Revisiting Mask Transformer from a Clustering Perspective
July 12, 2022
Posted by Qihang Yu, Student Researcher, and Liang-Chieh Chen, Research Scientist, Google Research
Quick links
Panoptic segmentation is a computer vision problem that serves as a core task for many real-world applications. Due to its complexity, previous work often divides panoptic segmentation into semantic segmentation (assigning semantic labels, such as “person” and “sky”, to every pixel in an image) and instance segmentation (identifying and segmenting only countable objects, such as “pedestrians” and “cars”, in an image), and further divides it into several sub-tasks. Each sub-task is processed individually, and extra modules are applied to merge the results from each sub-task stage. This process is not only complex, but it also introduces many hand-designed priors when processing sub-tasks and when combining the results from different sub-task stages.
Recently, inspired by Transformer and DETR, an end-to-end solution for panoptic segmentation with mask transformers (an extension of the Transformer architecture that is used to generate segmentation masks) was proposed in MaX-DeepLab. This solution adopts a pixel path (consisting of either convolutional neural networks or vision transformers) to extract pixel features, a memory path (consisting of transformer decoder modules) to extract memory features, and a dual-path transformer for interaction between pixel features and memory features. However, the dual-path transformer, which utilizes cross-attention, was originally designed for language tasks, where the input sequence consists of dozens or hundreds of words. Nonetheless, when it comes to vision tasks, specifically segmentation problems, the input sequence consists of tens of thousands of pixels, which not only indicates a much larger magnitude of input scale, but also represents a lower-level embedding compared to language words.
In “CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation”, presented at CVPR 2022, and “kMaX-DeepLab: k-means Mask Transformer”, to be presented at ECCV 2022, we propose to reinterpret and redesign cross-attention from a clustering perspective (i.e., grouping pixels with the same semantic labels together), which better adapts to vision tasks. CMT-DeepLab is built upon the previous state-of-the-art method, MaX-DeepLab, and employs a pixel clustering approach to perform cross-attention, leading to a more dense and plausible attention map. kMaX-DeepLab further redesigns cross-attention to be more like a k-means clustering algorithm, with a simple change on the activation function. We demonstrate that CMT-DeepLab achieves significant performance improvements, while kMaX-DeepLab not only simplifies the modification but also further pushes the state-of-the-art by a large margin, without test-time augmentation. We are also excited to announce the open-source release of kMaX-DeepLab, our best performing segmentation model, in the DeepLab2 library.
Overview
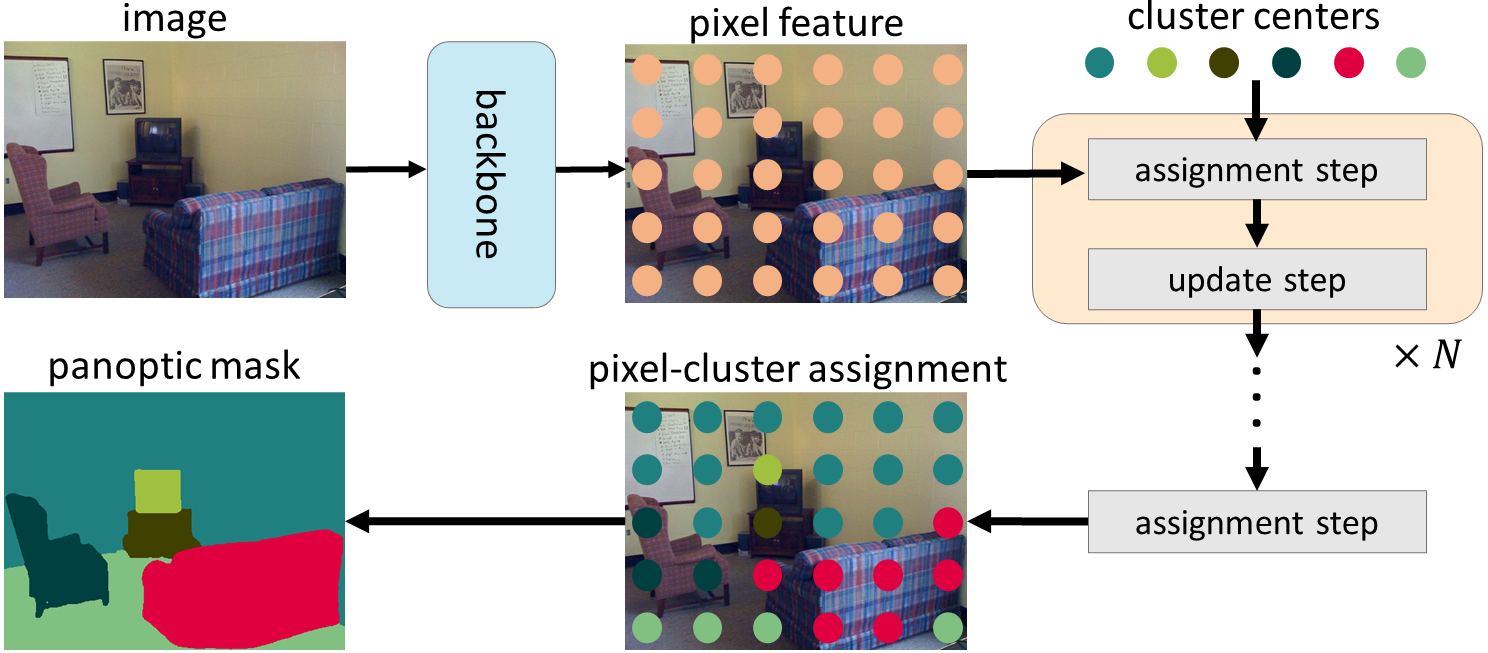
Instead of directly applying cross-attention to vision tasks without modifications, we propose to reinterpret it from a clustering perspective. Specifically, we note that the mask Transformer object query can be considered cluster centers (which aim to group pixels with the same semantic labels), and the process of cross-attention is similar to the k-means clustering algorithm, which adopts an iterative process of (1) assigning pixels to cluster centers, where multiple pixels can be assigned to a single cluster center, and some cluster centers may have no assigned pixels, and (2) updating the cluster centers by averaging pixels assigned to the same cluster center, the cluster centers will not be updated if no pixel is assigned to them).
 |
| In CMT-DeepLab and kMaX-DeepLab, we reformulate the cross-attention from the clustering perspective, which consists of iterative cluster-assignment and cluster-update steps. |
Given the popularity of the k-means clustering algorithm, in CMT-DeepLab we redesign cross-attention so that the spatial-wise softmax operation (i.e., the softmax operation that is applied along the image spatial resolution) that in effect assigns cluster centers to pixels is instead applied along the cluster centers. In kMaX-DeepLab, we further simplify the spatial-wise softmax to cluster-wise argmax (i.e., applying the argmax operation along the cluster centers). We note that the argmax operation is the same as the hard assignment (i.e., a pixel is assigned to only one cluster) used in the k-means clustering algorithm.
Reformulating the cross-attention of the mask transformer from the clustering perspective significantly improves the segmentation performance and simplifies the complex mask transformer pipeline to be more interpretable. First, pixel features are extracted from the input image with an encoder-decoder structure. Then, a set of cluster centers are used to group pixels, which are further updated based on the clustering assignments. Finally, the clustering assignment and update steps are iteratively performed, with the last assignment directly serving as segmentation predictions.
 |
| To convert a typical mask Transformer decoder (consisting of cross-attention, multi-head self-attention, and a feed-forward network) into our proposed k-means cross-attention, we simply replace the spatial-wise softmax with cluster-wise argmax. |
The meta architecture of our proposed kMaX-DeepLab consists of three components: pixel encoder, enhanced pixel decoder, and kMaX decoder. The pixel encoder is any network backbone, used to extract image features. The enhanced pixel decoder includes transformer encoders to enhance the pixel features, and upsampling layers to generate higher resolution features. The series of kMaX decoders transform cluster centers into (1) mask embedding vectors, which multiply with the pixel features to generate the predicted masks, and (2) class predictions for each mask.
 |
| The meta architecture of kMaX-DeepLab. |
Results
We evaluate the CMT-DeepLab and kMaX-DeepLab using the panoptic quality (PQ) metric on two of the most challenging panoptic segmentation datasets, COCO and Cityscapes, against MaX-DeepLab and other state-of-the-art methods. CMT-DeepLab achieves significant performance improvement, while kMaX-DeepLab not only simplifies the modification but also further pushes the state-of-the-art by a large margin, with 58.0% PQ on COCO val set, and 68.4% PQ, 44.0% mask Average Precision (mask AP), 83.5% mean Intersection-over-Union (mIoU) on Cityscapes val set, without test-time augmentation or using an external dataset.
| Method | PQ |
| MaX-DeepLab | 51.1% (-6.9%) |
| MaskFormer | 52.7% (-5.3%) |
| K-Net | 54.6% (-3.4%) |
| CMT-DeepLab | 55.3% (-2.7%) |
| kMaX-DeepLab | 58.0% |
| Comparison on COCO val set. | ||||
| Method | PQ | APmask | mIoU |
| Panoptic-DeepLab | 63.0% (-5.4%) | 35.3% (-8.7%) | 80.5% (-3.0%) |
| Axial-DeepLab | 64.4% (-4.0%) | 36.7% (-7.3%) | 80.6% (-2.9%) |
| SWideRNet | 66.4% (-2.0%) | 40.1% (-3.9%) | 82.2% (-1.3%) |
| kMaX-DeepLab | 68.4% | 44.0% | 83.5% |
| Comparison on Cityscapes val set. | ||||
Designed from a clustering perspective, kMaX-DeepLab not only has a higher performance but also a more plausible visualization of the attention map to understand its working mechanism. In the example below, kMaX-DeepLab iteratively performs clustering assignments and updates, which gradually improves mask quality.
 |
| kMaX-DeepLab’s attention map can be directly visualized as a panoptic segmentation, which gives better plausibility for the model working mechanism (image credit: coco_url, and license). |
Conclusions
We have demonstrated a way to better design mask transformers for vision tasks. With simple modifications, CMT-DeepLab and kMaX-DeepLab reformulate cross-attention to be more like a clustering algorithm. As a result, the proposed models achieve state-of-the-art performance on the challenging COCO and Cityscapes datasets. We hope that the open-source release of kMaX-DeepLab in the DeepLab2 library will facilitate future research on designing vision-specific transformer architectures.
Acknowledgements
We are thankful to the valuable discussion and support from Huiyu Wang, Dahun Kim, Siyuan Qiao, Maxwell Collins, Yukun Zhu, Florian Schroff, Hartwig Adam, and Alan Yuille.
Quick links
Other posts of interest
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

March 6, 2026
WAXAL: A large-scale open resource for African language speech technology- Natural Language Processing ·
- Open Source Models & Datasets



