.
Conclusion
We’ve launched YouTube SmartReply, starting with English and Spanish comments, the first cross-lingual and character byte-based SmartReply. YouTube is a global product with a diverse user base that generates heterogeneous content. Consequently, it is important that we continuously improve comments for this global audience, and SmartReply represents a strong step in this direction.
Acknowledgements
SmartReply for YouTube creators was developed by Golnaz Farhadi, Ezequiel Baril, Cheng Lee, Claire Yuan, Coty Morrison, Joe Simunic, Rachel Bransom, Rajvi Mehta, Jorge Gonzalez, Mark Williams, Uma Roy and many more. We are grateful for the leadership support from Nikhil Dandekar, Eileen Long, Siobhan Quinn, Yun-hsuan Sung, Rachel Bernstein, and Ray Kurzweil.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
×
❮
❯