Re-Invoke: Tool invocation rewriting for zero-shot tool retrieval
November 21, 2024
Yanfei Chen, Software Engineer, and Chen-Yu Lee, Research Scientist, Cloud AI Team
We propose Re-Invoke, an unsupervised tool retrieval method that effectively and efficiently retrieves the most relevant tools from a large toolset given the user query with multiple underlying intents.
Quick links
Augmenting large language models (LLMs) with external tools, rather than relying solely on their internal knowledge, could unlock their potential to solve more challenging problems. Common approaches for such “tool learning” fall into two categories: (1) supervised methods to generate tool calling functions, or (2) in-context learning, which uses tool documents that describe the intended tool usage along with few-shot demonstrations. Tool documents provide instructions on tool’s functionalities and how to invoke it, allowing LLMs to master the individual tools.
However, these methods face practical challenges when scaling to a large number of tools. First, they suffer from input token limits. It is impossible to feed the entire list of tools within a single prompt, and, even if it were possible, LLMs still often struggle to effectively process relevant information from lengthy input contexts. Second, the pool of tools is evolving. LLMs are often paired with a retriever trained on labeled query–tool pairs to recommend a shortlist of tools. However, the ideal LLM toolkit should be vast and dynamic, with tools undergoing frequent updates. Providing and maintaining labels to train a retriever for such an extensive and evolving toolset would be impractical. Finally, one must contend with ambiguous user intents. User context in the queries could obfuscate the underlying intents, and failure to identify them could lead to calling the incorrect tools.
In “Re-Invoke: Tool Invocation Rewriting for Zero-Shot Tool Retrieval”, presented at EMNLP 2024, we introduce a novel unsupervised retrieval method specifically designed for tool learning to address these unique challenges. Re-Invoke leverages LLMs for both tool document enrichment and user intent extraction to enhance tool retrieval performance across various use cases. We demonstrate that the proposed Re-Invoke method consistently and significantly improves upon the baselines covering both single- and multi-tool retrieval tasks on tool use benchmark datasets.
Re-Invoke
The tool retrieval task is formulated as retrieving the most relevant tool(s) that a downstream agent can execute to fulfill user queries, given a list of tool documents describing the intended tool usage. Re-Invoke is a fully unsupervised tool retrieval method designed for such tasks. It consists of two core components:
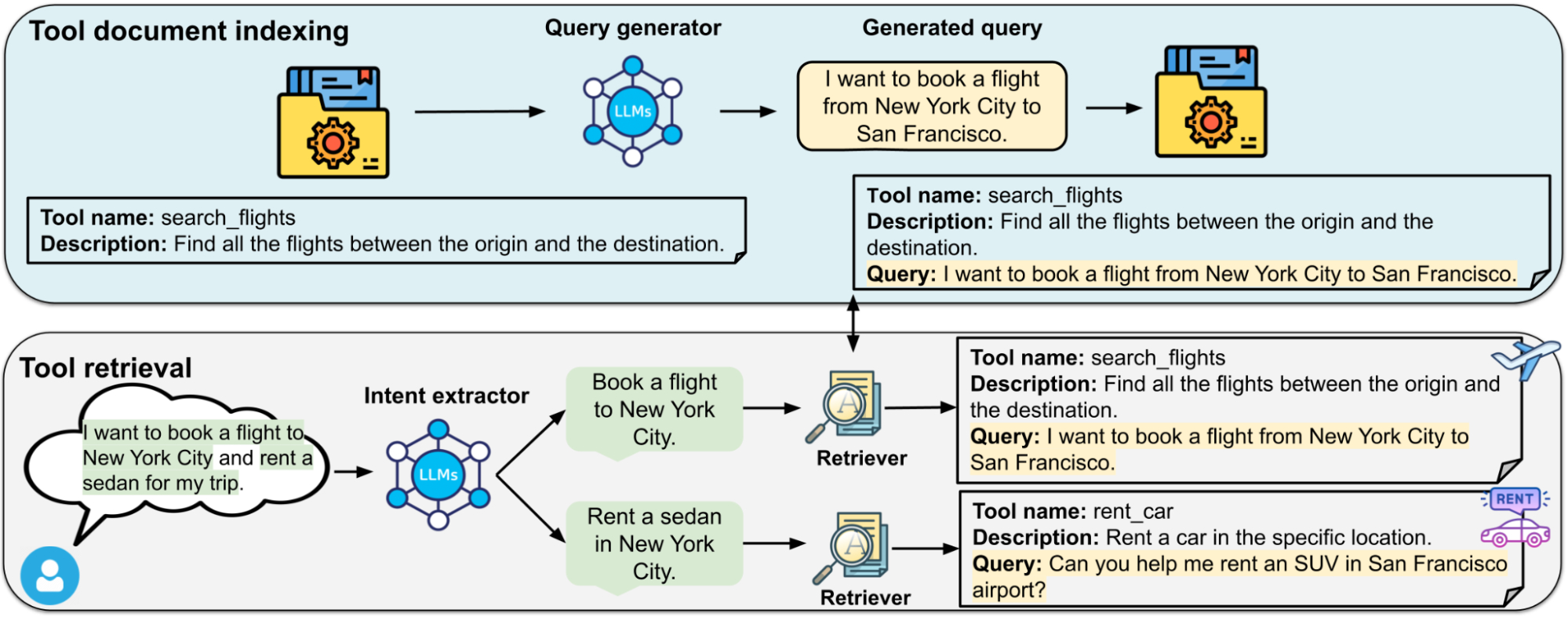
- Query generator: For each tool document, LLMs generate diverse synthetic queries answerable by the provided tool. These queries enrich the tool document and are then encoded into the embedding space when the tool documents are ingested offline.
- Query intent extractor: During online inference, LLMs extract the core tool-related intent(s) from user queries, filtering out irrelevant background context. Each user intent is then encoded into the same embedding space as the tool documents for similarity matching.
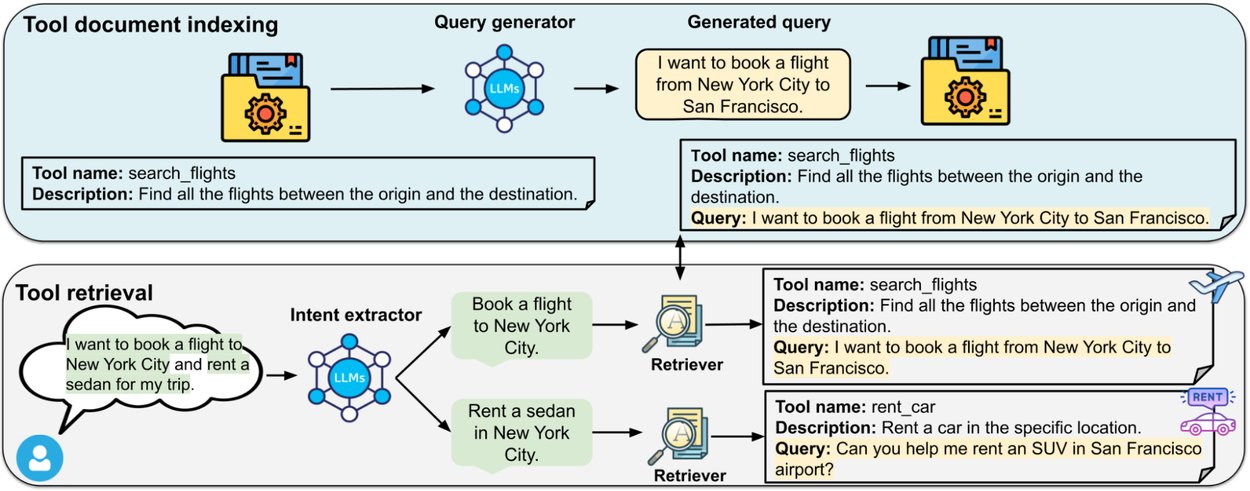
An overview of Re-Invoke on tool retrieval tasks. Top: A query generator produces diverse synthetic queries from the tool documentation. Each synthetic query is concatenated with the tool documentation to create multiple copies of the expanded tool documentation. Bottom: An intent extractor synthesizes multiple underlying intents from the user queries to retrieve the relevant tools.
As different relevant tools could be retrieved from each intent extracted from the user queries, we introduce a novel multi-view similarity ranking method to consider all tool-related intents expressed in the user query. We rank the tools individually by the relevance score within each intent and retrieve the top tool from each intent (see the example below). To achieve this, we design an ordering function to consider both the rank of the retrieved tool within each intent and the similarity score value between the tool and the intent in the embedding space. The proposed formulation allows us to capture the relevance of each intent to different aspects of the tool document, as represented by the synthetic queries.
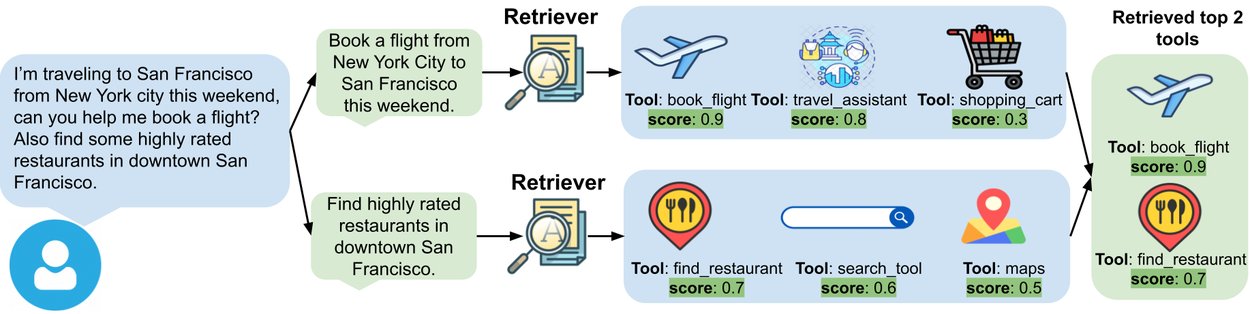
An illustration of the multi-view similarity ranking algorithm during retrieval. Multiple intents can be extracted from the user query. We first compute the similarity scores between the expanded tool documents and each intent in the embedding space and then we rank and retrieve the top tools from each intent.
Experiment
We select the ToolBench and ToolE datasets to evaluate Re-Invoke’s tool retrieval performance. Both datasets provide query and ground-truth tool document pairs that reflect real-world scenarios. The ToolBench dataset consists of more than 10,000 tools pulled from the RapidAPI hub, suitable for large-scale tool retrieval evaluations. We use nDCG@k metric to evaluate the tool retrieval performance considering the top k retrieved tools only. We use the same ToolBench dataset to evaluate the end-to-end performance when integrating the LLM agent with the proposed Re-Invoke retrieval method.
For Re-Invoke, we use Google Vertex AI’s text-bison@001 model in the query generator with a 0.7 sampling temperature (to introduce variations in the model response) to generate 10 diverse synthetic queries per tool document. The same text-bison@001 model (with 0.0 sampling temperature) is used in the intent extractor to synthesize the intents from the user queries. We then extract dense embedding vectors from both augmented tool documents and extracted intents using Google Vertex AI’s textembedding-gecko@003 model. For the sparse retrieval method, we use BM25 embedding vectors. We average the embedding values from multiple copies of the expanded tool document as a representation of the tool document. We replicate our experiment using other LLMs including OpenAI’s gpt-3.5 turbo model and Mistral AI’s Mistral-7B-Instruct-v0.3 model with the same prompt and model parameters. Note this research was primarily done in November 2023, and therefore we used text-bison@001 models in our experiment.
Re-Invoke outperforms the sparse and dense retrieval baselines on tool retrieval tasks
For the unsupervised sparse retrieval method, we use BM25 and HyDE with Google Vertex AI’s text-bison@001 model for the backbone LLM as the baseline retrieval methods. In the unsupervised dense retrieval method, we apply Google Vertex AI’s textembedding-gecko@003 model and HyDE with Google Vertex AI’s text-bison@001 model as the baseline retrieval methods. nDCG@5 quantifies the retrieval performance against the ground-truth labels.
As shown in the chart below, Re-Invoke consistently outperforms the baseline methods across sparse and dense retrieval methods on all the benchmark datasets. The improvement is consistent across different backbone LLMs. The evaluation results demonstrate the effectiveness of both tool document enhancement with synthetic queries and user query understanding for identifying relevant tools.
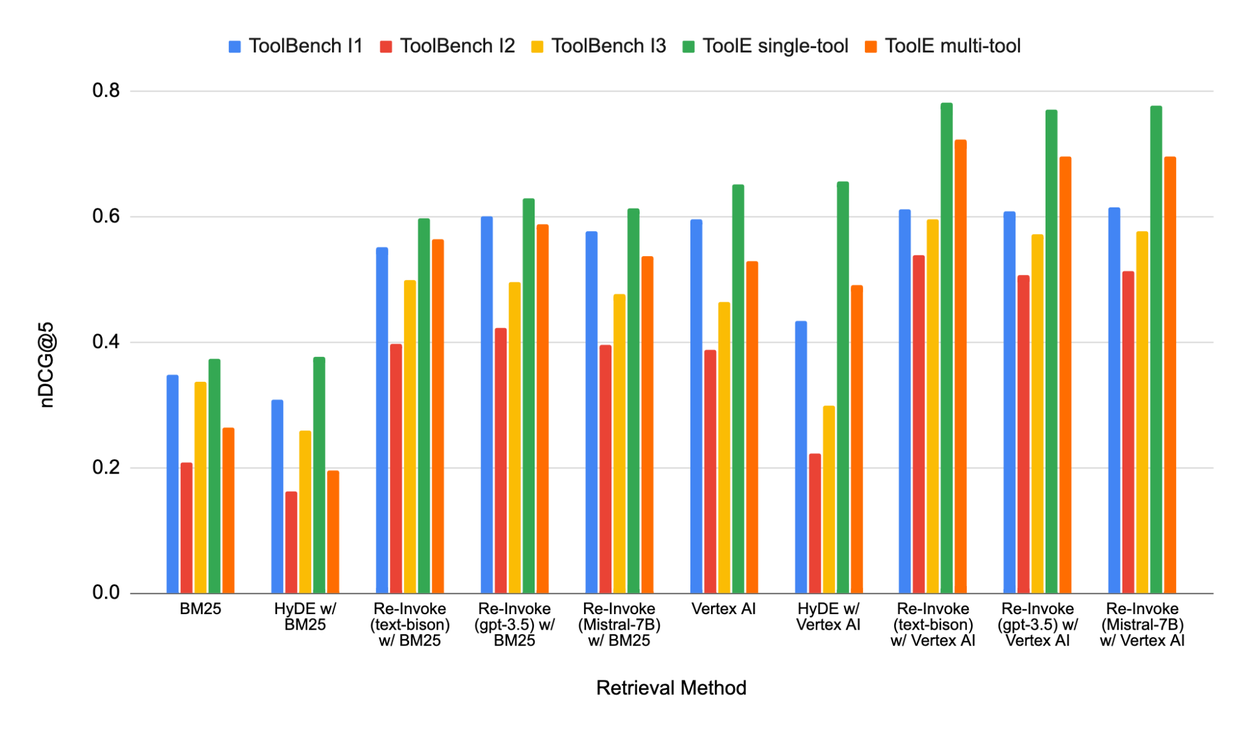
nDCG@5 metrics on ToolBench I1, I2, I3 and ToolE single-tool, multi-tool datasets using both sparse and retrieval methods. We also integrate Re-Invoke with the BM25 embedding and Vertex AI text embedding using text-bison@001, gpt-3.5-turbo and Mistral-7B-Instruct-v0.3 as three different backbone LLMs. The nDCG@5 ranges from 0 to 1, higher is better.
Case study on Re-Invoke performance
To qualitatively showcase the performance improvement with our proposed Re-Invoke retrieval method, we list some examples where the correct tools are retrieved with Re-Invoke. For example, when the user is asking for recommendations on online courses on machine learning and needs access to relevant PDFs or URLs, Re-Invoke identifies two intents, “recommend a course on machine learning” and “have access to relevant PDFs or URLs for further reading”. It also successfully retrieves the correct tools for each intent, CourseTool and PDF&URLTool. However, the baseline retrieval method retrieves CourseTool and search tools instead.
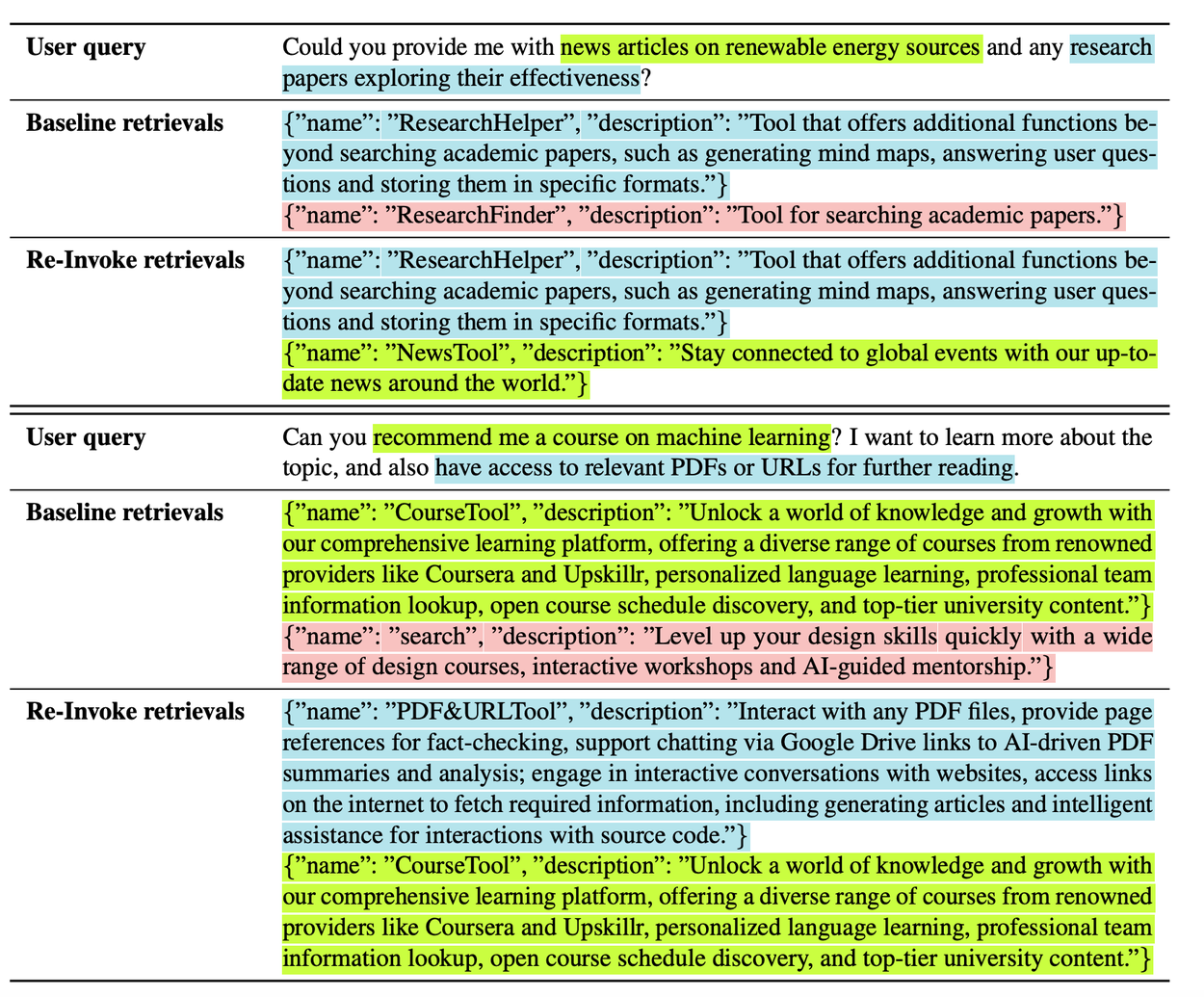
A list of example queries from the ToolE multi-tool dataset, comparing two tools retrieved by the baseline with Re-Invoke using the Vertex text embedding API. Re-Invoke identifies the intents (in green and blue) and retrieves the correct tools (in green and blue) while the baseline retrieves the wrong tools (in red).
Conclusion
We propose Re-Invoke, a fully unsupervised tool retrieval approach designed to scale LLM tool learning to large toolsets. We leverage LLMs to enhance tool document context with diverse synthetic queries and extract essential tool-related intents through intent extraction. Re-Invoke offers a fresh perspective on scalable tool retrieval, prioritizing tool document context enhancement and intent understanding without any training.
Acknowledgements
This research was conducted by Yanfei Chen, Jinsung Yoon, Devendra Singh Sachan, Qingze Wang, Vincent Cohen-Addad, Mohammadhossein Bateni, Chen-Yu Lee, and Tomas Pfister.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence


