Simplified Transfer Learning for Chest Radiography Model Development
July 19, 2022
Posted by Akib Uddin, Product Manager and Andrew Sellergren, Software Engineer, Google Health
Quick links
Every year, nearly a billion chest X-ray (CXR) images are taken globally to aid in the detection and management of health conditions ranging from collapsed lungs to infectious diseases. Generally, CXRs are cheaper and more accessible than other forms of medical imaging. However, existing challenges continue to impede the optimal use of CXRs. For example, in some areas, trained radiologists that can accurately interpret CXR images are in short supply. In addition, interpretation variability between experts, workflow differences between institutions, and the presence of rare conditions familiar only to subspecialists all contribute to making high-quality CXR interpretation a challenge.
Recent research has leveraged machine learning (ML) to explore potential solutions for some of these challenges. There is significant interest and effort devoted to building deep learning models that detect abnormalities in CXRs and improve access, accuracy, and efficiency to identify diseases and conditions that affect the heart and lungs. However, building robust CXR models requires large labeled training datasets, which can be prohibitively expensive and time-consuming to create. In some cases, such as working with underrepresented populations or studying rare medical conditions, only limited data are available. Additionally, CXR images vary in quality across populations, geographies, and institutions, making it difficult to build robust models that perform well globally.
In “Simplified Transfer Learning for Chest Radiography Models Using Less Data”, published in the journal Radiology, we describe how Google Health utilizes advanced ML methods to generate pre-trained “CXR networks” that can convert CXR images to embeddings (i.e., information-rich numerical vectors) to enable the development of CXR models using less data and fewer computational resources. We demonstrate that even with less data and compute, this approach has enabled performance comparable to state-of-the-art deep learning models across various prediction tasks. We are also excited to announce the release of CXR Foundation, a tool that utilizes our CXR-specific network to enable developers to create custom embeddings for their CXR images. We believe this work will help accelerate the development of CXR models, aiding in disease detection and contributing to more equitable health access throughout the world.
Developing a Chest X-ray Network
A common approach to building medical ML models is to pre-train a model on a generic task using non-medical datasets and then refine the model on a target medical task. This process of transfer learning may improve the target task performance or at least speed up convergence by applying the understanding of natural images to medical images. However, transfer learning may still require large labeled medical datasets for the refinement step.
Expanding on this standard approach, our system supports modeling CXR-specific tasks through a three-step model training setup composed of (1) generic image pre-training similar to traditional transfer learning, (2) CXR-specific pre-training, and (3) task-specific training. The first and third steps are common in ML: first pre-training on a large dataset and labels that are not specific to the desired task, and then fine-tuning on the task of interest.
We built a CXR-specific image classifier that employs supervised contrastive learning (SupCon). SupCon pulls together representations of images that have the same label (e.g., abnormal) and pushes apart representations of images that have a different label (e.g., one normal image and one abnormal image). We pre-trained this model on de-identified CXR datasets of over 800,000 images generated in partnership with Northwestern Medicine and Apollo Hospitals in the US and India, respectively. We then leveraged noisy abnormality labels from natural language processing of radiology reports to build our “CXR-specific” network.
This network creates embeddings (i.e., information-rich numerical vectors that can be used to distinguish classes from each other) that can more easily train models for specific medical prediction tasks, such as image finding (e.g., airspace opacity), clinical condition (e.g., tuberculosis), or patient outcome (e.g., hospitalization). For example, the CXR network can generate embeddings for every image in a given CXR dataset. For these images, the generated embeddings and the labels for the desired target task (such as tuberculosis) are used as examples to train a small ML model.
 |
| Left: Training a CXR model for a given task generally requires a large number of labeled images and a significant amount of computational resources to create a foundation of neural network layers. Right: With the CXR network and tool providing this foundation, each new task requires only a fraction of the labeled images, computational resources, and neural network parameters compared to rebuilding the entire network from scratch. |
Effects of CXR Pre-training
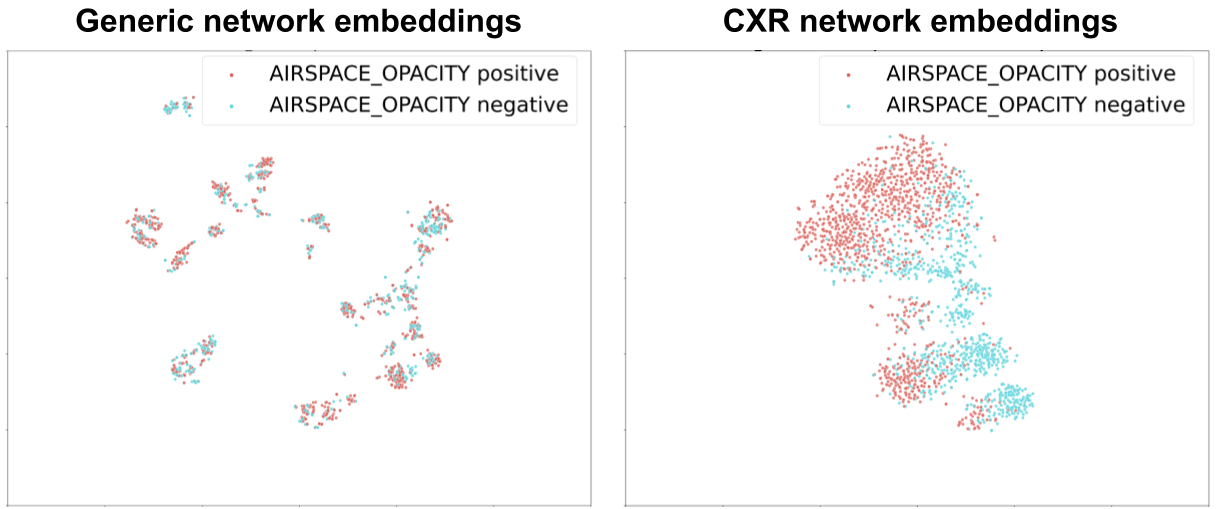
We visualized these embedding layers at each step of the process using airspace opacity as an example (see the figure below). Before SupCon-based pre-training, there was poor separation of normal and abnormal CXR embeddings. After SupCon-based pre-training, the positive examples were grouped more closely together, and the negative examples more closely together as well, indicating that the model had identified that images from each category resembled themselves.
 |
| Visualizations of the t-distributed stochastic neighbor embedding for generic vs. CXR-specific network embeddings. Embeddings are information-rich numerical vectors that alone can distinguish classes from each other, in this case, airspace opacity positive vs. negative. |
Our research suggests that adding the second stage of pre-training enables high-quality models to be trained with up to 600-fold less data in comparison to traditional transfer learning approaches that leverage pre-trained models on generic, non-medical datasets. We found this to be true regardless of model architecture (e.g., ResNet or EfficientNet) or dataset used for natural image pre-training (e.g., ImageNet or JFT-300M). With this approach, researchers and developers can significantly reduce dataset size requirements.
 |
| Top: In a deep learning model, the neural network contains multiple layers of artificial neurons, with the first layer taking the CXR image as input, intermediate layers doing additional computation, and the final layer making the classification (e.g., airspace opacity: present vs. absent). The embedding layer is usually one of the last layers. Bottom left: The traditional transfer learning approach involves a two-step training setup where a generic pre-trained network is optimized directly on a prediction task of interest. Our proposed three-step training setup generates a CXR network using a SupCon ML technique (step 2) before optimization for prediction tasks of interest (step 3). Bottom right: Using the embeddings involves either training smaller models (the first two strategies) or fine-tuning the whole network if there are sufficient data (strategy 3). |
Results
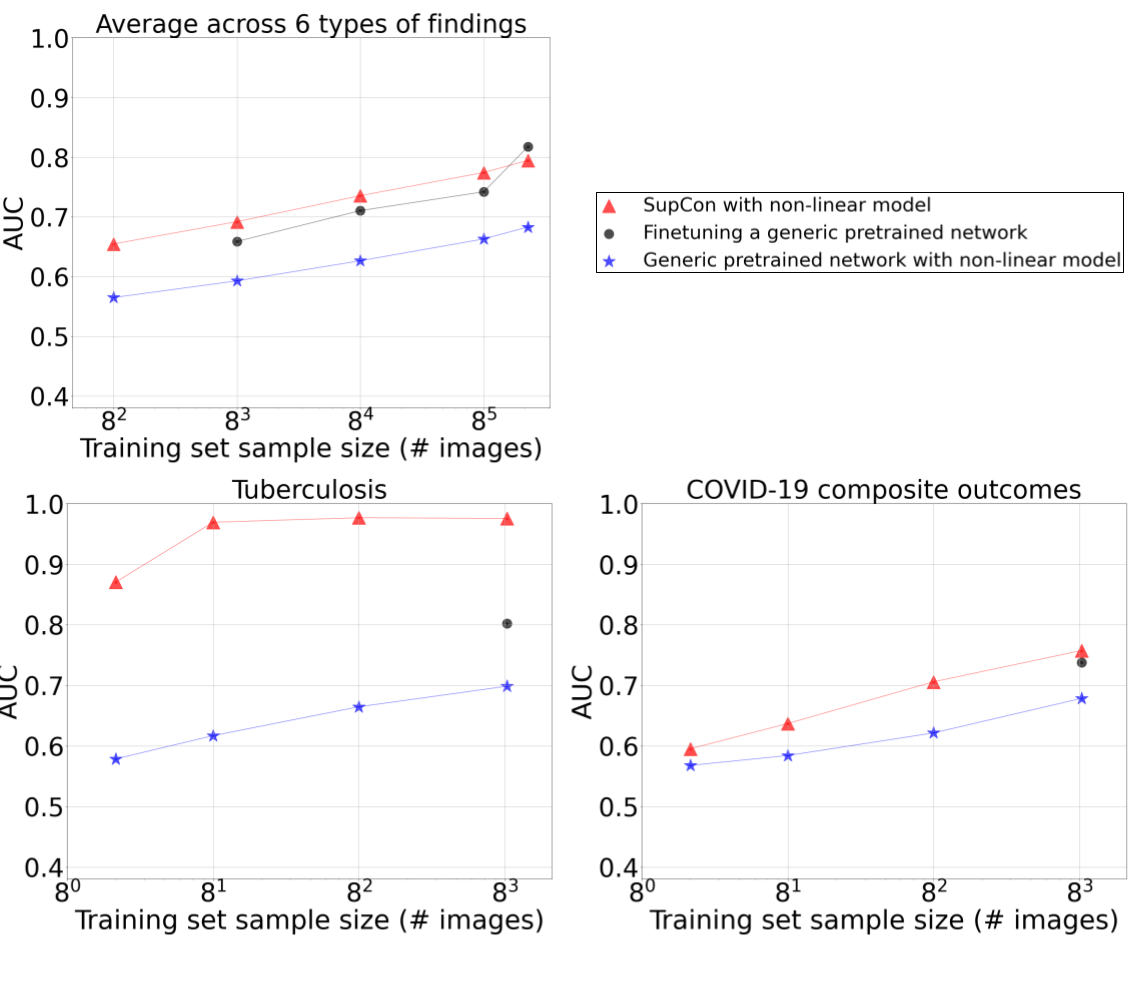
After training the initial model, we measured performance using the area under the curve (AUC) metric with both linear and non-linear models applied to CXR embeddings; and a non-linear model produced by fine-tuning the entire network. On public datasets, such as ChestX-ray14 and CheXpert, our work substantially and consistently improved the data-accuracy tradeoff for models developed across a range of training dataset sizes and several findings. For example, when evaluating the tool’s ability to develop tuberculosis models, data efficiency gains were more striking: models trained on the embeddings of just 45 images achieved non-inferiority to radiologists in detecting tuberculosis on an external validation dataset. For both tuberculosis and severe COVID-19 outcomes, we show that non-linear classifiers trained on frozen embeddings outperformed a model that was fine-tuned on the entire dataset.
 |
| Comparing CXR-specific networks for transfer learning (red), with a baseline transfer learning approach (blue) across a variety of CXR abnormalities (top left), tuberculosis (bottom left), and COVID-19 outcomes (bottom right). This approach improves performance at the same dataset size, or reduces the dataset size required to reach the same performance. Interestingly, using the CXR network with simpler ML models that are faster to train (red) performs better than training the full network (black) at dataset sizes up to 85 images. |
Conclusion and Future Work
To accelerate CXR modeling efforts with low data and computational requirements, we are releasing our CXR Foundation tool, along with scripts to train linear and nonlinear classifiers. Via these embeddings, this tool will allow researchers to jump-start CXR modeling efforts using simpler transfer learning methods. This approach can be particularly useful for predictive modeling using small datasets, and for adapting CXR models when there are distribution shifts in patient populations (whether over time or across different institutions). We are excited to continue working with partners, such as Northwestern Medicine and Apollo Hospitals, to explore the impact of this technology further. By enabling researchers with limited data and compute to develop CXR models, we're hoping more developers can solve the most impactful problems for their populations.
Acknowledgements
Key contributors to this project at Google include Christina Chen, Yun Liu, Dilip Krishnan, Zaid Nabulsi, Atilla Kiraly, Arnav Agharwal, Eric Wu, Yuanzhen Li, Aaron Maschinot, Aaron Sarna, Jenny Huang, Marilyn Zhang, Charles Lau, Neeral Beladia, Daniel Tse, Krish Eswaran, and Shravya Shetty. Significant contributions and input were also made by collaborators Sreenivasa Raju Kalidindi, Mozziyar Etemadi, Florencia Garcia-Vicente, and David Melnick. For the ChestX-ray14 dataset, we thank the NIH Clinical Center for making it publicly available. The authors would also like to acknowledge many members of the Google Health Radiology and labeling software teams. Sincere appreciation also goes to the radiologists who enabled this work with their image interpretation and annotation efforts throughout the study; Jonny Wong for coordinating the imaging annotation work; Craig Mermel and Akinori Mitani for providing feedback on the manuscript; Nicole Linton and Lauren Winer for feedback on the blogpost; and Tom Small for the animation.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence