Relationships are complicated! An analysis of relationships between datasets on the Web
November 7, 2024
Kate Lin, Research Engineer, and Tarfah Alrashed, Research Scientist, Google Research
We develop a series of methods to automatically identify relationships between datasets on the Web and compare their performance on a large corpus of datasets generated from Web pages with schema.org markup.
Quick links
The Web has millions of datasets, and that number continues to grow rapidly. Many of these datasets are intricately connected through complex relationships. Google Dataset Search helps users navigate this landscape by indexing metadata from diverse sources (e.g., government, academic, and institutional repositories) and allowing users to search for datasets based on topics, formats, publication dates, and more. Understanding the relationships between datasets, particularly from the perspective of data practitioners, is critical for research and decision-making.
Consider a few examples. When a scientist works on reproducing experimental results from a publication, she must identify which specific dataset snapshot a publication has used. When evaluating the trustworthiness of a dataset available on multiple platforms, users may want to choose the repository that they trust the most. If a researcher wants to compare slices of a large dataset, she must ascertain that these slices come from the same snapshot of the larger dataset. All these tasks require understanding the semantics of relationships between datasets.
In “Relationships are Complicated! An Analysis of Relationships Between Datasets on the Web”, a paper published at the International Semantic Web Conference, we study dataset relationships from the perspective of users who discover, use, and share datasets on the Web. We present a comprehensive taxonomy of relationships between datasets on the Web and map these relationships to user tasks performed during dataset discovery. We then develop a series of methods to identify these relationships automatically and compare their performance on a large corpus of datasets from the Web. We demonstrate that machine learning-based methods that use dataset metadata achieve multi-class relationship classification accuracy of 90%. Finally, we highlight gaps in available semantic markup for datasets and discuss how incorporating comprehensive semantics can facilitate richer and more accurate identification of dataset relationships.
Defining the dataset relationships
First, we grounded our taxonomy of dataset relationship by defining four main tasks that users may undertake during data discovery and sharing:
- Finding datasets: The proliferation of data on the Web makes finding datasets difficult. Users face challenges in sorting through vast amounts of data and navigating diverse search criteria, especially when their intent varies.
- Evaluating dataset trustworthiness: Evaluating whether to use a dataset involves an assessment of dataset trustworthiness. Unlike research publications, datasets published on the Web rarely undergo peer review. As a result, users must rely on dataset attributes and metadata as proxies for dataset trustworthiness.
- Citing and referencing datasets: Well-described datasets drive new research. Citing datasets like papers encourages better data collection and curation. Proper citation requires persistent identifiers, metadata, and accurate provenance descriptions, including version number, source, and whether it is a subset of another dataset.
- Curating datasets: Dataset curation involves collecting, organizing, and maintaining datasets from diverse sources to ensure availability for users. The goal is to create high-quality datasets beneficial for researchers, developers, and users. Curators must understand a dataset’s relationships, including its versions, replicas, and usage in research or projects.
We then broadly grouped dataset relationships on the Web into provenance-based and non-provenance-based categories. Provenance-based relationships occur between datasets that share a common origin, such as when datasets are derived or modified versions of the same source. Non-provenance-based relationships involve connections between datasets based on content, topic, or task, rather than their origin.
Provenance-based relationships include replicas, which are identical datasets hosted on different platforms, and versions, where a dataset evolves over time through updates. Subsets represent specific portions of the original dataset, such as data filtered by geographic criteria. Derivations aggregate multiple datasets to provide a broader summary, while variants cover the same subject but span different time periods or geographic areas. Non-provenance-based relationships focus on content or purpose of the dataset, including topically similar datasets on related subjects, task-similar datasets designed for the same function, and integratable datasets that can be combined using shared attributes like time or location.
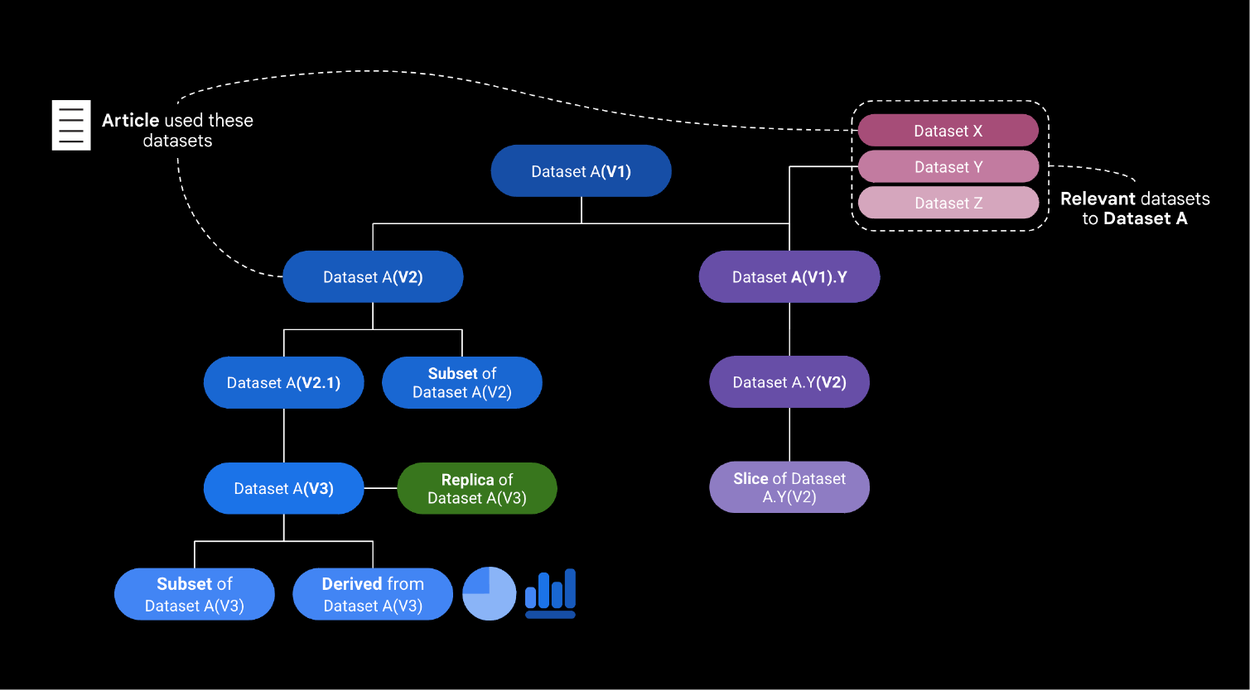
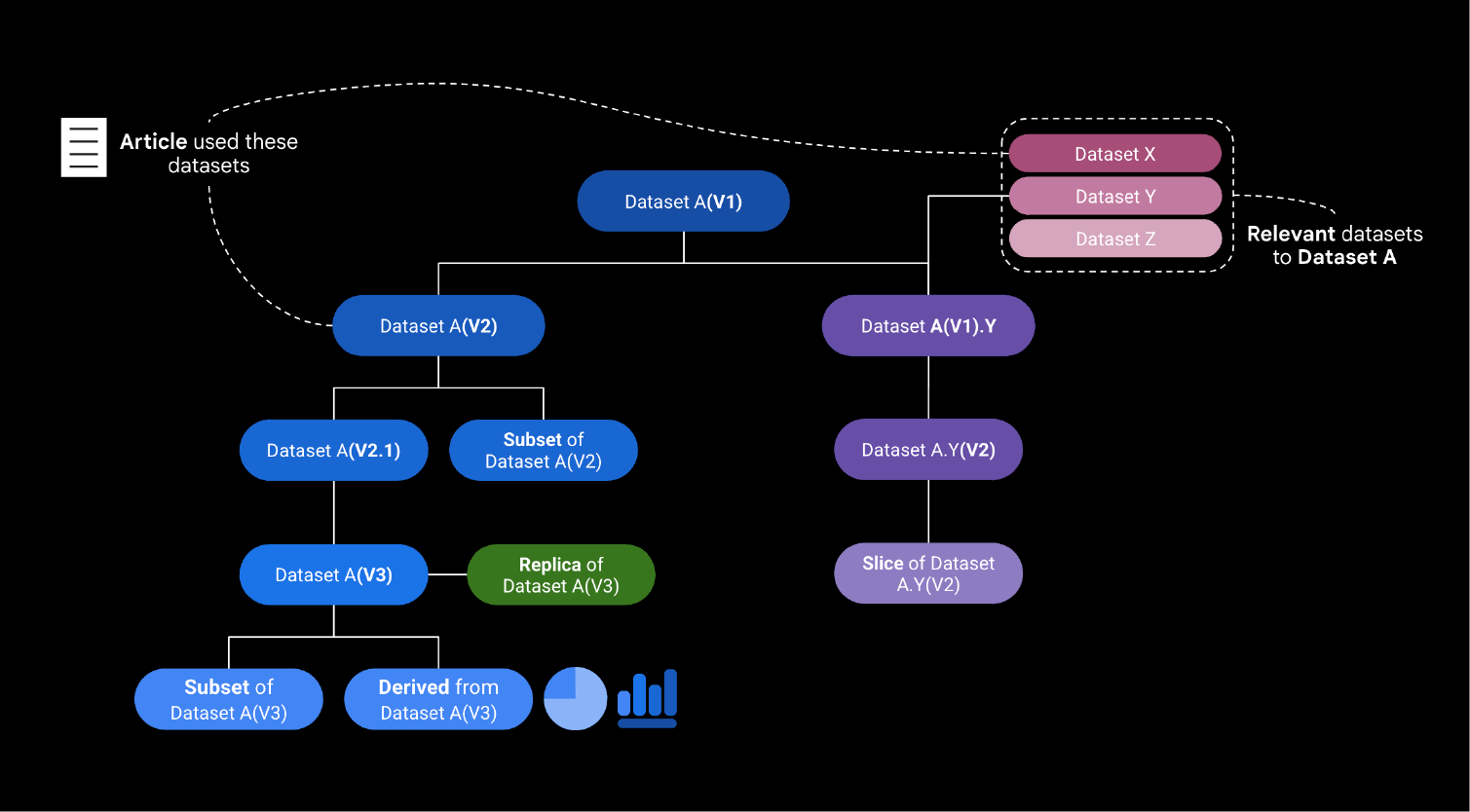
This diagram illustrates the evolution and relationships of Dataset A through its versions, subsets, replicas, and derived datasets. Starting with Dataset A (V1), it highlights subsequent versions (V2, V3) and subsets (V2.1, Y), as well as connections to related external datasets (X, Y, Z), which may be integrated or modified. It also shows how datasets are linked to external artifacts, such as scientific articles.
Developing the analysis methods
Google Dataset Search relies on schema.org, a semantic markup for dataset metadata provided by authors or publishers of datasets on the Web. Earlier research has shown that schema.org metadata is often mispopulated. Furthermore, because schema.org was designed to be flexible across various forms of structured data on the Web, markup vocabulary specific for inter-dataset relationships is not fully fleshed out. Thus, in addition to extracting relationships from schema.org markup, we propose a series of automatic approaches to infer dataset relationships. We focus specifically on evaluating the metadata (not data); thus, we concentrate on provenance-based relationships.
We evaluate and compare four methods: first, we extract relationships directly using schema.org. Second, we develop a set of heuristics tailored to each relationship type. Heuristics-based approaches are usually efficient to implement. Finally, we propose two machine-learning–based approaches: a classical ML approach consisting of a gradient boosted decision trees (GBDT) classifier and a generative AI approach using an LLM-based classifier (we use a T5 model). Each of these models represents a larger class of methods that can be used to tackle this problem setting.
Results
We compare the performance of the four methods on manually annotated ground truth data, then apply the best-performing method to a large corpus of Web datasets in order to understand the prevalence of different provenance relationships between those datasets.
We generated a corpus of dataset metadata by crawling the Web to find pages with schema.org metadata indicating that the page contains a dataset. We then limited the corpus to datasets that have persistent de-referencible identifiers (i.e., a unique code that permanently identifies a digital object, allowing access to it even if the original location or website changes). This corpus includes 2.7 million dataset-metadata entries.
To generate ground truth for training and evaluation, we manually labeled 2,178 dataset pairs. The labelers had access to all metadata fields for these datasets, such as name, description, provider, temporal and spatial coverage, and so on.
We compared the performance of the four different methods — schema.org, heuristics-based, gradient boosted decision trees (GBDT), and T5 — across various dataset relationship categories (detailed breakdown in the paper). The ML methods (GBDT and T5) outperform the heuristics-based approach in identifying dataset relationships. GBDT consistently achieves the highest F1 scores across various categories, with T5 performing similarly well.
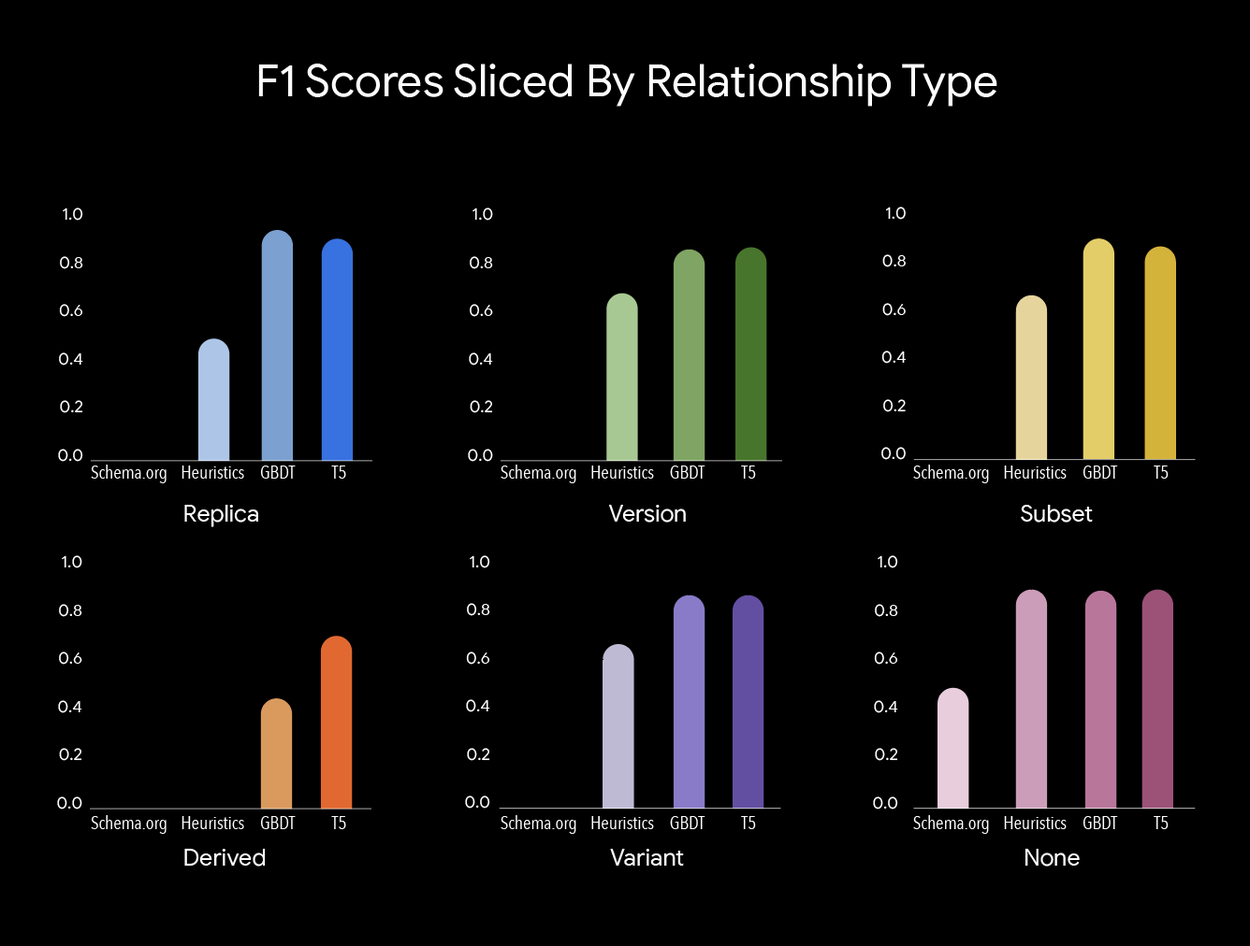
F1 scores for each method sliced by relationship type. Schema.org annotations only exist for the replica and derived relationships. GBDT and T5 performed similarly well with the exception of the derived relationship, in which T5 significantly outperformed other methods. See the paper for a more detailed breakdown of precision and recall scores.
Our experiments find that schema.org metadata alone is insufficient for identifying relationships between datasets, even for the two types for which schema.org annotations exist (replica and derived): indeed, no pairs of datasets in our random sample had an explicit relationship defined between them.
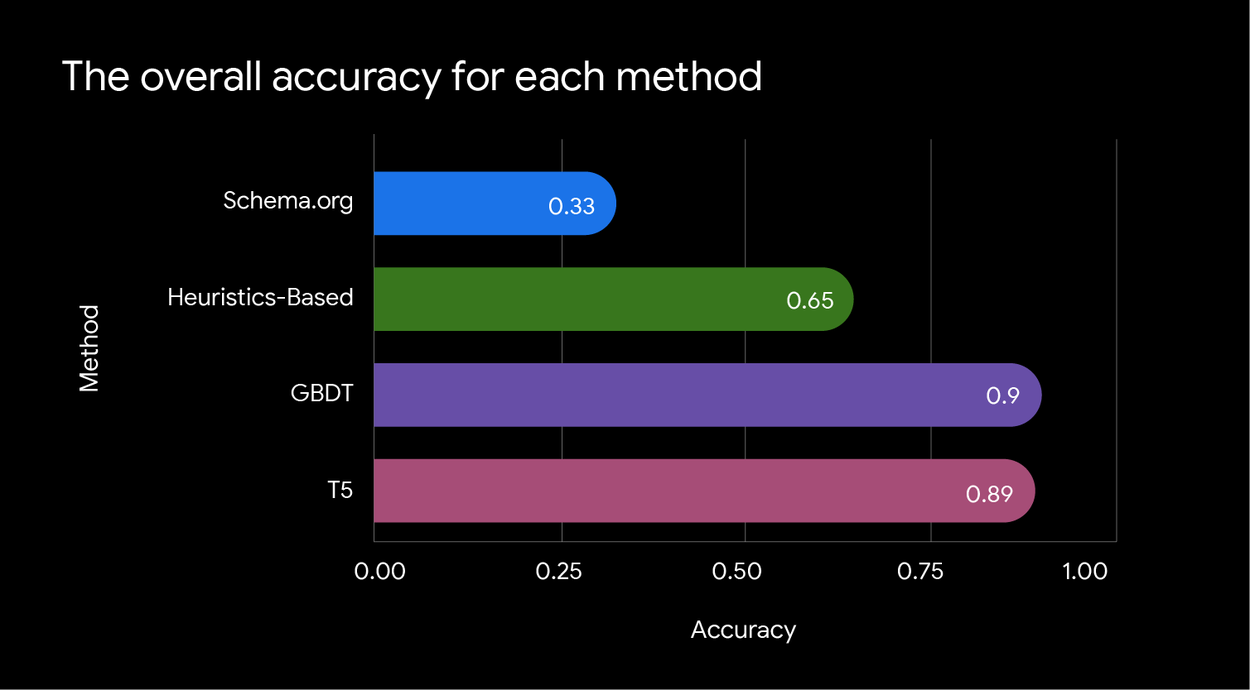
A comparison of overall accuracy across methods — schema.org, heuristics-based, gradient boosted decision trees (GBDT), and T5. Schema.org achieves the lowest accuracy at 0.33, while heuristics-based reaches 0.65. GBDT performs the best with an accuracy of 0.90, closely followed by T5 at 0.89.
Conclusion
Using even simple analysis methods, we can see that datasets on the Web are connected in many different ways. While this analysis can help in identifying some of the relationships, research communities must develop best practices that encourage dataset authors to specify metadata that captures the provenance of data.
Our analysis emphasizes the need for more robust schema.org annotations, as well as improvements in metadata standards to better capture essential relationships like subsets and integrated datasets. These relationships serve distinct user needs: subsets help manage smaller portions of data, while joinable datasets allow for data expansion and new insights. To enhance dataset discovery and usability, we recommend refining semantic markup practices and adopting better data-sharing standards. This will also help overcome current challenges in detecting relationships, particularly when dataset names evolve. Moving forward, we aim to explore additional non-provenance relationships to better assist users in finding the right data for their tasks.
Acknowledgements
We thank our co-author Natasha Noy for her invaluable expertise and guidance throughout this project. We would also like to thank Kerry Li and Ray Zhou for helping annotate ground truth data. This research project would not have been possible without the groundwork laid by the entire Dataset Search team.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence

