
Sensible Agent: A framework for unobtrusive interaction with proactive AR agents
September 18, 2025
Ruofei Du, Interactive Perception & Graphics Lead, and Geonsun Lee, Student Researcher, Google XR
Sensible Agent is a research prototype that enables AR agents to proactively adapt what they suggest and how they interact, using real-time context, including gaze, hand availability, and environmental noise.
Quick links
Recent innovations, such as Google's Project Astra, exemplify the potential of proactive agents embedded in augmented reality (AR) glasses to offer intelligent assistance that anticipates user needs and seamlessly integrates into everyday life. These agents promise remarkable convenience, from effortlessly navigating unfamiliar transit hubs to discreetly offering timely suggestions in crowded spaces. Yet, today’s agents remain constrained by a significant limitation: they predominantly rely on explicit verbal commands from users. This requirement can be awkward or disruptive in social environments, cognitively taxing in time-sensitive scenarios, or simply impractical.
To address these challenges, we introduce Sensible Agent, published at UIST 2025, a framework designed for unobtrusive interaction with proactive AR agents. Sensible Agent is an advancement to our prior research in Human I/O and fundamentally reshapes this interaction by anticipating user intentions and determining the best approach to deliver assistance. It leverages real-time multimodal context sensing, subtle gestures, gaze input, and minimal visual cues to offer unobtrusive, contextually-appropriate assistance. This marks a crucial step toward truly integrated, socially aware AR systems that respect user context, minimize cognitive disruption, and make proactive digital assistance practical for daily life.
Sensible Agent framework
At its core, Sensible Agent consists of two interconnected modules for (1) understanding "what" to assist with, and (2) determining "how" to provide assistance. First, Sensible Agent leverages advanced multimodal sensing using egocentric cameras and environmental context detection to understand a user’s current assistance needs. Whether you're navigating a crowded museum or rushing through a grocery store, the agent proactively decides the most helpful action, such as providing quick translations, suggesting popular dishes at a new restaurant, or quietly displaying a grocery list.
Equally important, Sensible Agent intelligently chooses the least intrusive and most appropriate interaction method based on social context. For instance, if your hands are busy cooking, the agent might enable confirmation via a head nod. In a noisy environment, it might discreetly show visual icons instead of speaking out loud. This adaptive modality selection ensures assistance is always conveniently delivered while avoiding significant disruptions.

Sensible Agent Demo: The AR agent (left) detects context, (middle) proactively suggests actions, and (right) allows users to respond unobtrusively with a “thumbs up” gesture.
Building the Sensible Agent prototype
To bring this concept to life, we implemented Sensible Agent as a fully functional prototype running on Android XR and WebXR, integrated with powerful multimodal AI models. The prototype includes four components: (1) a context parser that enables it to understand the scene, (2) a proactive query generator that determines what assistance is needed, (3) an interaction module that decides how to best offer assistance, and (4) a response generator that delivers the assistance.
- Context parser: Understanding the scene
- First, the system initiates a context parser to understand the user's current situation. The context parser uses a vision-language model (VLM) to analyze the input frame from the headset’s camera and YAMNet, a pre-trained audio event classifier, to process the noise level in the environment. This process results in a set of parsed contexts, such as high-level activity or the user’s location.
- Proactive query generator: Deciding “what” to do
- Based on the parsed context, the proactive query generator identifies the most helpful action. It uses chain-of-thought (CoT) reasoning to prompt the model to decompose multi-step problems into intermediate steps. This reasoning is guided by six examples derived from a data collection study (few-shot learning).
- The model's output is a complete agent suggestion, including the action (e.g., Recommend Dish), the query format (Multi-choice/Binary Choice/Icon), and the presentation modality (Audio Only/Visual Only/Both).
- Interaction module: Deciding “how” to interact
- This module handles the “how” of the interaction, managing both output and input.
- The UI Manager takes the suggestion and presents it to the user. It either renders a visual panel on the screen or uses text-to-speech (TTS) to generate an audio prompt.
- The input modality manager then enables the most appropriate ways for the user to respond. Based on the initial context (e.g., hands are busy, environment is loud), it activates one or more modalities, including head gestures, hand gestures, verbal commands, or gaze.
- Response generator: Delivering the assistance
- Once the user selects an option (e.g., with a nod of the head), the Response Generator completes the task. It uses an LLM to formulate a helpful, natural language answer, which is then converted to audio via TTS and played to the user.
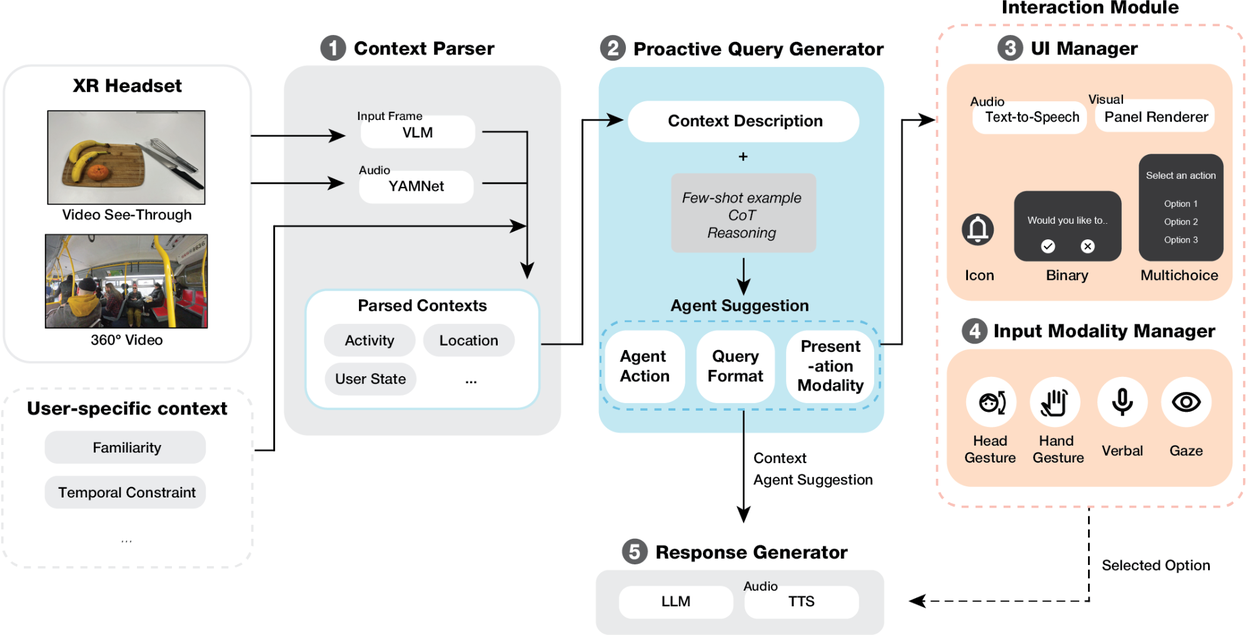
System architecture of Sensible Agent prototype. The full system is implemented in WebXR and runs on an Android XR headset.
User study
To evaluate Sensible Agent’s performance, we conducted a structured user study comparing it with a conventional, voice-controlled AR assistant modeled after Project Astra. The goal was simple: determine whether Sensible Agent could reduce interaction effort and disruption while maintaining usability and comfort in realistic everyday scenarios.
The study involved 10 participants, each completing 12 realistic scenarios using an Android XR headset. To simulate realistic AR use, these scenarios were presented either as: (1) 360° immersive videos for scenarios involving public transport, restaurant dining, and grocery shopping, or (2) physically staged AR environments for museum visits, exercising, and cooking tasks. The scenarios were set across the following six everyday activities:
- Reading a restaurant menu
- Commuting via public transport
- Grocery shopping
- Visiting a museum
- Working out at a gym
- Cooking in a kitchen
Participants experienced each scenario in two conditions:
- Baseline (using a voice-controlled assistant): Users explicitly initiated interactions via voice commands (e.g., "What's the vegetarian option?" or "Tell me about this exhibit").
- Sensible Agent: The system proactively offered context-adapted suggestions using minimally intrusive methods, including visual icons, subtle audio cues, and gesture-based interactions (e.g., head nods, gaze).
Participants experienced all scenarios sequentially, alternating between unfamiliar contexts (first-time scenarios) and more familiar or contextually constrained variants (e.g., high cognitive load, hands occupied). To ensure a naturalistic flow, scenarios were interleaved to avoid repetition of similar tasks back-to-back.

User study participants either experienced a set of scenarios in 360 videos or Video See-Through (VST) AR, both with the baseline and Sensible Agent.
Results
We compared Sensible Agent to a conventional, voice-controlled AR assistant baseline. We measured cognitive load using the NASA Task Load Index (NASA-TLX), overall usability with the System Usability Scale (SUS), user preference on a 7-point Likert scale, and total interaction time.
The most significant finding was the reduction in cognitive workload. The NASA-TLX data showed that on a 100-point scale for mental demand, the average score for Sensible Agent was 21.1, compared to 65.0 for the baseline with a statistically significant difference (𝑝 < .001). We saw a similar significant reduction in perceived effort (𝑝 = .0039), which suggests that the proactive system successfully offloaded the mental work of forming a query.
Regarding usability, both systems performed well, with no statistically significant difference between their SUS scores (𝑝 = .11). However, participants expressed a strong and statistically significant preference for Sensible Agent (𝑝 = .0074). On a 7-point scale, the average preference rating was 6.0 for Sensible Agent, compared to 3.8 for the baseline.
For the interaction time, logged from the moment a prompt was triggered to the final system response to the user's input, the baseline was faster (μ = 16.4s) compared to Sensible Agent (μ = 28.5s). This difference is an expected trade-off of the system’s two-step interaction flow, where the agent first proposes an action and the user then confirms it. The strong user preference for Sensible Agent suggests this trade-off was acceptable, particularly in social contexts where discretion and minimal user effort were important.
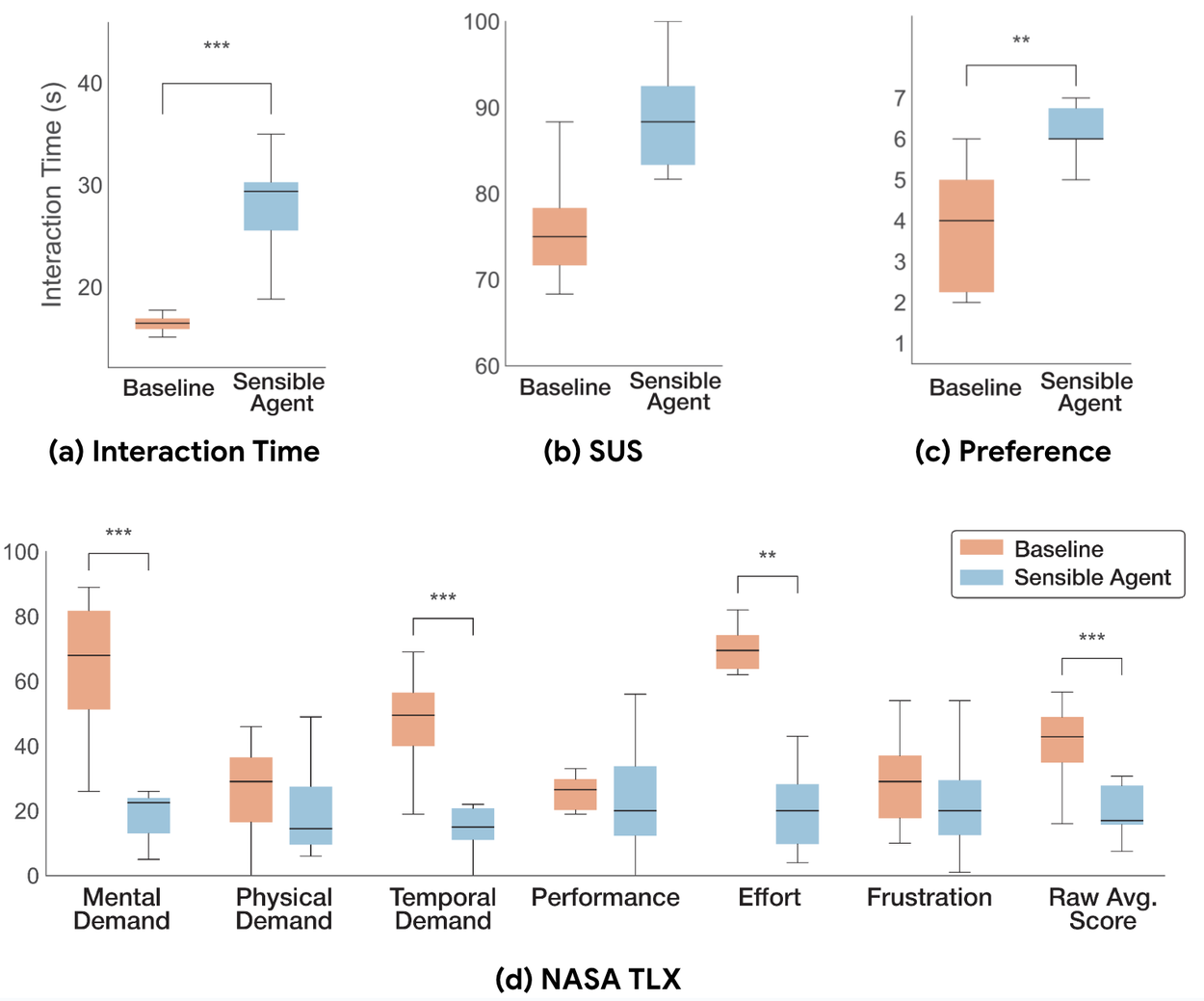
Quantitative results of (a) interaction time, (b) SUS scores, (c) preference, and (d) Raw NASA TLX scores measured in our user study. The statistical significance is annotated with ∗, ∗∗, or ∗∗∗ (representing 𝑝 < .05, 𝑝 < .01, and 𝑝 < .001, respectively).
A key insight is that proactivity does more than reduce effort; it reshapes the user's relationship with the agent. Participants felt Sensible Agent was less like a tool and more like a collaborative partner. Its subtle, non-verbal inputs mirrored social cues, fostering rapport and making interactions feel more natural, which suggests the how of an interaction is as important as the what in making an agent feel like an engaged assistant.
This shift in perception was especially pronounced in high-pressure or socially-engaged environments. Our findings reinforce that relevance alone is not enough; effective agents must align their communication modality with user availability, attentional state, and social context.
Conclusion and future directions
In this research, we demonstrated that proactive AR assistance can be made both intelligent and unobtrusive by jointly reasoning over what to suggest and how to deliver it. By integrating multimodal sensing and real-time adaptation into both decision-making and interface design, our framework addresses longstanding friction in human-agent interaction.
Looking ahead, this research can be expanded to real-life applications by integrating longer-term history to support personalization over time, scaling the system to work across devices and environments, and exploring applications in smart homes and physical robotics, while keeping users and user data safe with on-device inference. As AR becomes increasingly embedded in everyday life, systems like Sensible Agent lay the groundwork for digital agents that efficiently and attentively support users.
Acknowledgements
This work is a joint collaboration across multiple teams at Google. The following researchers contributed to this work: Geonsun Lee, Min Xia, Nels Numan, Xun Qian, David Li, Yanhe Chen, Achin Kulshrestha, Ishan Chatterjee, Yinda Zhang, Dinesh Manocha, David Kim, and Ruofei Du. We would like to thank Zhongyi Zhou, Vikas Bahirwani, Jessica Bo, Zheng Xu, Renhao Liu for their feedback and discussion on our early-stage proposal. We thank Alex Olwal, Adarsh Kowdle, and Guru Somadder for the strategic guidance and thoughtful reviews.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence


