Progress and Challenges in Long-Form Open-Domain Question Answering
March 23, 2021
Posted by Aurko Roy, Research Scientist, Google Research
Quick links
Open-domain long-form question answering (LFQA) is a fundamental challenge in natural language processing (NLP) that involves retrieving documents relevant to a given question and using them to generate an elaborate paragraph-length answer. While there has been remarkable recent progress in factoid open-domain question answering (QA), where a short phrase or entity is enough to answer a question, much less work has been done in the area of long-form question answering. LFQA is nevertheless an important task, especially because it provides a testbed to measure the factuality of generative text models. But, are current benchmarks and evaluation metrics really suitable for making progress on LFQA?
In “Hurdles to Progress in Long-form Question Answering” (to appear at NAACL 2021), we present a new system for open-domain long-form question answering that leverages two recent advances in NLP: 1) state-of-the-art sparse attention models, such as Routing Transformer (RT), which allow attention-based models to scale to long sequences, and 2) retrieval-based models, such as REALM, which facilitate retrievals of Wikipedia articles related to a given query. To encourage more factual grounding, our system combines information from several retrieved Wikipedia articles related to the given question before generating an answer. It achieves a new state of the art on ELI5, the only large-scale publicly available dataset for long-form question answering.
However, while our system tops the public leaderboard, we discover several troubling trends with the ELI5 dataset and its associated evaluation metrics. In particular, we find 1) little evidence that models actually use the retrievals on which they condition; 2) that trivial baselines (e.g., input copying) beat modern systems, like RAG / BART+DPR; and 3) that there is a significant train/validation overlap in the dataset. Our paper suggests mitigation strategies for each of these issues.
Text Generation
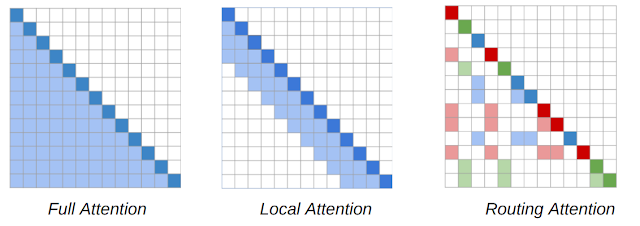
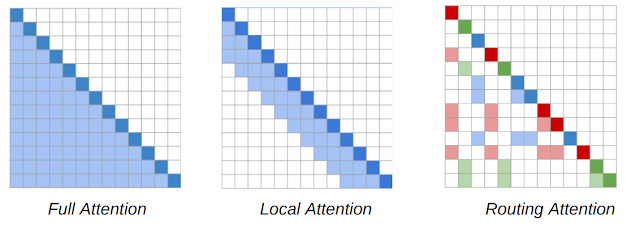
The main workhorse of NLP models is the Transformer architecture, in which each token in a sequence attends to every other token in a sequence, resulting in a model that scales quadratically with sequence length. The RT model introduces a dynamic, content-based sparse attention mechanism that reduces the complexity of attention in the Transformer model from n2 to n1.5, where n is the sequence length, which enables it to scale to long sequences. This allows each word to attend to other relevant words anywhere in the entire piece of text, unlike methods such as Transformer-XL where a word can only attend to words in its immediate vicinity.
The key insight of the RT work is that each token attending to every other token is often redundant, and may be approximated by a combination of local and global attention. Local attention allows each token to build up a local representation over several layers of the model, where each token attends to a local neighborhood, facilitating local consistency and fluency. Complementing local attention, the RT model also uses mini-batch k-means clustering to enable each token to attend only to a set of most relevant tokens.
 |
| Attention maps for the content-based sparse attention mechanism used in Routing Transformer. The word sequence is represented by the diagonal dark colored squares. In the Transformer model (left), each token attends to every other token. The shaded squares represent the tokens in the sequence to which a given token (the dark square) is attending. The RT model uses both local attention (middle), where tokens attend only to other tokens in their local neighborhood, and routing attention (right), in which a token only attends to clusters of tokens most relevant to it in context. The dark red, green and blue tokens only attend to the corresponding color of lightly shaded tokens. |
We pre-train an RT model on the Project Gutenberg (PG-19) data-set with a language modeling objective, i.e, the model learns to predict the next word given all the previous words, so as to be able to generate fluent paragraph long text.
Information Retrieval
To demonstrate the effectiveness of the RT model on the task of LFQA, we combine it with retrievals from REALM. The REALM model (Guu et al. 2020) is a retrieval-based model that uses the maximum inner product search to retrieve Wikipedia articles relevant to a particular query or question. The model was fine-tuned for factoid-based question answering on the Natural Questions dataset. REALM utilizes the BERT model to learn good representations for a question and uses SCANN to retrieve Wikipedia articles that have a high topical similarity with the question representation. This is then trained end-to-end to maximize the log-likelihood on the QA task.
We further improve the quality of REALM retrievals by using a contrastive loss. The idea behind this is to encourage the representation of a question to get close to its ground truth answer and diverge from the other answers in its mini-batch. This ensures that when the system retrieves relevant items using this question representation, it returns articles that are "similar" to ground truth answers. We call this retriever contrastive-REALM or c-REALM.
 |
| The combined RT + c-REALM system for LFQA. |
Evaluation
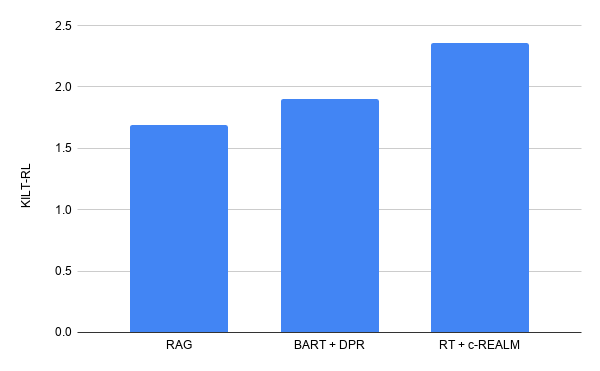
We test the model on long-form question answering using the ELI5 dataset, which is a part of the KILT benchmark, and is the only publicly available large-scale LFQA dataset. The KILT benchmark measures text retrievals using Precision (R-Prec) and text generation using ROUGE-L. The two scores are combined to give a KILT R-L score, which determines a model’s ranking on the leaderboard. We fine-tune the pre-trained RT model together with retrievals from c-REALM on the ELI5 dataset from KILT.
Our submission tops the KILT leaderboard for long-form question answering on ELI5 with a combined KILT R-L score of 2.36. It improves on the previous leaderboard entry of BART + DPR (KILT R-L score of 1.9), while having a similar number of parameters as the other models on the leaderboard. In terms of text generation quality, we see an improvement of +4.11, +5.78 and +9.14 Rouge-L over T5, BART + DPR and RAG, respectively.
 |
| Our results on the KILT leaderboard for long form question answering on ELI5. |
Example Generations from the RT Model
- Q: Why are almost all boats white?
Boats are generally painted white for obvious reasons, as they are inexpensive and easy to clean. Ships are also often painted to provide a visible visual contrast to the sea. Boats also often have high visibility ports to allow for easy international trade. In addition, many boats have an air-breathing function that makes them easier to spot and stay afloat, which is a good thing if you're a pirate or trying to get into some country's waters. Lastly, many ships are built in the last few decades, so they are not as exotic looking as they were thirty years ago. And lastly, many ships are made out of materials that are easy to work with, and so many of them are painted white as a practical matter. There are many, many more reasons for why ships are white, but those are the ones I know of. I'm sure there are many other reasons, but those are the ones I know of. Edit: I forgot to mention that the other answers about visibility and easy to see ports are also true. Ships are painted to appear to be larger, and more expensive. That makes them appear more impressive, and so they are more likely to be bought by people who want to show off their wealth and status. - Q: What causes the trail behind jets at high altitude?
The same thing that causes the clouds you see at the start of a storm to form in the first place. The air pressure changes as the jet moves through the air, causing it to cool down and condense into water droplets. These droplets are in fact a lot bigger than the water droplets in the clouds, so when the plane passes through them, they can cause the air pressure to change, causing the water droplets to condense into clouds. This is what you see when you look at a cloud formation from the ground. In addition to this, when the plane passes through the clouds, it also moves through the air, causing it to change its temperature, causing the water droplets to condense and form clouds. These clouds are often quite large, and can block out the sun. This is what you see when you look at a contrail. Finally, the water vapor that forms at high altitudes is cooled by the air above, and as it cools, it condenses into clouds. This is what you see when you look at a cumulonimbus cloud. These clouds are even larger than the water droplets in the clouds, and they block out the sun. - Q: How do shampoo and conditioner work?
The key ingredients in shampoo and conditioner are usually surfactants, they tend to attract oil from your skin. Shampoo will usually contain an anti-dandruff agent (dandruff is caused by fungi in your skin which cause dandruff). They also contain some moisturizing agents (moisturizers are things that stay in your skin longer and protect your scalp from cleaning), and a lot of anti-dandruff (dandruff is a side effect of high doses of both surfactants and moisturizers) Conditioner will contain moisturizing agents, like a skin moisturizer. They tend to cause oils to be separated from your hair (e.g. wash your hair with conditioner instead of shampoo). They both have a foaming agent that makes them foam up (usually Hydrogen Peroxide). They also have a foaming agent that stops dirt from attaching to your hair. Some conditioner will also suppress the action of the shampoo (to help prevent dirt from attaching to your hair). - Q: When glancing at a clock, why does the first second after glancing at it sometimes feel longer than the rest?
This is known as chronostasis. Your brain gets used to seeing the second hand move after the first, so it ignores the first one. If you were to look at the clock a lot, you'd see the second hand move a lot more than the first, and you'd be able to tell the difference between the second and the first. The second hand will appear to move much slower than the first hand because your brain is used to seeing the second hand move a lot more than the first. If you were to go on a long trip, you'd get used to the second hand moving a lot more than the first, and you'd have no problem telling the difference between the second and the first hand. It's kind of like how you don't notice your nose when you're driving, but if you look at it for a while, you start to notice it. Your brain is just getting used to seeing the nose move a lot more than the other, and it can't tell the difference between the two. It's kind of like that with your eyes. - Q: Why do Britain and other English empire countries still bow to monarchs? What real purpose does the queen serve?
Depends what you define as "purpose". There is no specific purpose for the British monarch - rather, they are figureheads that serve a role. The role is to have a high degree of influence over a country, though the rules of the monarchy can somewhat vary from country to country, and the ceremony of "kissing the royal corpse" does not always involve kissing the monarch. Whether that's the only reason for the custom, or if it was the only reason, I can't say, but that's the reasoning. When the U.K. was in full power, the monarch was a puppet of Parliament, and the powers of the monarch were transferred to the Prime Minister and thus to the Prime Minister's deputy, who then became the Prime Minister. Since then, Parliament has been able to vote on legislation that goes through the monarch, although they may still act as the monarch's representative in negotiating treaties, which can have very very deep consequences. The Queen's role, as a representative of Britain, doesn't necessarily involve her formal approval of any of the laws or legislation that goes through Parliament, though. - Q: What exactly is fire, in detail? How can light and heat come from something we can't really touch?
Fire is the chemical reaction of fuel (oxygen) with (what we call) impurities (ash, soot, oil etc). These impurities are created due to a number of things. If you were to study the chemical composition of a log (or a candle) and analyse it you would discover the chemical formula (A, C, and G) which is a simplified version of what actually happens. There is always fuel, and there is always the ash/soot. Wood is made up of mostly carbon and hydrogen and these are the fuels that create the fire. Hydrogen and oxygen are reactive, and they form water (H2O) and CO2 (CO2). If we split a log into smaller pieces, we start to see the process of combustion as it occurs. The carbon is burned, and with the explosion of CO, H2O and H2CO2, we get water and carbon dioxide (mostly). If we smash a log together, we start to see what happens when we also hit another log with another log...imagine smashing two sand castles together. We see how the sand castles and brick castles form and collapse at different rates...then it starts to burn. The smoke, ash and flames are the actual combustion of fuel. - Q: What goes on in those tall tower buildings owned by major banks?
The actual buildings are not there for profit but for show. There are many real world historical buildings that have little to no effect other than being a symbol of an economic entity or symbol of an era or location, and nothing more. For example look at Sears, Sears didn't care what went on inside, it was all about the \_appearance\_ of its location, the prestige of the location, the facilities and so on. It didn't care about how long it took it to operate, it was about how much people would pay to go see it. Sears was a landmark as a cultural movement and other big companies followed suit, so if you want to see a building you've never seen before, you have to go see Sears, just like you have to see a Toyota Camry for Toyota Camry. They used to be all about building new factories, some of them if I recall, but now that they're bigger, that means that more factory jobs are coming to them. You've probably seen them in stores as stores where people buy and sell stuff, so there aren't that many places for them to come from. Instead, it's just for show, a symbol of rich people.
Hurdles Towards Progress in LFQA
However, while the RT system described here tops the public leaderboard, a detailed analysis of the model and the ELI5 dataset reveal some concerning trends.
- Many held-out questions are paraphrased in the training set. Best answer to similar train questions gets 27.4 ROUGE-L.

- Simply retrieving answers to random unrelated training questions yields relatively high ROUGE-L, while actual gold answers underperform generations.

- Conditioning answer generation on random documents instead of relevant ones does not measurably impact its factual correctness. Longer outputs get higher ROUGE-L.

We find little to no evidence that the model is actually grounding its text generation in the retrieved documents — fine-tuning an RT model with random retrievals from Wikipedia (i.e., random retrieval + RT) performs nearly as well as the c-REALM + RT model (24.2 vs 24.4 ROUGE-L). We also find significant overlap in the training, validation and test sets of ELI5 (with several questions being paraphrases of each other), which may eliminate the need for retrievals. The KILT benchmark measures the quality of retrievals and generations separately, without making sure that the text generation actually use the retrievals.
 |
| Trivial baselines get higher Rouge-L scores than RAG and BART + DPR. |
Moreover, we find issues with the Rouge-L metric used to evaluate the quality of text generation, with trivial nonsensical baselines, such as a Random Training Set answer and Input Copying, achieving relatively high Rouge-L scores (even beating BART + DPR and RAG).
Conclusion
We proposed a system for long form-question answering based on Routing Transformers and REALM, which tops the KILT leaderboard on ELI5. However, a detailed analysis reveals several issues with the benchmark that preclude using it to inform meaningful modelling advances. We hope that the community works together to solve these issues so that researchers can climb the right hills and make meaningful progress in this challenging but important task.
Acknowledgments
The Routing Transformer work has been a team effort involving Aurko Roy, Mohammad Saffar, Ashish Vaswani and David Grangier. The follow-up work on open-domain long-form question answering has been a collaboration involving Kalpesh Krishna, Aurko Roy and Mohit Iyyer. We wish to thank Vidhisha Balachandran, Niki Parmar and Ashish Vaswani for several helpful discussions, and the REALM team (Kenton Lee, Kelvin Guu, Ming-Wei Chang and Zora Tung) for help with their codebase and several useful discussions, which helped us improve our experiments. We are grateful to Tu Vu for help with the QQP classifier used to detect paraphrases in ELI5 train and test sets. We thank Jules Gagnon-Marchand and Sewon Min for suggesting useful experiments on checking ROUGE-L bounds. Finally we thank Shufan Wang, Andrew Drozdov, Nader Akoury and the rest of the UMass NLP group for helpful discussions and suggestions at various stages in the project.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence