Semantic Image Segmentation with DeepLab in TensorFlow
March 12, 2018
Posted by Liang-Chieh Chen and Yukun Zhu, Software Engineers, Google Research
Quick links
Semantic image segmentation, the task of assigning a semantic label, such as “road”, “sky”, “person”, “dog”, to every pixel in an image enables numerous new applications, such as the synthetic shallow depth-of-field effect shipped in the portrait mode of the Pixel 2 and Pixel 2 XL smartphones and mobile real-time video segmentation. Assigning these semantic labels requires pinpointing the outline of objects, and thus imposes much stricter localization accuracy requirements than other visual entity recognition tasks such as image-level classification or bounding box-level detection.

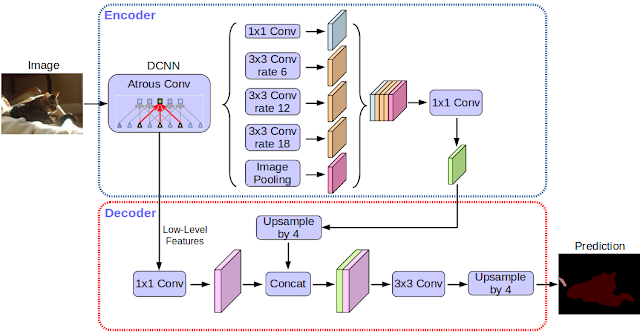
Since the first incarnation of our DeepLab model [4] three years ago, improved CNN feature extractors, better object scale modeling, careful assimilation of contextual information, improved training procedures, and increasingly powerful hardware and software have led to improvements with DeepLab-v2 [5] and DeepLab-v3 [6]. With DeepLab-v3+, we extend DeepLab-v3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further apply the depthwise separable convolution to both atrous spatial pyramid pooling [5, 6] and decoder modules, resulting in a faster and stronger encoder-decoder network for semantic segmentation.

Acknowledgements
We would like to thank the support and valuable discussions with Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille (co-authors of DeepLab-v1 and -v2), as well as Mark Sandler, Andrew Howard, Menglong Zhu, Chen Sun, Derek Chow, Andre Araujo, Haozhi Qi, Jifeng Dai, and the Google Mobile Vision team.
References
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation, Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam, arXiv: 1802.02611, 2018.
- Xception: Deep Learning with Depthwise Separable Convolutions, François Chollet, Proc. of CVPR, 2017.
- Deformable Convolutional Networks — COCO Detection and Segmentation Challenge 2017 Entry, Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, and Jifeng Dai, ICCV COCO Challenge Workshop, 2017.
- Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille, Proc. of ICLR, 2015.
- Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille, TPAMI, 2017.
- Rethinking Atrous Convolution for Semantic Image Segmentation, Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam, arXiv:1706.05587, 2017.
* DeepLab-v3+ is not used to power Pixel 2's portrait mode or real time video segmentation. These are mentioned in the post as examples of features this type of technology can enable.↩
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯