Sequential Attention: Making AI models leaner and faster without sacrificing accuracy
February 4, 2026
Thomas Fu, Principal Engineer, and Kyriakos Axiotis, Senior Scientist, Google Research
We introduce a subset selection algorithm for making large scale ML models more efficient.
Quick links
Feature selection is the process of identifying and retaining the most informative subset of input variables while discarding irrelevant or redundant noise. A fundamental challenge in both machine learning and deep learning, feature selection is NP-hard (i.e., a problem that is mathematically "impossible" to solve perfectly and quickly for large groups of data), and as such, it remains a highly challenging area of research.
In modern deep neural networks, feature selection is further complicated by intricate non-linear feature interactions. A feature may appear statistically insignificant on its own but become critical when combined with others within the network's non-linear layers. Conversely, a feature’s contribution may appear significant in isolation, but made redundant when taking other features into account. The core challenge lies in identifying essential features for retention while effectively pruning redundancy within complex model architectures.
More broadly, many ML optimization tasks can be cast as subset selection problems, of which feature selection is a special case. For example, embedding dimension tuning can be viewed as selecting a subset of embedding chunks, and weight pruning as selecting a subset of entries from the weight matrix. Therefore devising a general solution for the subset selection problem that is applicable to modern deep learning tasks can be highly impactful for building the most efficient models.
Today, we explore our solution to the subset selection problem, called Sequential Attention. Sequential Attention uses a greedy selection mechanism to sequentially and adaptively select the best next component (like a layer, block, or feature) to add to the model. While adaptive greedy algorithms are known to provide strong guarantees for various subset selection problems, such as submodular optimization, naïvely applying such algorithms would increase the training cost by many orders of magnitude. To tackle this scalability issue, we integrate selection directly into the model training process by performing selection within a single model training. This ensures that Sequential Attention can be applied to large scale ML models with minimal overhead without sacrificing accuracy or complexity. Here we will analyze how Sequential Attention works and show how it’s being used in real-world scenarios to optimize the structure of deep learning models.
How Sequential Attention works
Sequential Attention leverages the weighting power of the attention mechanism to build a subset step-by-step. In contrast to standard "one-shot" attention, in which all candidates are weighted simultaneously, Sequential Attention addresses the NP-hard nature of subset selection by treating it as a sequential decision process. This is particularly effective for identifying high-order non-linear interactions often missed by "filter methods”, which provide the simplest way to pick a subset by focusing only on the merits of each individual item.
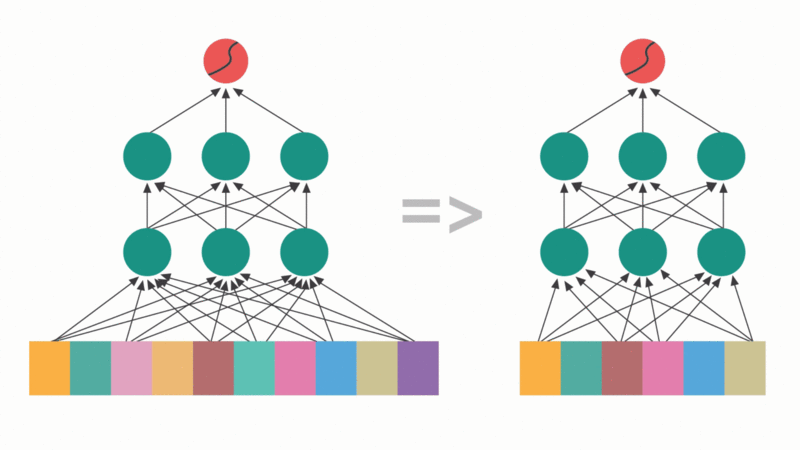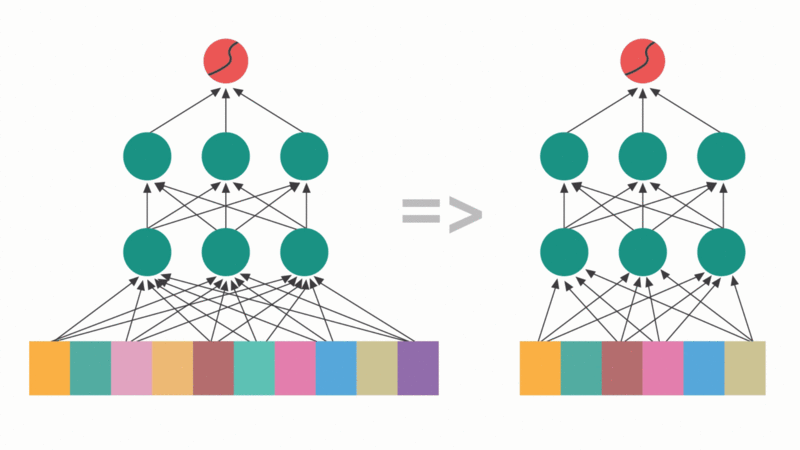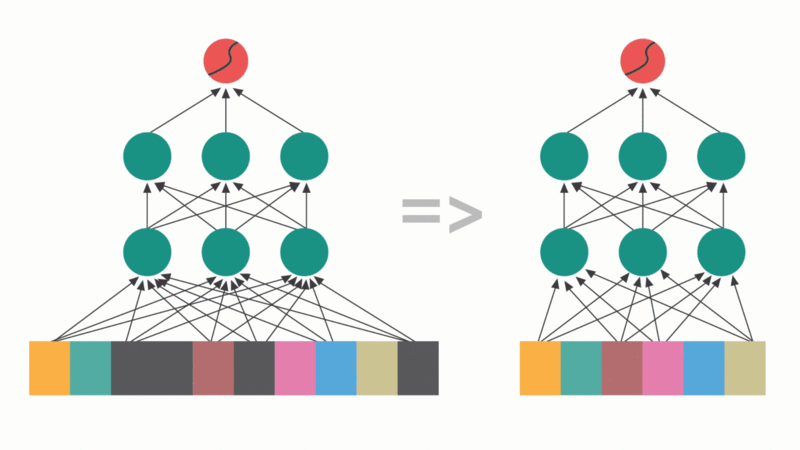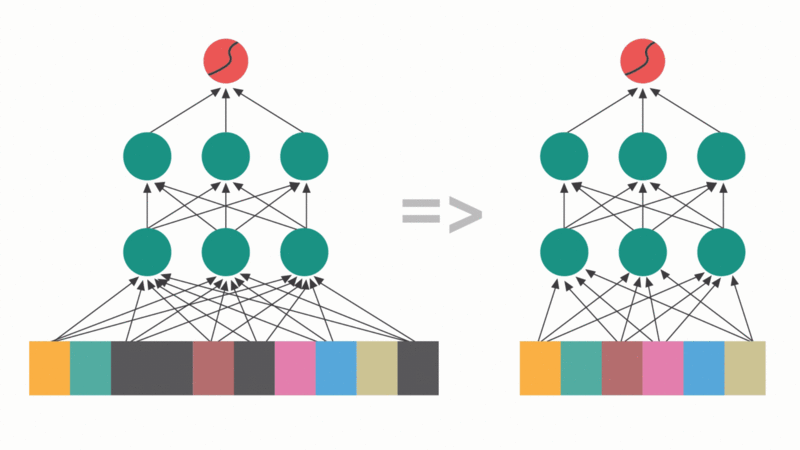
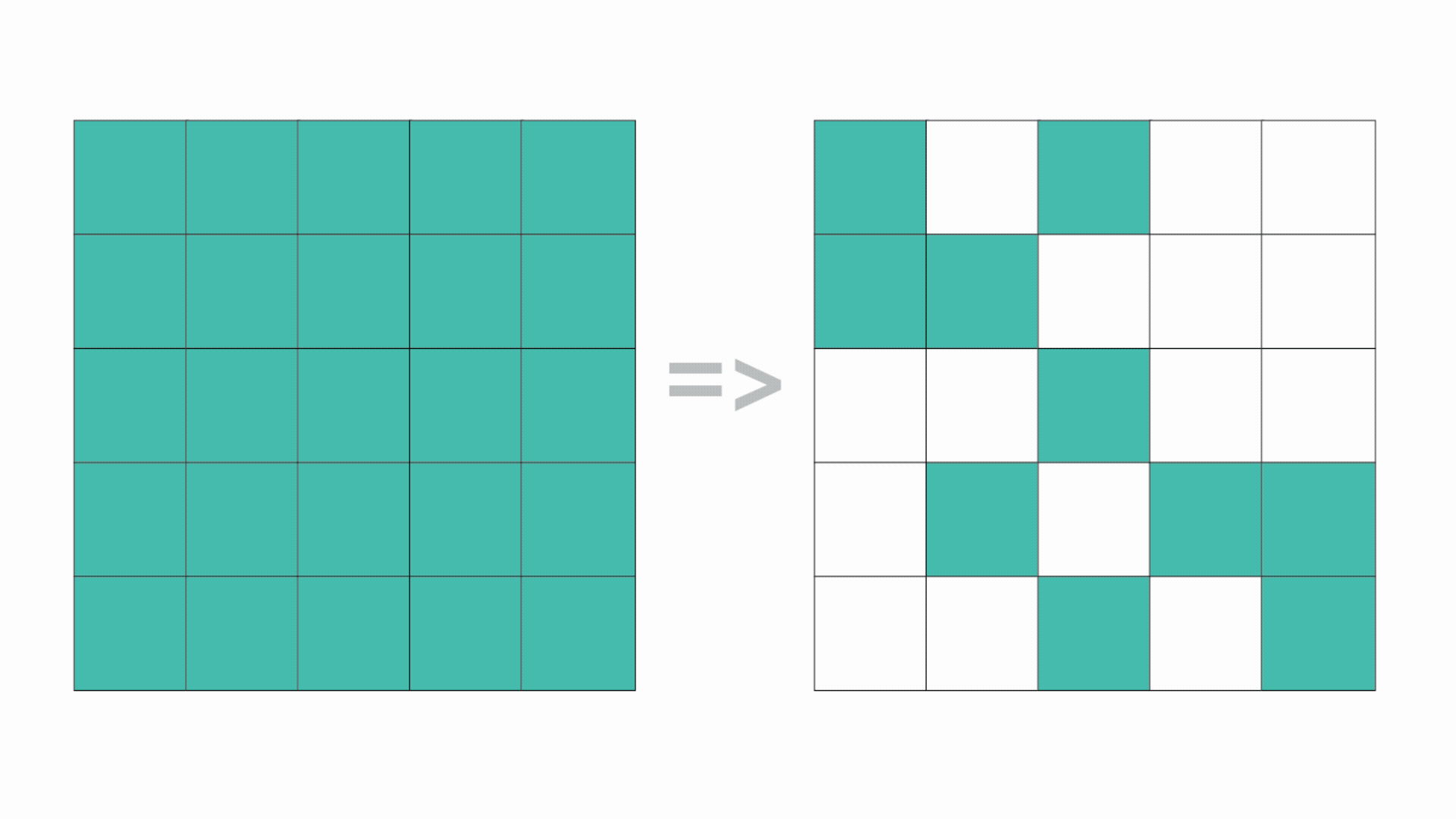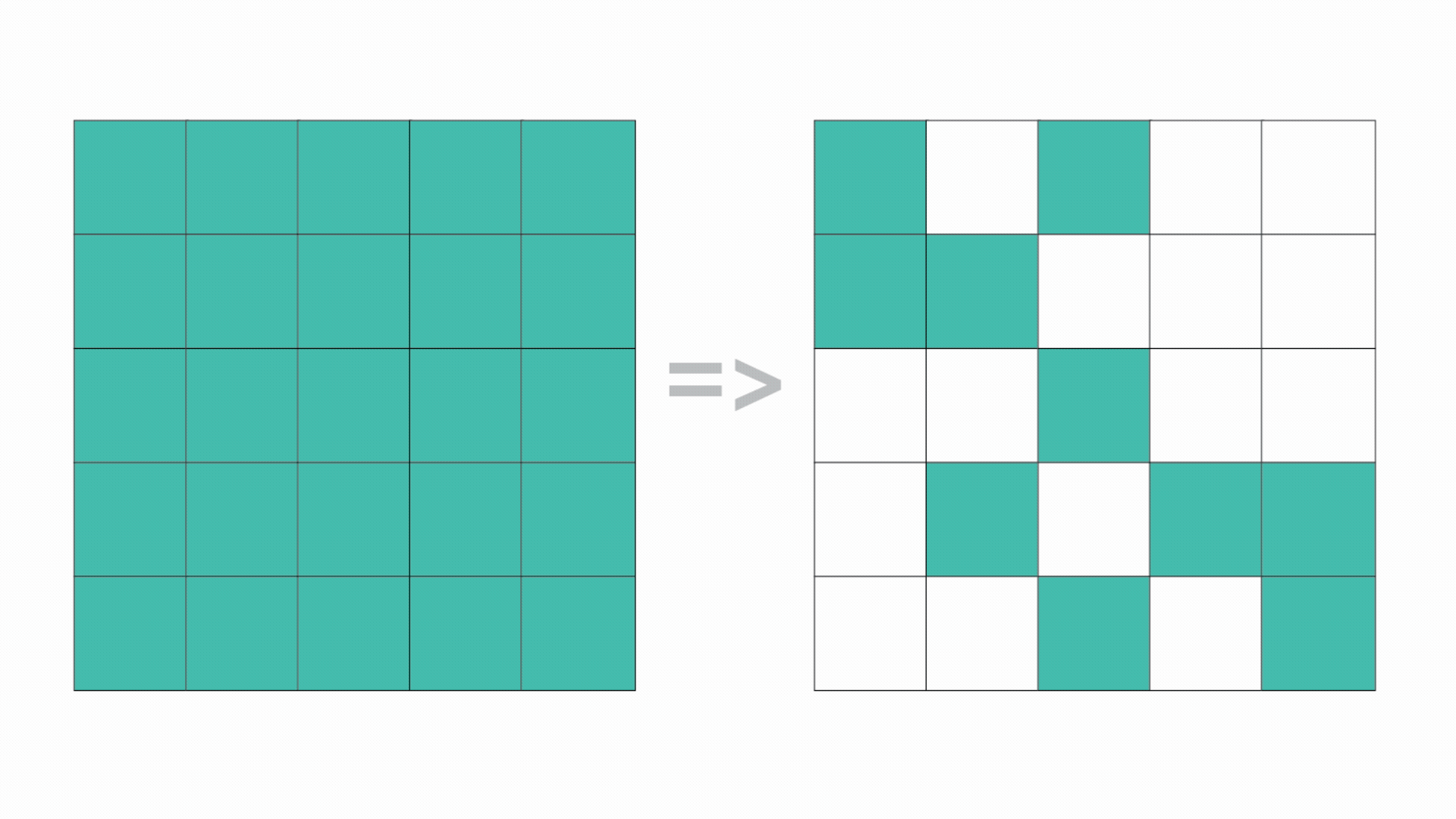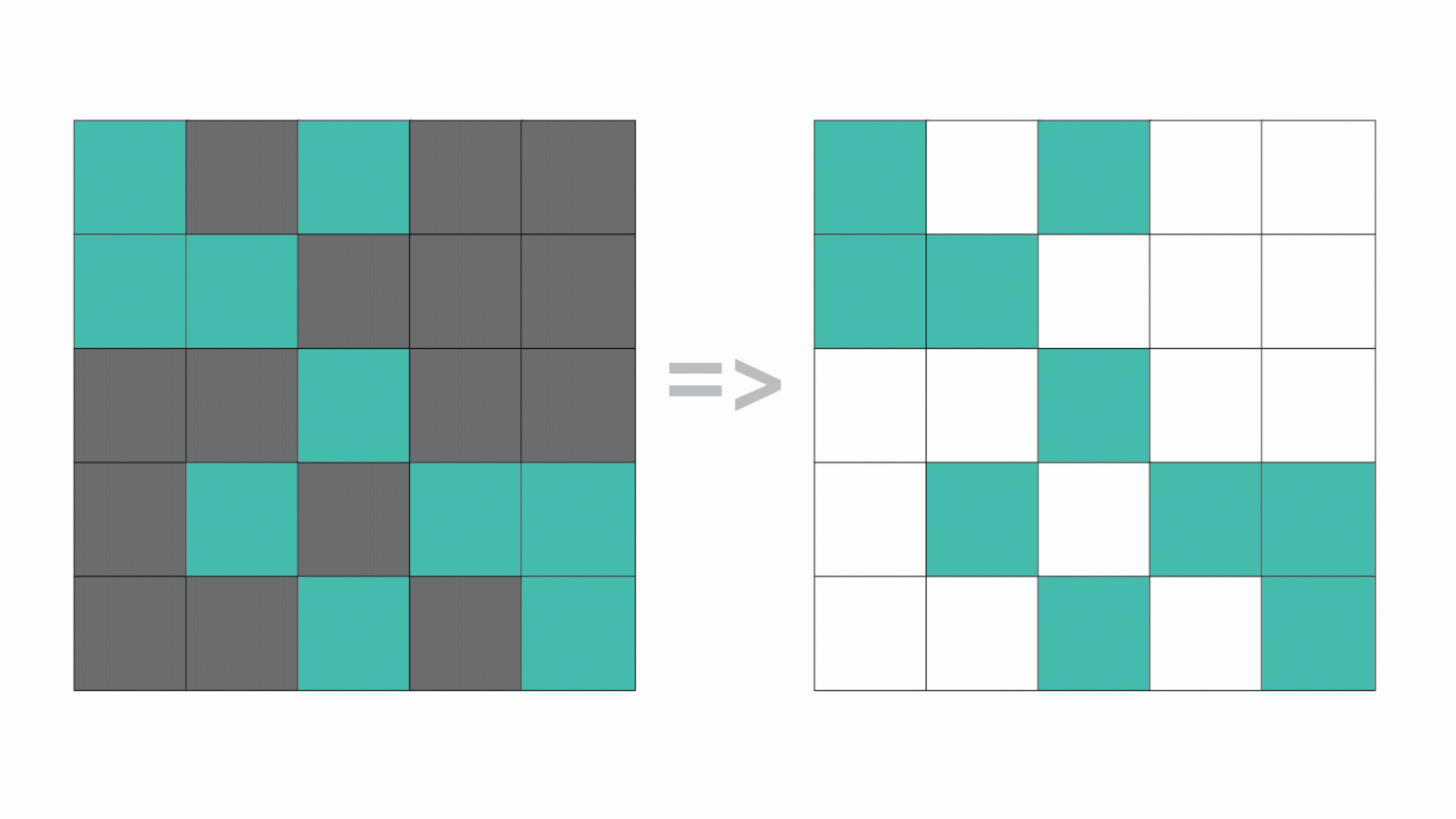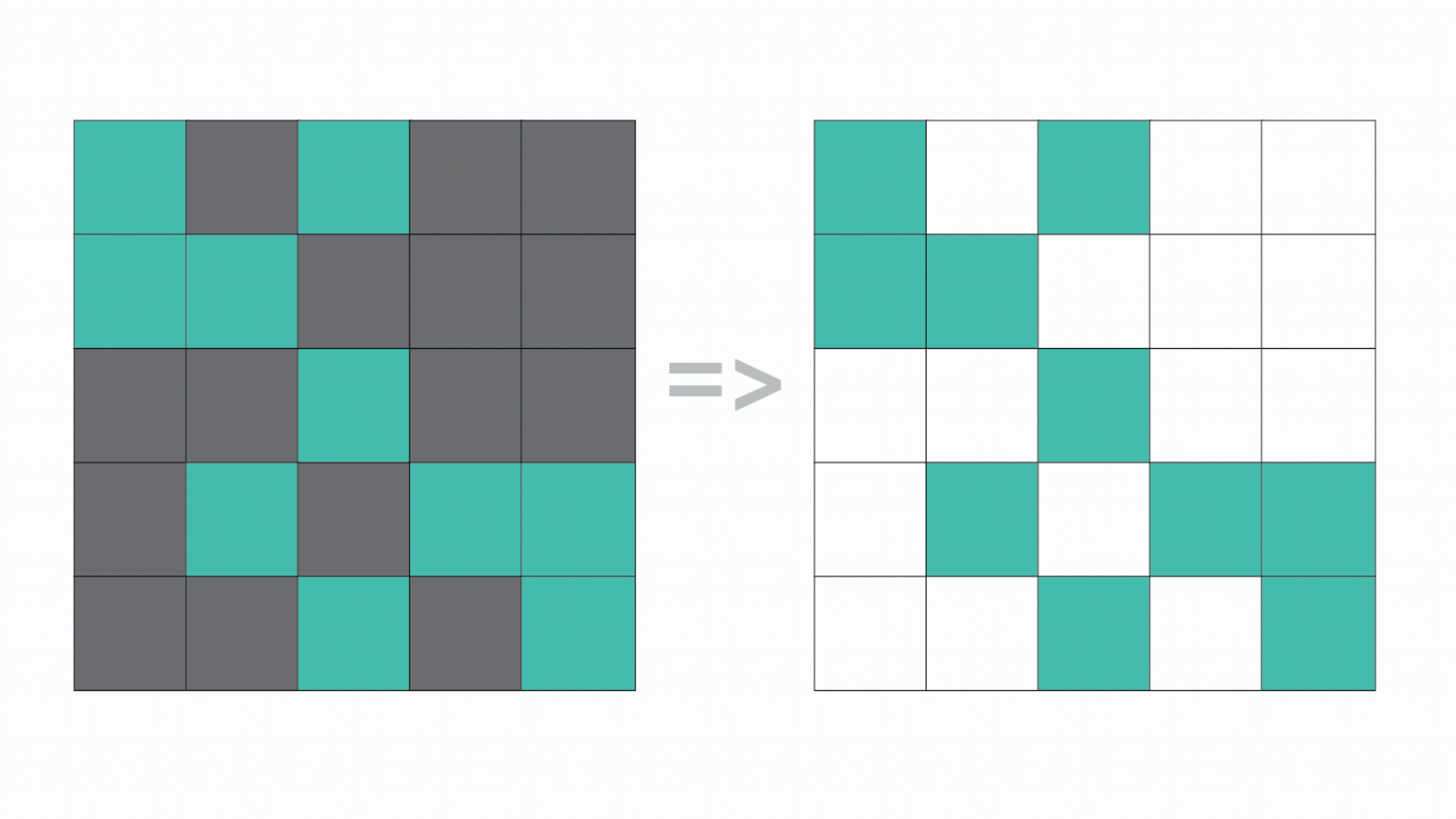
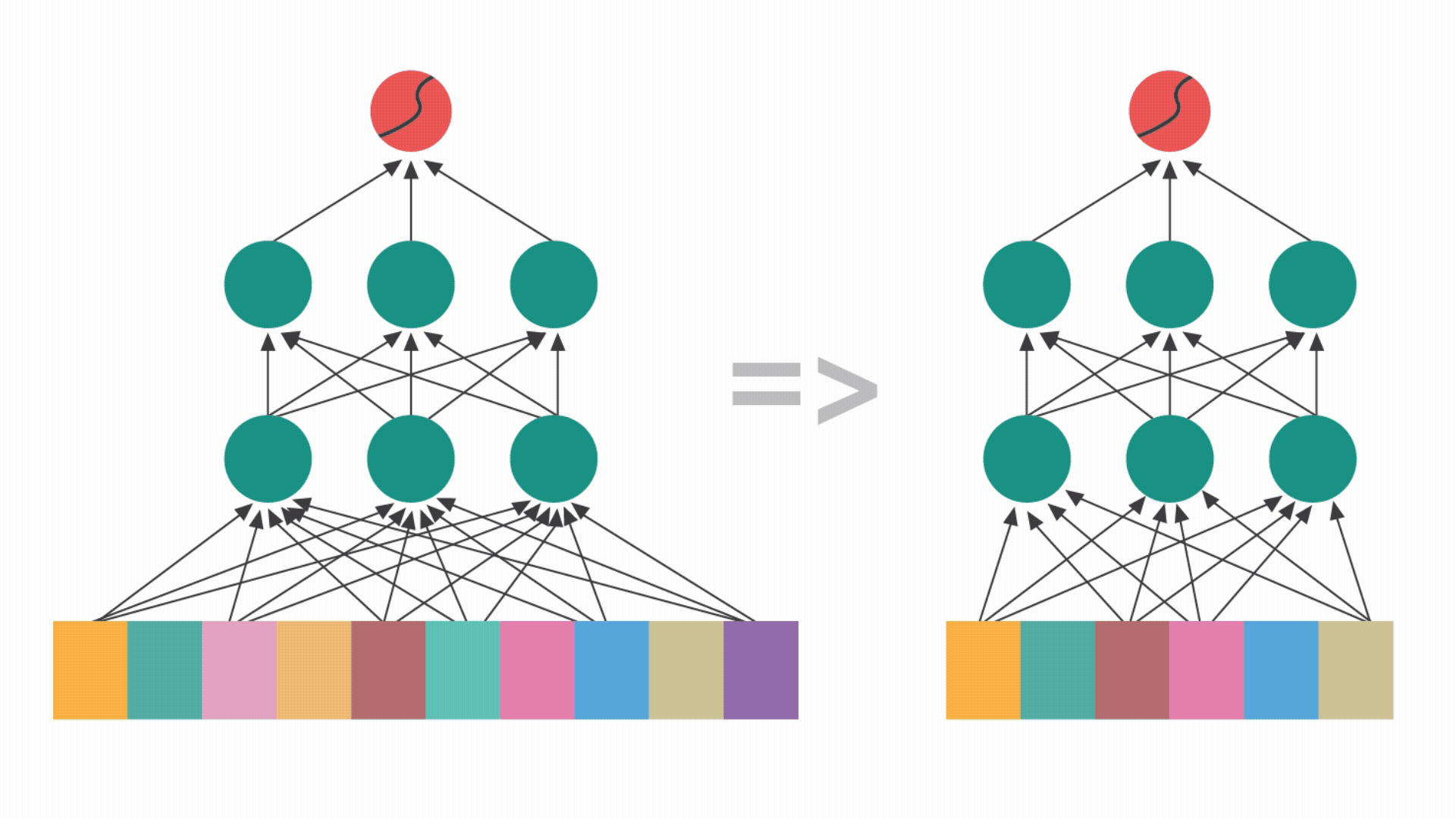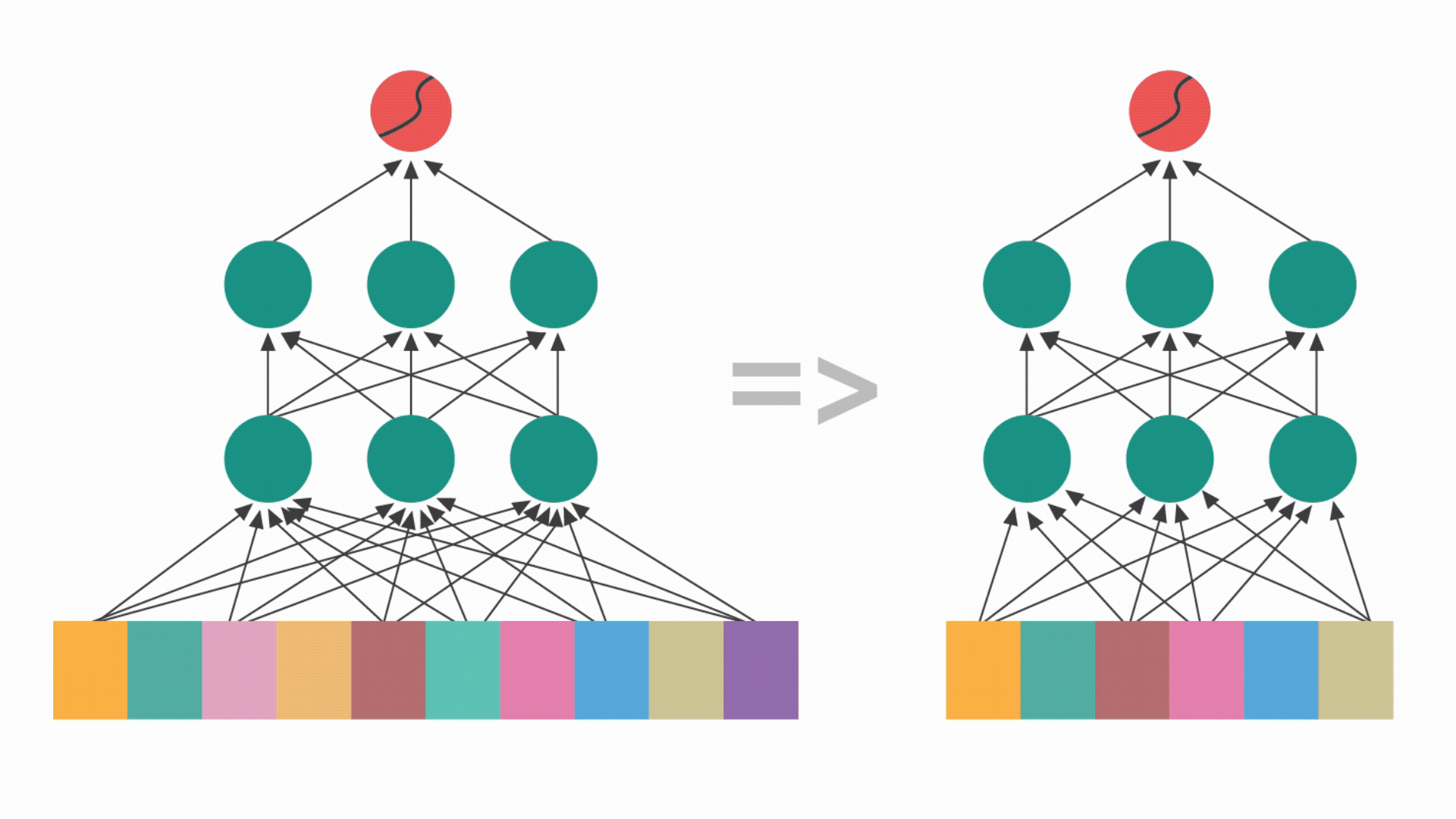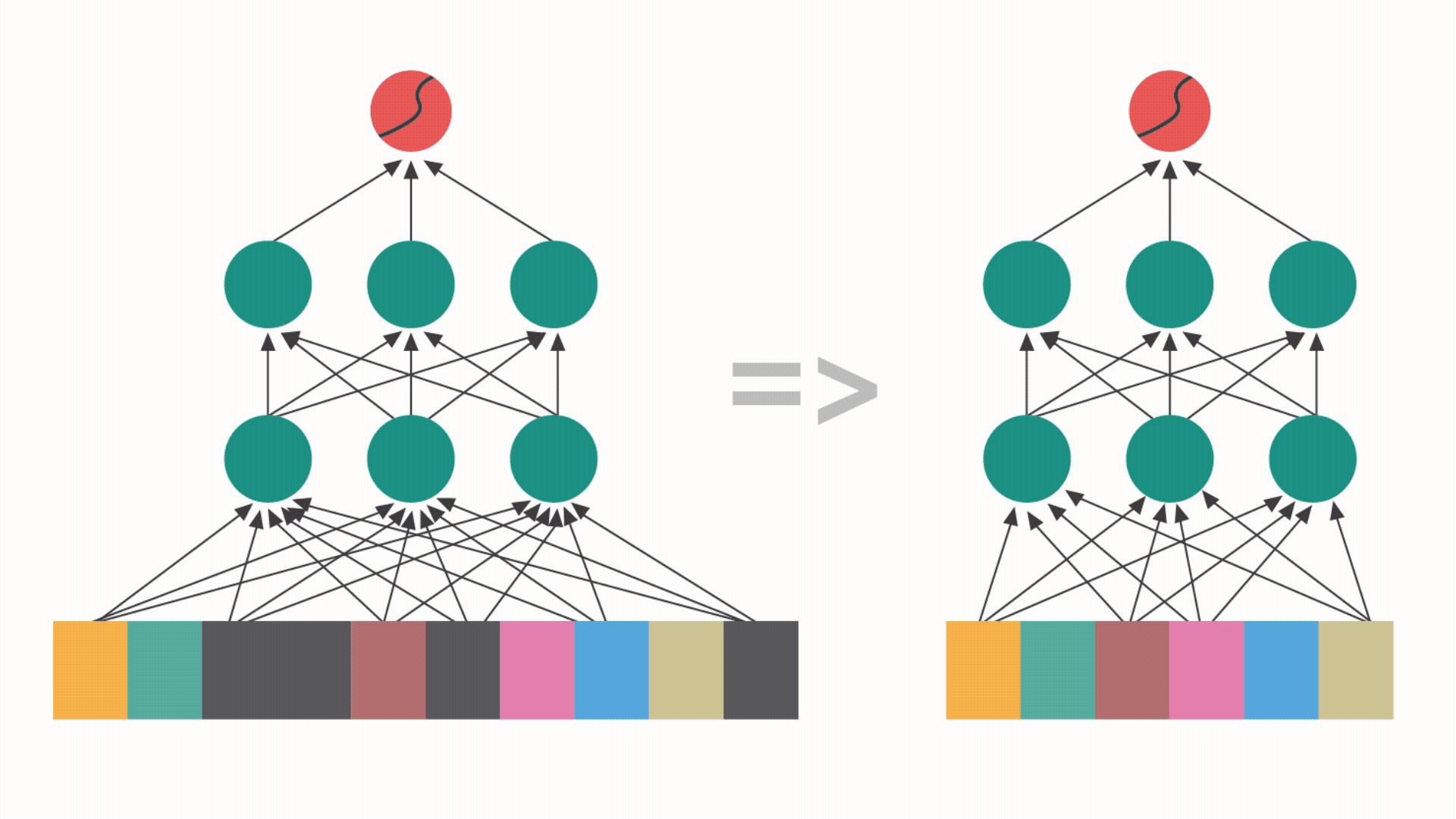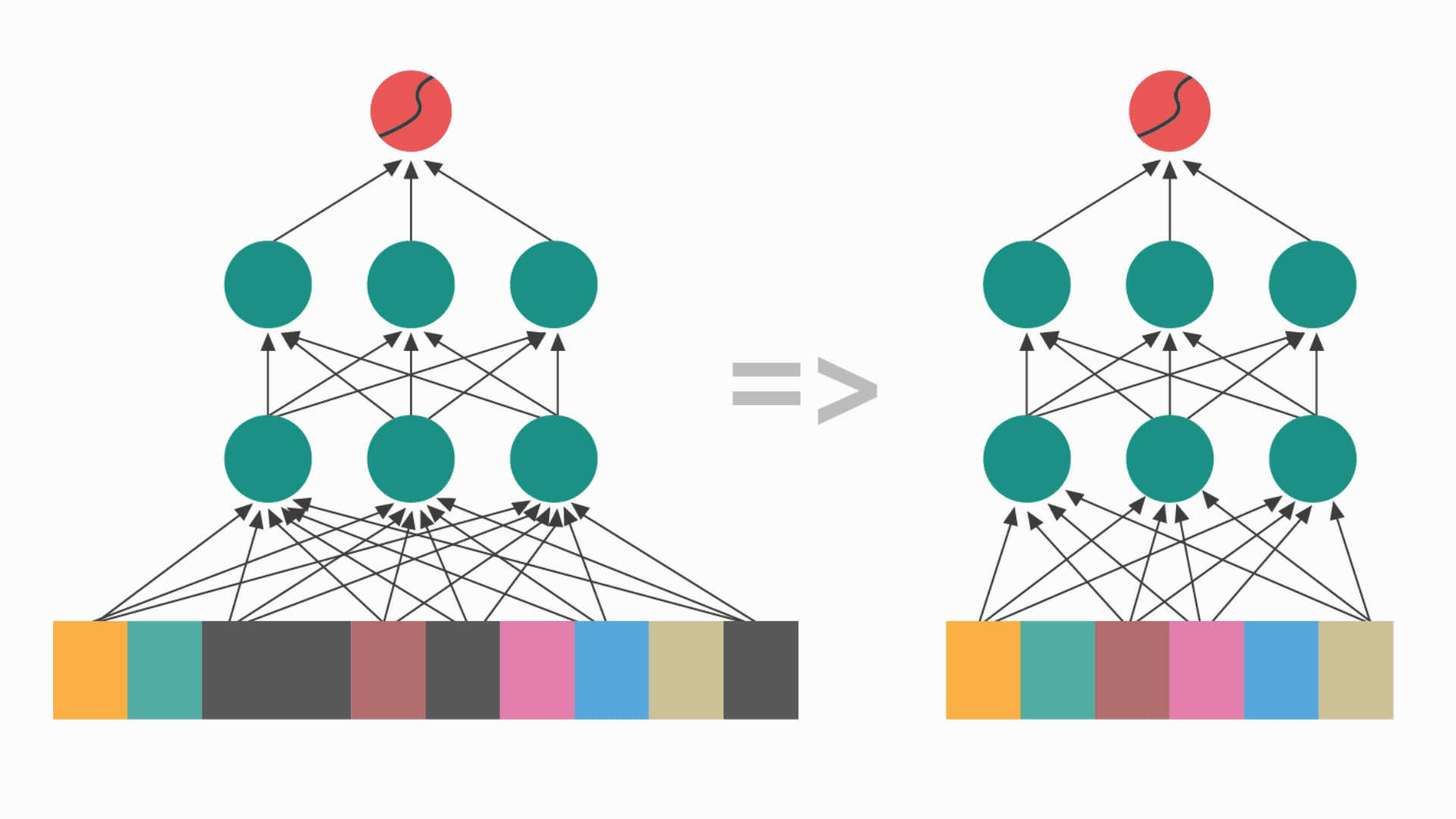
Feature Selection in neural networks: Selective pruning of input features to optimize performance. By "switching off" low-utility features, the model simplifies the learning task and reduces the risk of overfitting.
The core idea is to maintain a set of selected candidates and use them as context to find the next most informative candidate to select. This is achieved through two primary methods: greedy selection, which allows the model to make a locally optimal decision around which element to include at each step, and importance evaluation, which uses “attention scores” (numerical values indicating the importance or relevance of different input parts) to quantify the importance of every candidate in addition to the currently selected candidates. Like the attention mechanism, Sequential Attention uses softmax as an importance ranking of different components. Yet unlike the attention mechanism, it works sequentially as opposed to one shot, allowing the selection algorithm to adapt to previous selections — a crucial property for high-quality importance ranking.
Sequential Attention benefits
The primary benefits of Sequential Attention are:
- Efficiency and accuracy: By allowing parallel processing of the candidates (once the attention scores are calculated), they can be evaluated faster than in traditional sequential selection.
- Interpretability: The attention scores themselves offer a powerful diagnostic tool. Researchers can inspect the attention scores to see exactly which parts of the input a model prioritized when making a specific decision or generating a specific token. This makes the model's internal reasoning more interpretable than that of a black-box model.
- Scalability: The ability to efficiently handle a large number of candidates is crucial for large-scale feature selection for modern neural networks.
Sequential Attention in action
Feature selection
The standard feature selection method, i.e., greedy selection, is computationally expensive, as it requires re-training or re-evaluating the model for every potential feature at every step. In “Sequential Attention for Feature Selection”, we sought to replace this costly method with a much cheaper proxy: the model’s internal attention weights.
At each step, the Sequential Attention algorithm calculates attention weights for all remaining, unselected features, and permanently adds the feature with the highest attention score (the one to which the model is "paying the most attention") to the subset. The algorithm then re-runs the selection process (the process of feeding input data through a neural network, layer by layer, from input to output, to generate a prediction) and re-calculates the attention weights for the remaining features. This recalculation naturally reflects the marginal gain (how much a feature contributes to performance, given the features already selected), allowing the model to effectively identify and avoid adding redundant features.

Feature selection performance. Prediction accuracy of the proposed approach (orange) vs. baselines. Our method achieves competitive or leading results across proteomics, image, and activity recognition benchmarks, confirming its robustness.
The Sequential Attention algorithm achieved state-of-the-art results across several neural network benchmarks. Notably, it drastically improved efficiency, enabling a fast, one-pass implementation of greedy selection without the need for expensive, explicit marginal gain calculations. The study also demonstrated that when applied to a simple linear regression model, the Sequential Attention algorithm is mathematically equivalent to the established Orthogonal Matching Pursuit (OMP) algorithm. This equivalence is critical because OMP comes with provable guarantees of reliability and performance.
Block sparsification
Neural network pruning is essential for deploying large models efficiently because it reduces the model size by removing unnecessary weights. Prior research pursued two largely separate paths: differentiable pruning, which uses trainable parameters as proxies for importance, and combinatorial optimization, which uses algorithms to search for the best sparse structure.
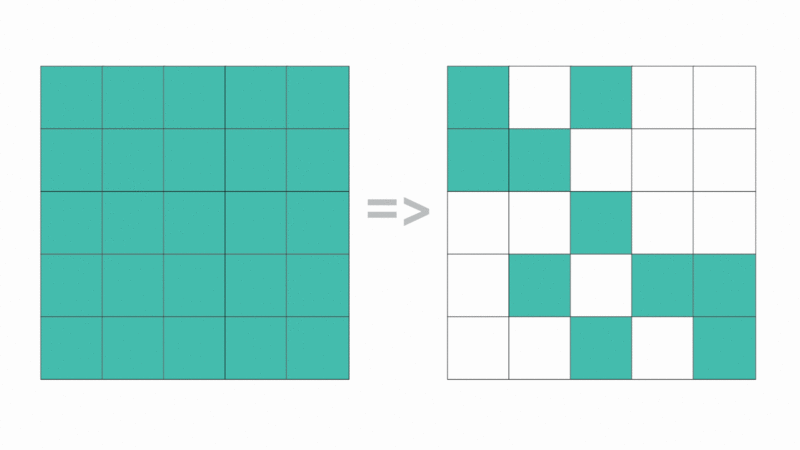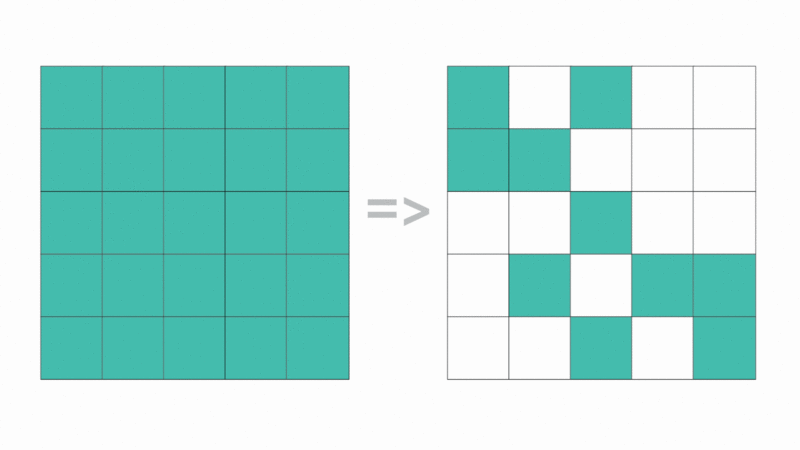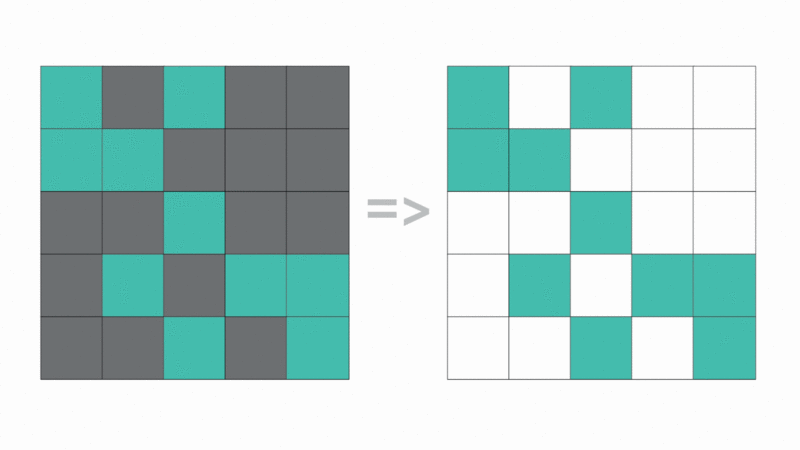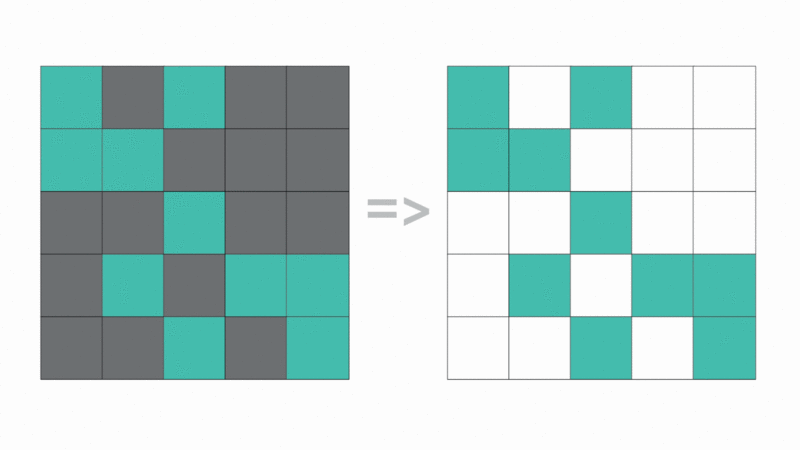
Matrix block sparsification: Identifying and zeroing out non-essential parameter blocks to optimize memory and speed. Unlike unstructured pruning, block-based sparsity leverages hardware acceleration for superior inference performance.
In “SequentialAttention++ for Block Sparsification: Differentiable Pruning Meets Combinatorial Optimization”, we sought to unite these two approaches into a coherent framework for structured neural network pruning that removes entire blocks or channels of weights to achieve real-world improvements on hardware accelerators like GPUs and TPUs.
The resulting algorithm, SequentialAttention++, provides a new way to discover the most important blocks of weight matrices, and shows significant gains in model compression and efficiency without sacrificing accuracy in ML tasks, e.g., ImageNet classification.
The future of sequential attention
As the increasing integration of AI models in science, engineering and business makes model efficiency more relevant than ever, model structure optimization is crucial for building highly effective yet efficient models. We have identified subset selection as a fundamental challenge related to model efficiency across various deep learning optimization tasks, and Sequential Attention has emerged as a pivotal technique for addressing these problems. Moving forward, we aim to extend the applications of subset selection to increasingly complex domains.
Feature engineering with real constraints
Sequential Attention has demonstrated significant quality gains and efficiency savings in optimizing the feature embedding layer in large embedding models (LEMs) used in recommender systems. These models typically have a large number of heterogeneous features with large embedding tables, and so the tasks of feature selection/pruning, feature cross search and embedding dimension optimization are highly impactful. In the future, we would like to allow these feature engineering tasks to take real inference constraints into account, enabling fully automated, continual feature engineering.
Large language model (LLM) pruning
The SequentialAttention++ paradigm is a promising direction for LLM pruning. By applying this framework we can enforce structured sparsity (e.g., block sparsity), prune redundant attention heads, embedding dimensions or entire transformer blocks, and significantly reduce model footprint and inference latency while preserving predictive performance.
Drug discovery and genomics
Feature selection is vital in the biological sciences. Sequential Attention can be adapted to efficiently extract influential genetic or chemical features from high-dimensional datasets, enhancing both the interpretability and accuracy of models in drug discovery and personalized medicine.
Current research focuses on scaling Sequential Attention to handle massive datasets and highly complex architectures more efficiently. Furthermore, ongoing efforts seek to identify superior pruned model structures and extend rigorous mathematical guarantees to real-world deep learning applications, solidifying the framework’s reliability across industries.
Subset selection is a core problem central to multiple optimization tasks in deep learning, while Sequential Attention is a key technique to solve these problems. In the future, we will explore more applications of subset selection to solve more challenging problems in broader domains
Conclusion
Sequential Attention is an effective technique for multiple large-scale subset selection problems in deep learning and plays a key role in model architecture optimization. As these techniques evolve, they will solidify the future of machine learning, guaranteeing that powerful AI remains both accurate and accessible for years to come.
Acknowledgements
We would like to express our gratitude to our research collaborators, Taisuke Yasuda, Lin Chen, Matthew Fahrbach, MohammadHossein Bateni, and Vahab Mirrokni, whose efforts have advanced the development of Sequential Attention. This work builds upon fundamental research in differentiable subset selection and combinatorial optimization to create more efficient and accessible AI models.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 7, 2026
The power of collaboration: How we can reduce traffic congestion- Algorithms & Theory ·
- Climate & Sustainability ·
- Data Mining & Modeling
-

June 25, 2026
Optimizing cloud economics with linear elastic caching- Algorithms & Theory ·
- Data Management