Small models, big results: Achieving superior intent extraction through decomposition
January 22, 2026
Danielle Cohen and Yoni Halpern, Software Engineers, Google
We present a novel approach to tackle the task of understanding user intents from UI interaction trajectories using small models, which shows better results than significantly larger models.
Quick links
As AI technologies advance, truly helpful agents will become capable of better anticipating user needs. For experiences on mobile devices to be truly helpful, the underlying models need to understand what the user is doing (or trying to do) when users interact with them. Once current and previous tasks are understood, the model has more context to predict potential next actions. For example, if a user previously searched for music festivals across Europe and is now looking for a flight to London, the agent could offer to find festivals in London on those specific dates.
Large multimodal LLMs are already quite good at understanding user intent from a user interface (UI) trajectory. But using LLMs for this task would typically require sending information to a server, which can be slow, costly, and carries the potential risk of exposing sensitive information.
Our recent paper “Small Models, Big Results: Achieving Superior Intent Extraction Through Decomposition”, presented at EMNLP 2025, addresses the question of how to use small multimodal LLMs (MLLMs) to understand sequences of user interactions on the web and on mobile devices all on device. By separating user intent understanding into two stages, first summarizing each screen separately and then extracting an intent from the sequence of generated summaries, we make the task more tractable for small models. We also formalize metrics for evaluation of model performance and show that our approach yields results comparable to much larger models, illustrating its potential for on-device applications. This work builds on previous work from our team on user intent understanding.
Details
We introduce a decomposed workflow for user intent understanding from user interactions. At inference time the model performs two main steps. In the first step each individual interaction on a single screen and UI element is summarized independently. Next, those summaries are used as a series of events to predict the general intent of the entire UI trajectory.
Individual screen summaries
At the first stage, every individual interaction is summarized by a small multimodal LLM.
Given the a sliding window of three screens (previous, current, next), the following questions are asked:
- What is the relevant screen context? Give a short list of salient details on the current screen.
- What did the user just do? Provide a list of actions that the user took in this interaction.
- Speculate. What is the user trying to accomplish with this interaction?
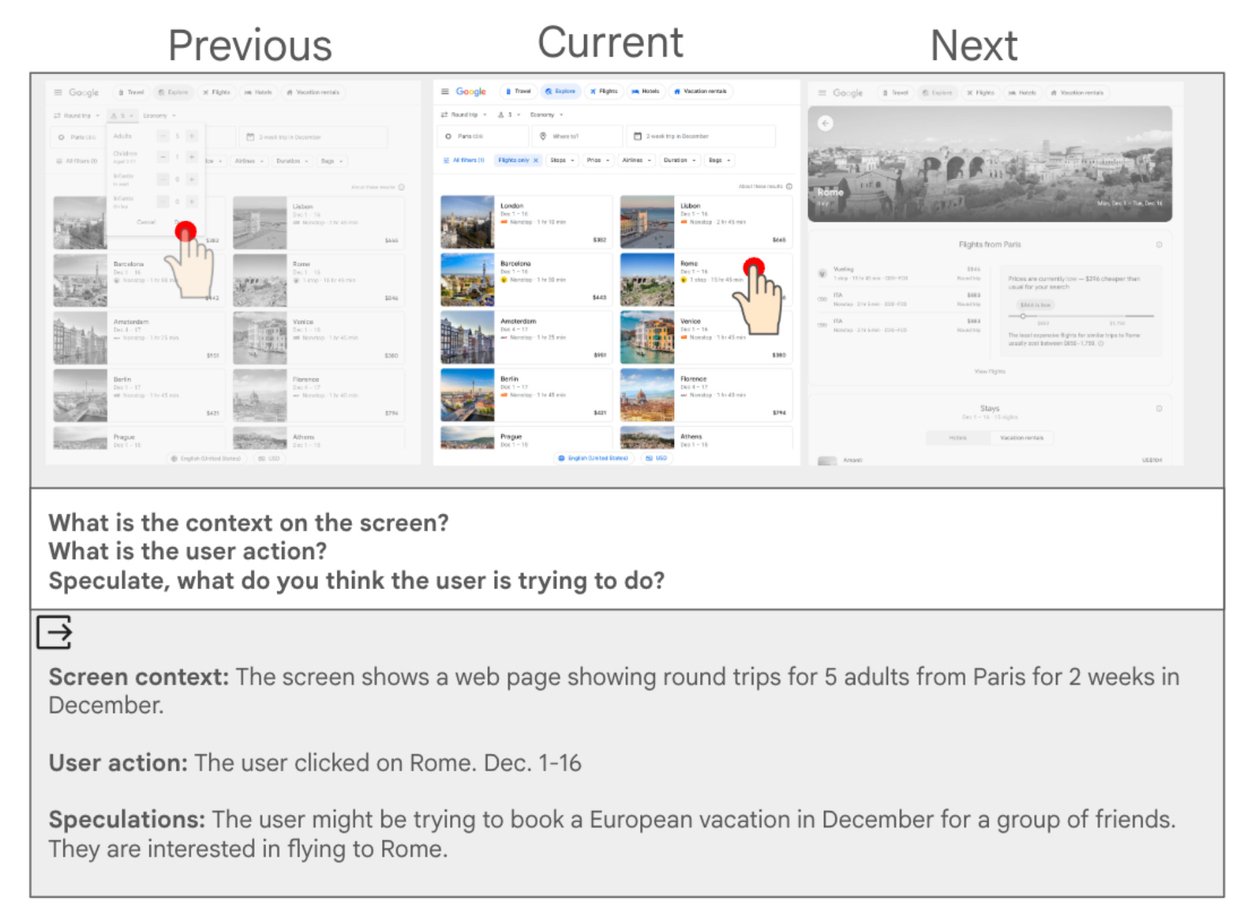
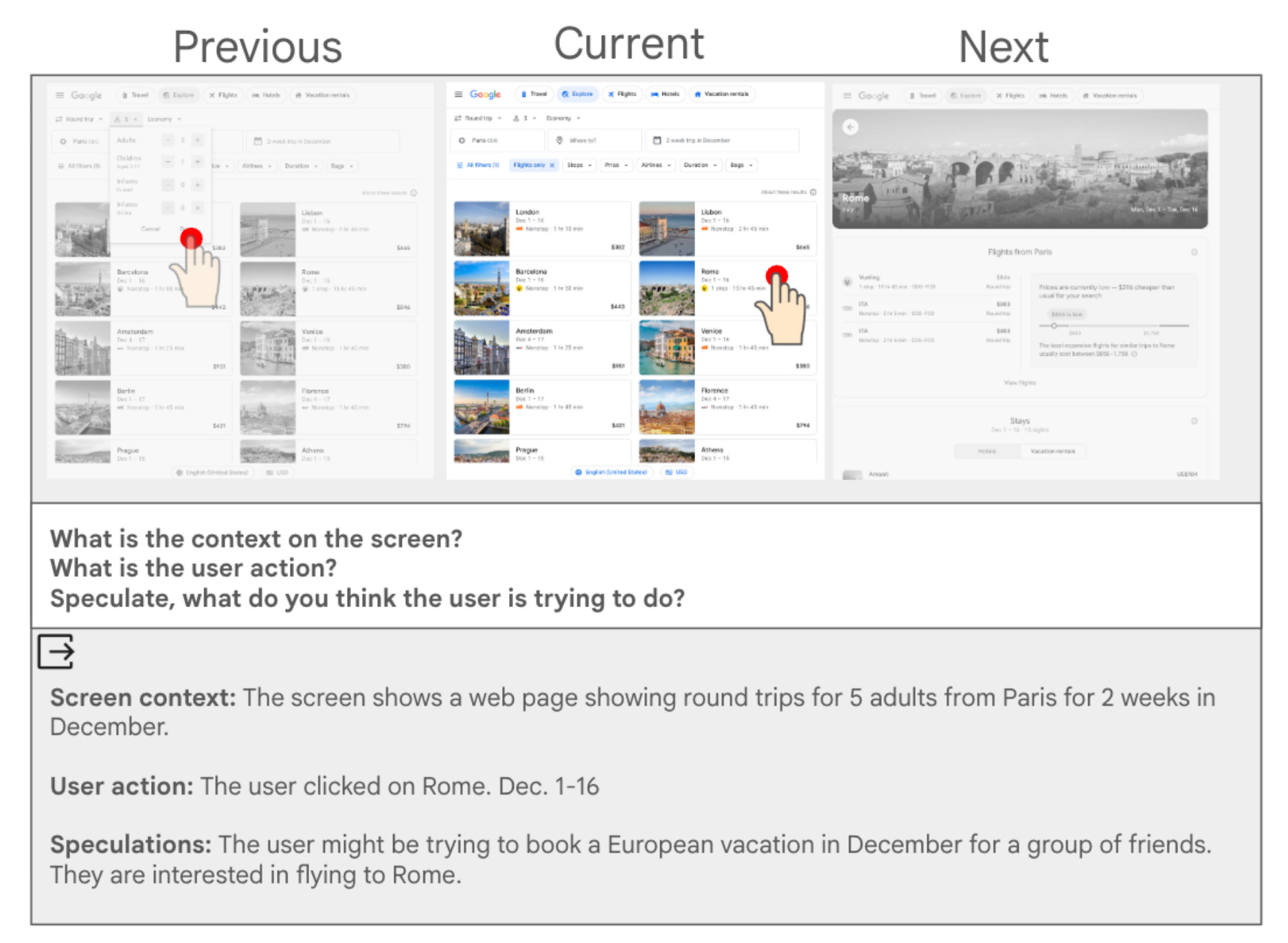
First stage of the decomposed workflow. For each screenshot, action pair, we look at the surrounding screens, and ask questions about the screen context, the user action, and speculation about what the user is trying to do. At the bottom, we show a potential LLM-generated summary answering the three questions. This summary will serve as an input to the second stage of the decomposed workflow.
Intent extraction from summaries
In this stage, a fine-tuned small model is used to extract a single sentence from the screen summaries.
We find that the following techniques are helpful.
- Fine-tuning: Giving examples of what a “good” intent statement looks like helps the model focus on the important parts of the summaries and drop the non-useful ones. We use publicly available automation datasets for training data, since they have good examples that pair intent with sequences of actions.
- Label Preparation: Because the summaries may be missing information, if we train with the full intents, we inadvertently teach the model to fill in details that aren’t present (i.e., to hallucinate). To avoid this, we first remove any information that doesn’t appear in the summaries from the training intents (using a separate LLM call).
- Dropping speculations: Giving the model a specified place to output its speculations on what the user is trying to do helps create a more complete step summary in stage one, but can confuse the intent extractor in stage two. So we do not use the speculations during the second stage. While this may seem counterintuitive — asking for speculations in the first stage only to drop them in the second — we find this helps improve performance.
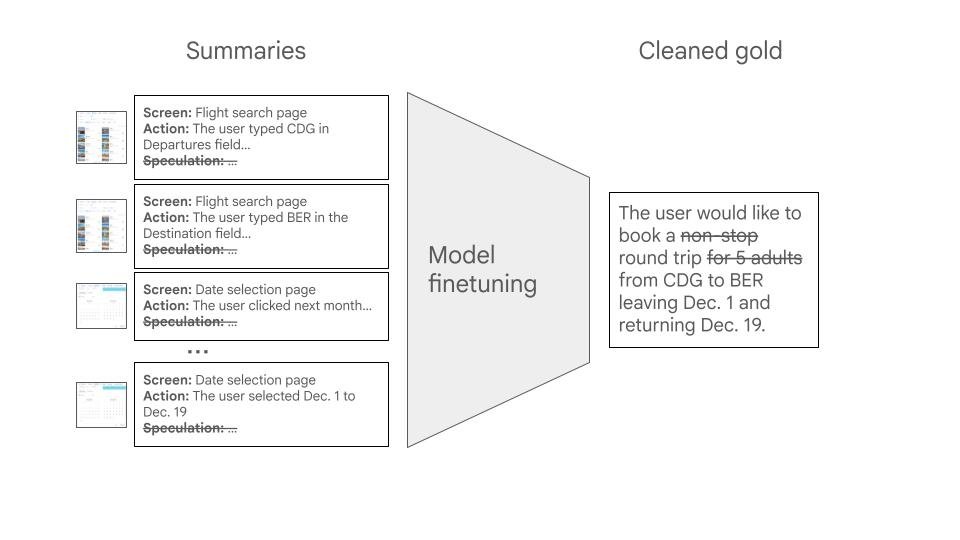
The second stage of the decomposed workflow uses a fine-tuned model that takes the summaries generated in the first stage as inputs and outputs a concise intent statement. During this stage we drop all speculation from the summaries and clean the labels during training so that they don’t encourage hallucinations.
Evaluation approach
We use the Bi-Fact approach to evaluate the quality of a predicted intent against a reference intent. With this approach, we use a separate LLM call to split the reference and predicted intents into details of the intent that cannot be broken down further, which we call “atomic facts”. For example, “a one-way flight” would be an atomic fact, while “a flight from London to Kigali” would be two. We then count the number of reference facts that are entailed by the predicted intent and the number of predicted facts that are entailed by the reference intent. This enables us to know the precision (how many of the predicted facts are correct) and recall (how many of the true facts we correctly predicted) of our method and to calculate the F1 score.

Fact Coverage Analysis. Evaluating if reference facts were successfully captured in the predicted intent (left), and if predicted facts are supported by the reference intent (right).
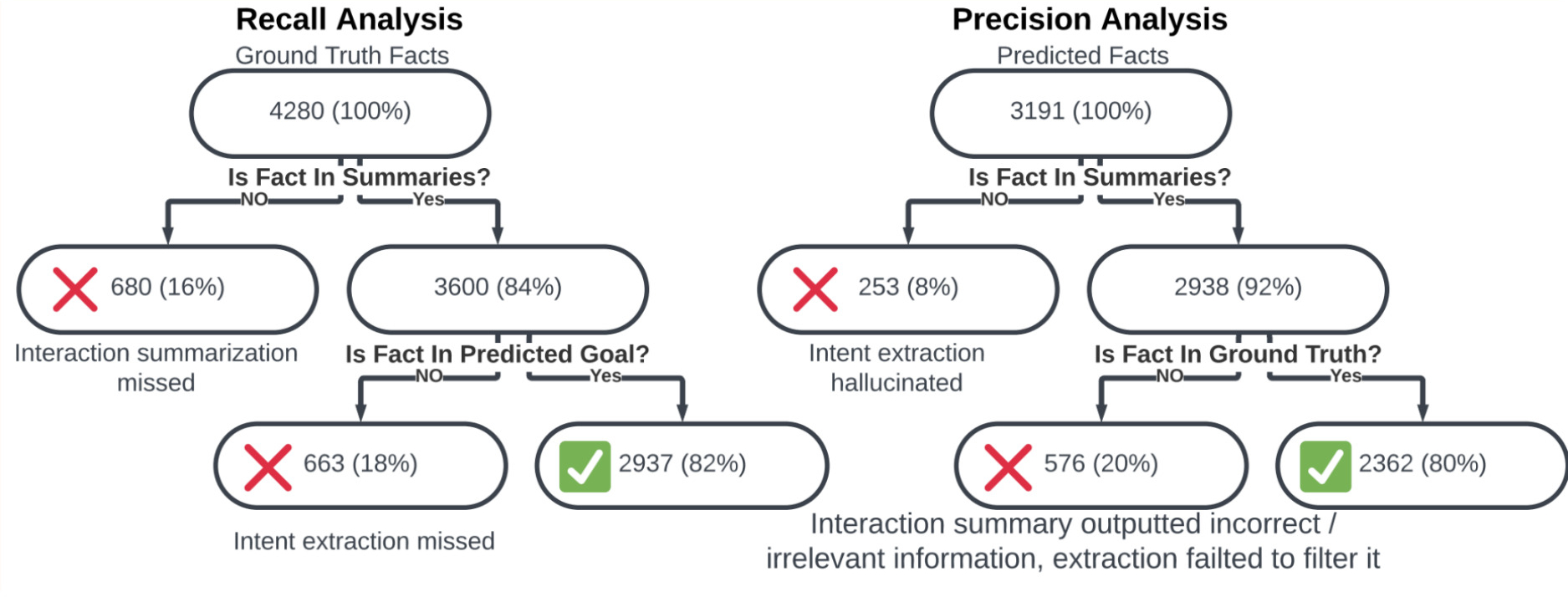
Working with atomic facts also helps to track how the different stages of the decomposed approach contribute to errors. Below we show how we analyze the flow of facts through the system to track missed details and hallucinations at each stage.
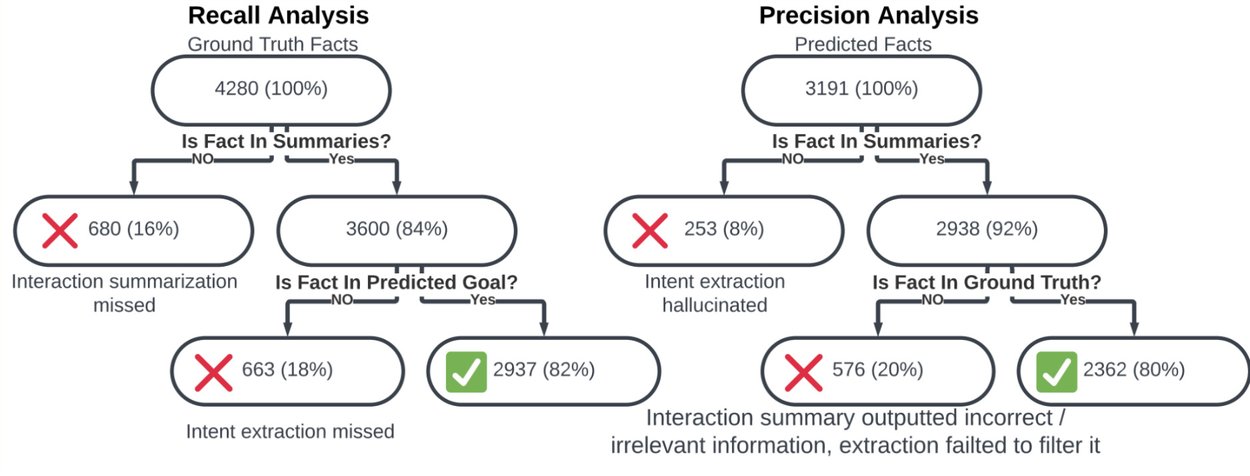
Propagation error analysis of recall and precision across both stages of our model.
Key results
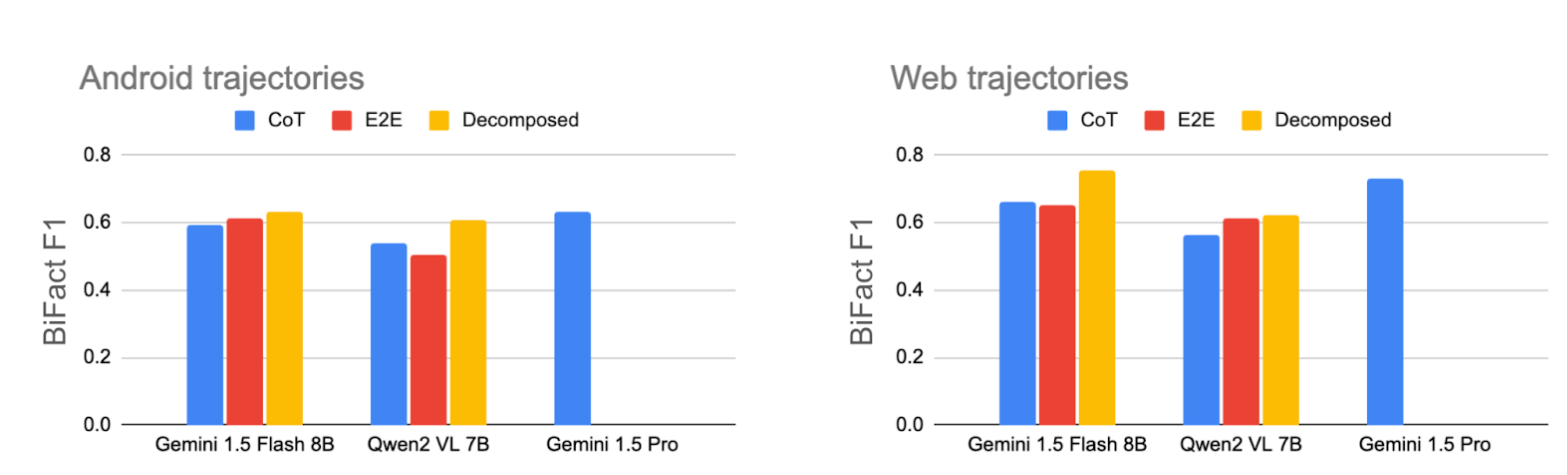
The decomposed approach of summarizing each screen separately and then extracting an intent from the sequence of generated summaries is helpful when using small models. We compare it against standard approaches, including chain of thought prompting (CoT) and end-to-end fine-tuning (E2E), and find that it outperforms both. This result holds true when we tested on both mobile device and web trajectories and for Gemini and Qwen2 base models. We even find that applying the decomposed approach with the Gemini 1.5 Flash 8B model achieves comparable results to using Gemini 1.5 Pro at a fraction of the cost and speed. See the paper for additional experiments.
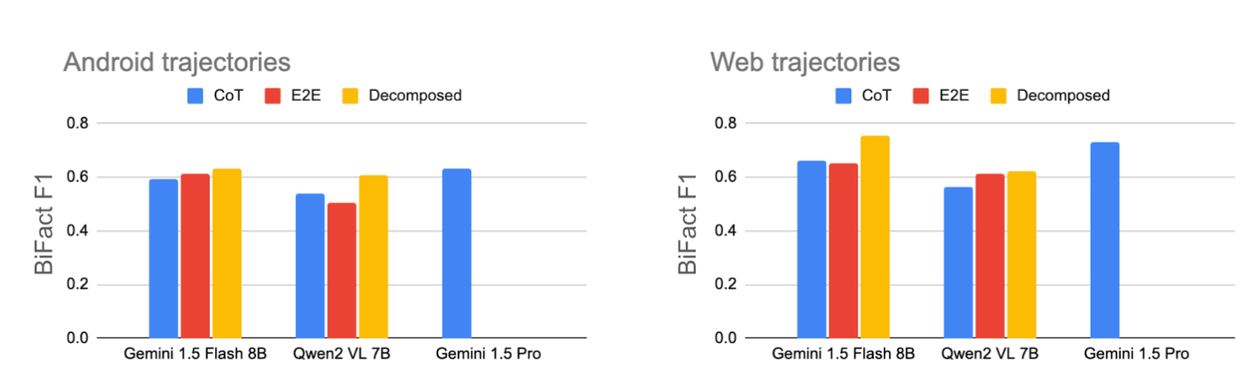
Bi-Fact F1 scores comparing the decomposed method against two natural baselines: chain-of-thought prompting (CoT) and end-to-end fine-tuning (E2E). In all settings, our decomposed method outperforms baselines, and on the mobile device dataset, it is comparable to the performance of the large Gemini Pro model.
Conclusions & future directions
We have shown that a decomposed approach to trajectory summarization can be helpful for intent understanding with small models. Ultimately, as models improve in performance and mobile devices acquire more processing power, we hope that on-device intent understanding can become a building block for many assistive features on mobile devices going forward.
Acknowledgements
Thank you to our paper coauthors: Noam Kahlon, Joel Oren, Omri Berkovitch, Sapir Caduri, Ido Dagan, and Anatoly Efros.
Quick links
Other posts of interest
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets