Self-Supervised Learning Advances Medical Image Classification
October 13, 2021
Posted by Shekoofeh Azizi, AI Resident, Google Research
Quick links
In recent years, there has been increasing interest in applying deep learning to medical imaging tasks, with exciting progress in various applications like radiology, pathology and dermatology. Despite the interest, it remains challenging to develop medical imaging models, because high-quality labeled data is often scarce due to the time-consuming effort needed to annotate medical images. Given this, transfer learning is a popular paradigm for building medical imaging models. With this approach, a model is first pre-trained using supervised learning on a large labeled dataset (like ImageNet) and then the learned generic representation is fine-tuned on in-domain medical data.
Other more recent approaches that have proven successful in natural image recognition tasks, especially when labeled examples are scarce, use self-supervised contrastive pre-training, followed by supervised fine-tuning (e.g., SimCLR and MoCo). In pre-training with contrastive learning, generic representations are learned by simultaneously maximizing agreement between differently transformed views of the same image and minimizing agreement between transformed views of different images. Despite their successes, these contrastive learning methods have received limited attention in medical image analysis and their efficacy is yet to be explored.
In “Big Self-Supervised Models Advance Medical Image Classification”, to appear at the International Conference on Computer Vision (ICCV 2021), we study the effectiveness of self-supervised contrastive learning as a pre-training strategy within the domain of medical image classification. We also propose Multi-Instance Contrastive Learning (MICLe), a novel approach that generalizes contrastive learning to leverage special characteristics of medical image datasets. We conduct experiments on two distinct medical image classification tasks: dermatology condition classification from digital camera images (27 categories) and multilabel chest X-ray classification (5 categories). We observe that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images, significantly improves the accuracy of medical image classifiers. Specifically, we demonstrate that self-supervised pre-training outperforms supervised pre-training, even when the full ImageNet dataset (14M images and 21.8K classes) is used for supervised pre-training.
SimCLR and Multi Instance Contrastive Learning (MICLe)
Our approach consists of three steps: (1) self-supervised pre-training on unlabeled natural images (using SimCLR); (2) further self-supervised pre-training using unlabeled medical data (using either SimCLR or MICLe); followed by (3) task-specific supervised fine-tuning using labeled medical data.
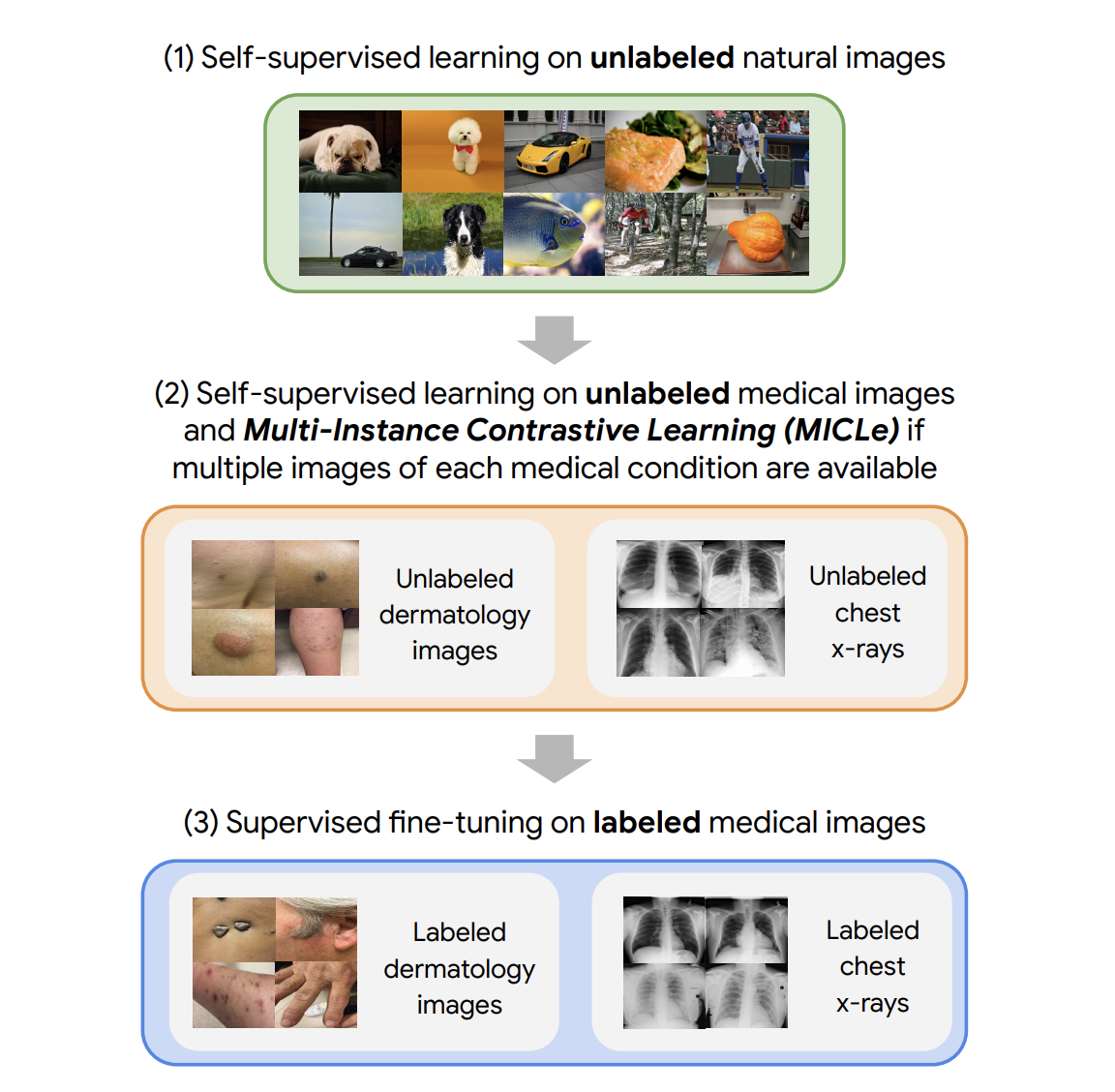 |
| Our approach comprises three steps: (1) Self-supervised pre-training on unlabeled ImageNet using SimCLR (2) Additional self-supervised pre-training using unlabeled medical images. If multiple images of each medical condition are available, a novel Multi-Instance Contrastive Learning (MICLe) strategy is used to construct more informative positive pairs based on different images. (3) Supervised fine-tuning on labeled medical images. Note that unlike step (1), steps (2) and (3) are task and dataset specific. |
After the initial pre-training with SimCLR on unlabeled natural images is complete, we train the model to capture the special characteristics of medical image datasets. This, too, can be done with SimCLR, but this method constructs positive pairs only through augmentation and does not readily leverage patients' meta data for positive pair construction. Alternatively, we use MICLe, which uses multiple images of the underlying pathology for each patient case, when available, to construct more informative positive pairs for self-supervised learning. Such multi-instance data is often available in medical imaging datasets — e.g., frontal and lateral views of mammograms, retinal fundus images from each eye, etc.
Given multiple images of a given patient case, MICLe constructs a positive pair for self-supervised contrastive learning by drawing two crops from two distinct images from the same patient case. Such images may be taken from different viewing angles and show different body parts with the same underlying pathology. This presents a great opportunity for self-supervised learning algorithms to learn representations that are robust to changes of viewpoint, imaging conditions, and other confounding factors in a direct way. MICLe does not require class label information and only relies on different images of an underlying pathology, the type of which may be unknown.
 |
| MICLe generalizes contrastive learning to leverage special characteristics of medical image datasets (patient metadata) to create realistic augmentations, yielding further performance boost of image classifiers. |
Combining these self-supervised learning strategies, we show that even in a highly competitive production setting we can achieve a sizable gain of 6.7% in top-1 accuracy on dermatology skin condition classification and an improvement of 1.1% in mean AUC on chest X-ray classification, outperforming strong supervised baselines pre-trained on ImageNet (the prevailing protocol for training medical image analysis models). In addition, we show that self-supervised models are robust to distribution shift and can learn efficiently with only a small number of labeled medical images.
Comparison of Supervised and Self-Supervised Pre-training
Despite its simplicity, we observe that pre-training with MICLe consistently improves the performance of dermatology classification over the original method of pre-training with SimCLR under different pre-training dataset and base network architecture choices. Using MICLe for pre-training, translates to (1.18 ± 0.09)% increase in top-1 accuracy for dermatology classification over using SimCLR. The results demonstrate the benefit accrued from utilizing additional metadata or domain knowledge to construct more semantically meaningful augmentations for contrastive pre-training. In addition, our results suggest that wider and deeper models yield greater performance gains, with ResNet-152 (2x width) models often outperforming ResNet-50 (1x width) models or smaller counterparts.
 |
| Comparison of supervised and self-supervised pre-training, followed by supervised fine-tuning using two architectures on dermatology and chest X-ray classification. Self-supervised learning utilizes unlabeled domain-specific medical images and significantly outperforms supervised ImageNet pre-training. |
Improved Generalization with Self-Supervised Models
For each task we perform pretraining and fine-tuning using the in-domain unlabeled and labeled data respectively. We also use another dataset obtained in a different clinical setting as a shifted dataset to further evaluate the robustness of our method to out-of-domain data. For the chest X-ray task, we note that self-supervised pre-training with either ImageNet or CheXpert data improves generalization, but stacking them both yields further gains. As expected, we also note that when only using ImageNet for self-supervised pre-training, the model performs worse compared to using only in-domain data for pre-training.
To test the performance under distribution shift, for each task, we held out additional labeled datasets for testing that were collected under different clinical settings. We find that the performance improvement in the distribution-shifted dataset (ChestX-ray14) by using self-supervised pre-training (both using ImageNet and CheXpert data) is more pronounced than the original improvement on the CheXpert dataset. This is a valuable finding, as generalization under distribution shift is of paramount importance to clinical applications. On the dermatology task, we observe similar trends for a separate shifted dataset that was collected in skin cancer clinics and had a higher prevalence of malignant conditions. This demonstrates that the robustness of the self-supervised representations to distribution shifts is consistent across tasks.
 |
| Evaluation of models on distribution-shifted datasets for the chest-xray interpretation task. We use the model trained on in-domain data to make predictions on an additional shifted dataset without any further fine-tuning (zero-shot transfer learning). We observe that self-supervised pre-training leads to better representations that are more robust to distribution shifts. |
 |
| Evaluation of models on distribution-shifted datasets for the dermatology task. Our results generally suggest that self-supervised pre-trained models can generalize better to distribution shifts with MICLe pre-training leading to the most gains. |
Improved Label Efficiency
We further investigate the label-efficiency of the self-supervised models for medical image classification by fine-tuning the models on different fractions of labeled training data. We use label fractions ranging from 10% to 90% for both Derm and CheXpert training datasets and examine how the performance varies using the different available label fractions for the dermatology task. First, we observe that pre-training using self-supervised models can compensate for low label efficiency for medical image classification, and across the sampled label fractions, self-supervised models consistently outperform the supervised baseline. These results also suggest that MICLe yields proportionally higher gains when fine-tuning with fewer labeled examples. In fact, MICLe is able to match baselines using only 20% of the training data for ResNet-50 (4x) and 30% of the training data for ResNet152 (2x).
 |
| Top-1 accuracy for dermatology condition classification for MICLe, SimCLR, and supervised models under different unlabeled pre-training datasets and varied sizes of label fractions. MICLe is able to match baselines using only 20% of the training data for ResNet-50 (4x). |
Conclusion
Supervised pre-training on natural image datasets is commonly used to improve medical image classification. We investigate an alternative strategy based on self-supervised pre-training on unlabeled natural and medical images and find that it can significantly improve upon supervised pre-training, the standard paradigm for training medical image analysis models. This approach can lead to models that are more accurate and label efficient and are robust to distribution shifts. In addition, our proposed Multi-Instance Contrastive Learning method (MICLe) enables the use of additional metadata to create realistic augmentations, yielding further performance boost of image classifiers.
Self-supervised pre-training is much more scalable than supervised pre-training because class label annotation is not required. We hope this paper will help popularize the use of self-supervised approaches in medical image analysis yielding label efficient and robust models suited for clinical deployment at scale in the real world.
Acknowledgements
This work involved collaborative efforts from a multidisciplinary team of researchers, software engineers, clinicians, and cross-functional contributors across Google Health and Google Brain. We thank our co-authors: Basil Mustafa, Fiona Ryan, Zach Beaver, Jan Freyberg, Jon Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, and Mohammad Norouzi. We also thank Yuan Liu from Google Health for valuable feedback and our partners for access to the datasets used in the research.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence