
Rich human feedback for text-to-image generation
June 26, 2024
Junfeng He, Research Scientist, Google Research, and Gang Li, Software Engineer, Google Deepmind
Quick links
Recent text-to-image generation (T2I) models, such as Stable Diffusion and Imagen, have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues like artifacts (e.g., distorted objects, text and body parts), misalignment with text descriptions, and low aesthetic quality. For example, the prompt in the image below says, “A panda riding a motorcycle”, however the generated image shows two pandas, with additional undesired artifacts, including distorted panda noses and wheel spokes.
Inspired by the success of reinforcement learning from human feedback (RLHF) for large language models (LLMs), we explore whether learning from human feedback (LHF) can help improve image generation models. When applied to LLMs, human feedback can range from simple preference ratings (e.g., “thumb up or down”, “A or B”), to more detailed responses like rewriting a problematic answer. However, current work on LHF for T2I mainly focuses on simple responses like preference ratings, since fixing a problematic image often requires advanced skills (e.g., editing), making it too difficult and time consuming.
In "Rich Human Feedback for Text-to-Image Generation", we design a process to obtain rich human feedback for T2I that is both specific (e.g., telling us what is wrong about the image and where) and easy to obtain. We demonstrate the feasibility and benefits of LHF for T2I. Our main contributions are threefold:
- We curate and release RichHF-18K, a human feedback dataset covering 18K images generated by Stable Diffusion variants.
- We train a multimodal transformer model, Rich Automatic Human Feedback (RAHF), to predict different types of human feedback, such as implausibility scores, heatmaps of artifact locations, and missing or misaligned text/keywords.
- We show that the predicted rich human feedback can be leveraged to improve image generation and that the improvements generalize to models (such as Muse) beyond those used for data collection (Stable Diffusion variants).
To the best of our knowledge, this is the first rich feedback dataset and model for state-of-the-art text-to-image generation.
Rich human feedback collection
Images are selected (based on attributes automatically created by PaLI) from the Pick-a-Pic training data set, to have a good variety of images across categories and types, as shown below, resulting in 17K images. We randomly split the 17K samples into a training set with 16K samples and a validation set with 1K samples. Additionally, we collect rich human feedback on the Pick-a-Pic test set as our test set. As a result, the final RichHF-18K dataset consists of 16K training, 1K validation, and 1K test samples.
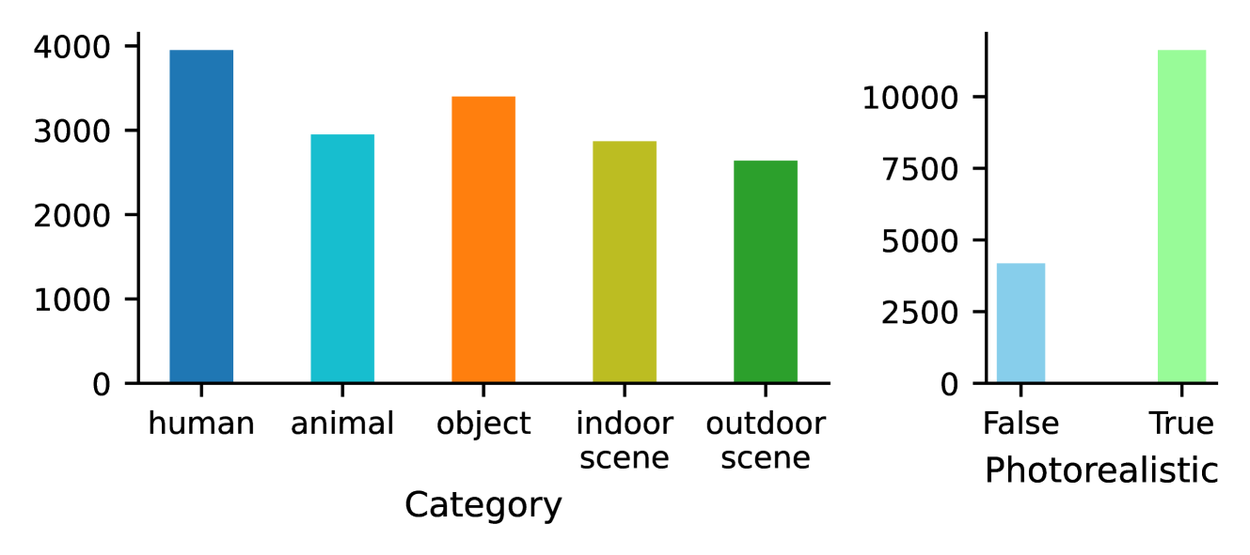
Histograms of the PaLI attributes of the images in the training set.
For each generated image, the annotators are first asked to examine the image and read the text prompt. Then, they mark points on the image to indicate the location of any implausibility, artifact, or misalignment with the text prompt. Lastly, annotators label the misaligned keywords and the four types of scores for plausibility, image-text alignment, aesthetic, and overall quality, respectively, on a 5-point Likert scale.

An illustration of our annotation user interface.
Rich human feedback prediction
The architecture of our RAHF model is shown below. We adopt a vision-language model based on ViT and T5X models, inspired by previous large vision-language model efforts (PaLI and Spotlight). The text information is propagated to image tokens via self-attention for text misalignment score and heatmap prediction (the problematic regions of artifacts or misalignment), while the vision information is propagated to text tokens for better vision-aware text encoding to decode the text misalignment sequence. Our best model uses a single head for each prediction type, shown as the three green boxes below: heatmap, score, and misalignment sequence. To inform the model of the fine-grained heatmap or score type, we augment the prompt with the output type. More specifically, we prepend a task string (e.g., “implausibility heatmap”) to the prompt for each particular task of one example and use the corresponding label as the training target.
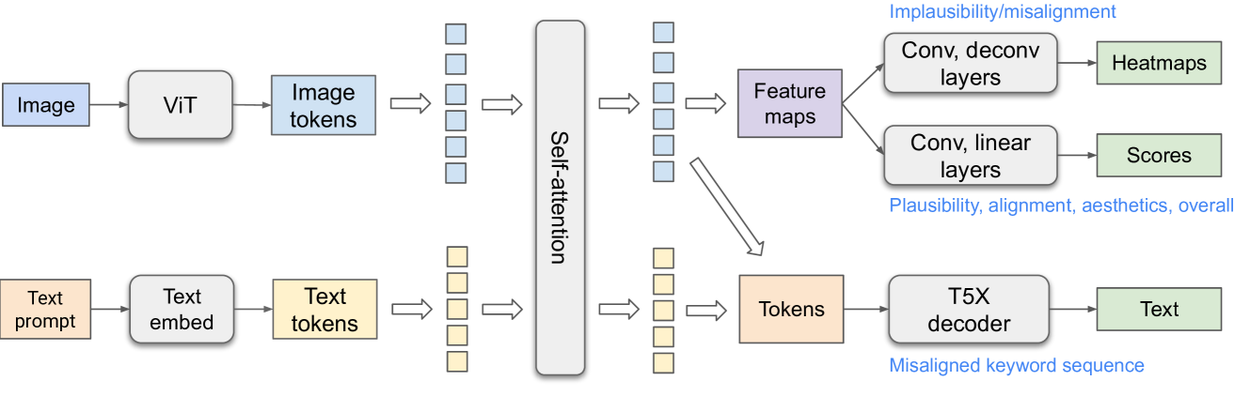
Architecture of our rich feedback model.
Examples of our model prediction on implausibility heatmaps are shown as below.

Examples of implausibility heatmaps. In Groundtruth heatmap, color represents how many annotators mark the region as implausible. Red/yellow/blue means 3/2/1 annotators mark the regions respectively. In prediction, color represents the signal strength (probability). The hotter one region is, the more probable the model predicts it as implausible.
A case study on human hands (which are among the most common sources of error for generative models) and figures are shown below, which demonstrates that the model can successfully locate the artifacts for various cases. This indicates that the model learns the concept of good hands and fingers.

Case study of implausibility heatmaps for human hands and fingers.
As a baseline comparison, we fine-tuned a ResNet-50 with our RichHF-18K data. Quantitative analysis below shows that our model performs better than the baseline on most metrics for implausibility heatmap prediction.
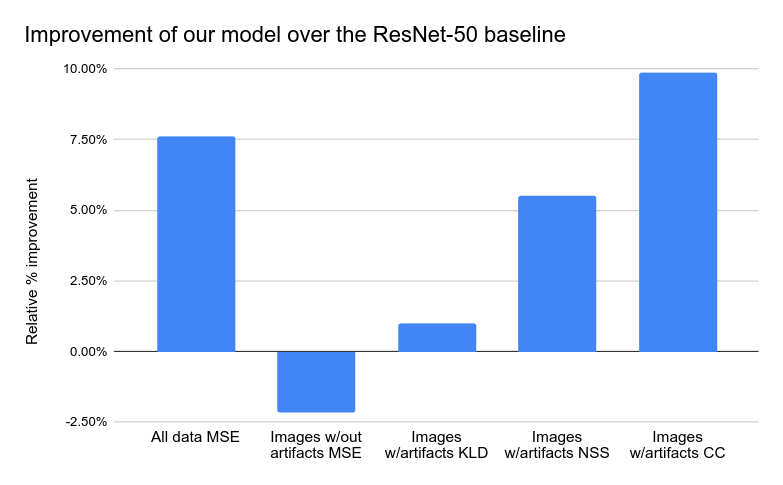
Implausibility heatmap prediction results on the test set. The figure shows improvement of most metrics by our model compared with the baseline model. MSE: mean square error. KLD: KL divergence. NSS: Normalized Scanpath Saliency. CC: correlation coefficient.
Below is an example of our model prediction on misalignment heatmap. The top of the mushroom is labeled as a misalignment region as there is no snake generated. We can see our model can predict the misalignment region accurately in this example.

Example of misalignment heatmap. Prompt: “A snake on a mushroom.”
Below we show a comparison of our model performance on score predictions vs. baseline methods. Examples for score prediction can be found in our paper.
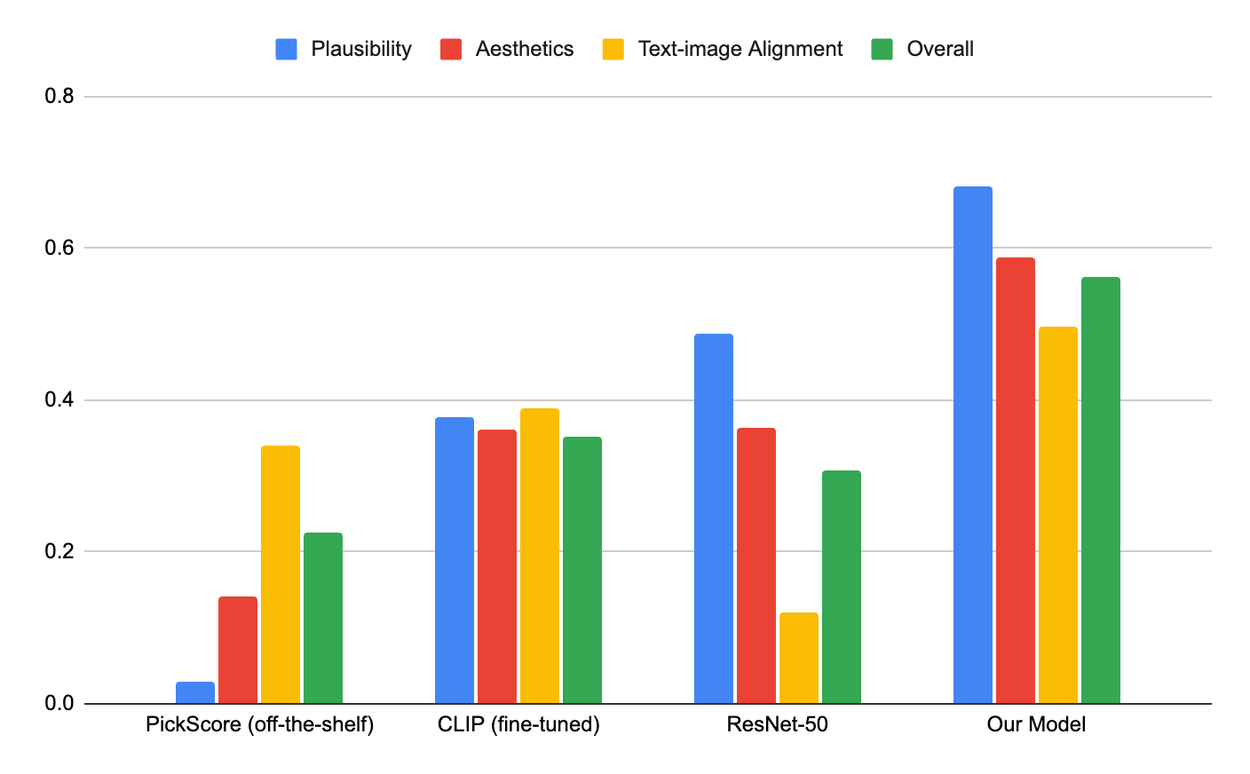
Spearman correlation of score prediction results on the test set.
The following figure shows an example of a generated image and the predicted human feedback, demonstrating that RAHF can serve as an evaluation tool for T2I generation, with automatic interpretation.

Example of one generated image and the predicted rich human feedback by RAHF.
Learning from rich human feedback
The predicted rich human feedback (e.g., scores and heatmaps) can be used to improve image generation.
One way is by fine-tuning generative models with predicted scores. To do this, we start by creating a high-quality dataset by filtering the Muse model results with RAHF-predicted scores. The Muse model is then fine-tuned with this dataset, via LoRA fine-tuning method. Side-by-side evaluation showed that Muse fine-tuned with RAHF plausibility scores possesses significantly fewer artifacts than the original Muse, as shown by the examples and results below.

Muse generated images before and after fine-tuning with examples filtered by plausibility scores.
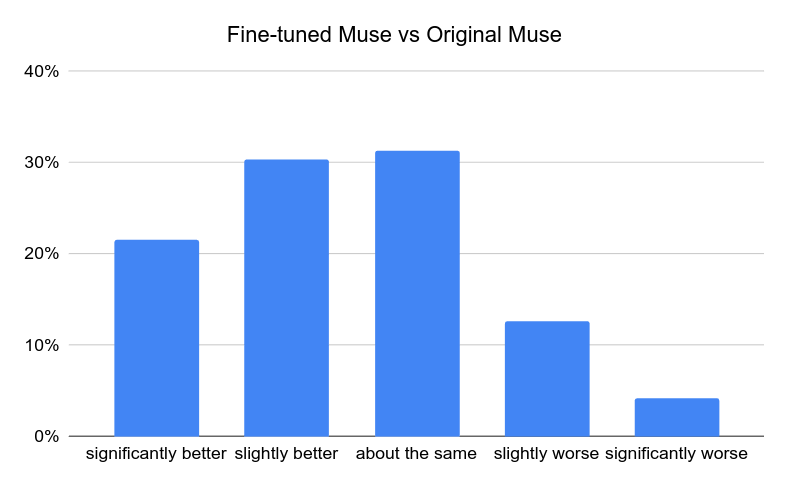
Human evaluation results. Percentage of examples where fine-tuned Muse is significantly better, slightly better, about the same, slightly worse, significantly worse than original Muse.
Moreover, below we show an example of using the RAHF aesthetic score as Classifier Guidance to the Latent Diffusion model, demonstrating that each of the fine-grained scores can improve different aspects of the generative model/results.

An example of using the RAHF aesthetic score as Classifier Guidance to the Latent Diffusion model. Prompt: “a macro lens closeup of a paperclip”.

An example of using the RAHF overall score as Classifier Guidance to the Latent Diffusion model. Prompt: “kitten sushi stained glass window sunset fog.”
We also demonstrate that our model’s predicted heatmaps and scores can be used to perform region inpainting to improve the quality of generated images. For each image, we first predict implausibility heatmaps, then create a mask by processing the heatmap (using thresholding and dilating). Muse inpainting is applied within the masked region to generate new images that match the text prompt. Multiple images are generated, and the final image is chosen by the highest predicted plausibility score by our RAHF. Below we show more plausible images with fewer artifacts generated after inpainting.

Region inpainting with Muse generative model. From left to right, the three figures are: original images with artifacts from Muse, predicted implausibility heatmaps from our model, and new images from Muse region inpainting with the mask, respectively.
Conclusion
In this work, we announce and release RichHF-18K, the first rich human feedback dataset for text to image generation. We designed and trained a multimodal Transformer to predict rich human feedback, and demonstrated some instances to improve image generation with our rich human feedback. Future work includes improvement to the dataset with better annotation quality (on the misalignment heatmap especially), and to collect rich human feedback on a wider range of generative models (e.g., Imagen and DALL-E), and investigate more methods to use the rich human feedback. We hope RichHF-18K and our initial models inspire further investigation in the research direction of learning from human feedback for image generation.
Acknowledgement
We would like to thank all co-authors for their contributions to this paper: Youwei Liang, Peizhao Li, Arseniy Klimovskiy, Nicholas Carolan, Jiao Sun, Jordi Pont-Tuset, Sarah Young, Feng Yang, Junjie Ke, Krishnamurthy Dj Dvijotham, Katie Collins, Yiwen Luo, Yang Li, Kai J Kohlhoff, Deepak Ramachandran, Vidhya Navalpakkam. We would also like to thank Tim Fujita and Jane Park for their help on this blogpost. Junfeng He and Gang Li co-lead this project and have equal leading/technical contribution.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence

An illustration of our annotation user interface.

Examples of implausibility heatmaps. In Groundtruth heatmap, color represents how many annotators mark the region as implausible. Red/yellow/blue means 3/2/1 annotators mark the regions respectively. In prediction, color represents the signal strength (probability). The hotter one region is, the more probable the model predicts it as implausible.

Spearman correlation of score prediction results on the test set.

An example of using the RAHF overall score as Classifier Guidance to the Latent Diffusion model. Prompt: “kitten sushi stained glass window sunset fog.”

Region inpainting with Muse generative model. From left to right, the three figures are: original images with artifacts from Muse, predicted implausibility heatmaps from our model, and new images from Muse region inpainting with the mask, respectively.


Example of misalignment heatmap. Prompt: “A snake on a mushroom.”

An example of using the RAHF aesthetic score as Classifier Guidance to the Latent Diffusion model. Prompt: “a macro lens closeup of a paperclip”.

Architecture of our rich feedback model.


Case study of implausibility heatmaps for human hands and fingers.

Example of one generated image and the predicted rich human feedback by RAHF.

Muse generated images before and after fine-tuning with examples filtered by plausibility scores.