Presenting a Challenge and Workshop in Efficient Open-Domain Question Answering
June 23, 2020
Posted by Eunsol Choi, Visiting Faculty Researcher and Tom Kwiatkowski, Research Scientist, Google Research
Quick links
One of the primary goals of natural language processing is to build systems that can answer a user's questions. To do this, computers need to be able to understand questions, represent world knowledge, and reason their way to answers. Traditionally, answers have been retrieved from a collection of documents or a knowledge graph. For example, to answer the question, “When was the declaration of independence officially signed?” a system might first find the most relevant article from Wikipedia, and then locate a sentence containing the answer, “August 2, 1776”. However, more recent approaches, like T5, have also shown that neural models, trained on large amounts of web-text, can also answer questions directly, without retrieving documents or facts from a knowledge graph. This has led to significant debate about how knowledge should be stored for use by our question answering systems — in human readable text and structured formats, or in the learned parameters of a neural network.
Today, we are proud to announce the EfficientQA competition and workshop at NeurIPS 2020, organized in cooperation with Princeton University and the University of Washington. The goal is to develop an end-to-end question answering system that contains all of the knowledge required to answer open-domain questions. There are no constraints on how the knowledge is stored — it could be in documents, databases, the parameters of a neural network, or any other form — but entries will be evaluated based on the number of bytes used to access this knowledge, including code, corpora, and model parameters. There will also be an unconstrained track, in which the goal is to achieve the best possible question answering performance regardless of system size. To build small, yet robust systems, participants will have to explore new methods of knowledge representation and reasoning.
 |
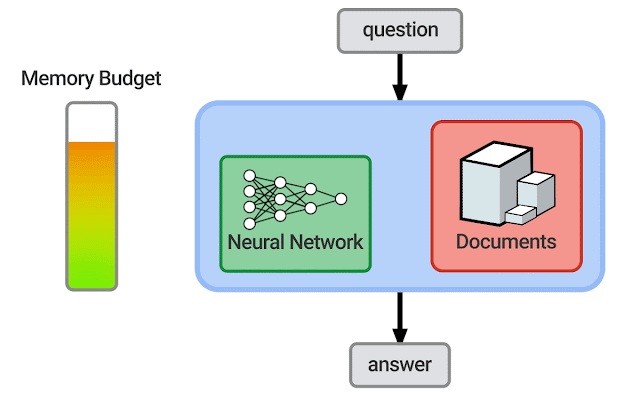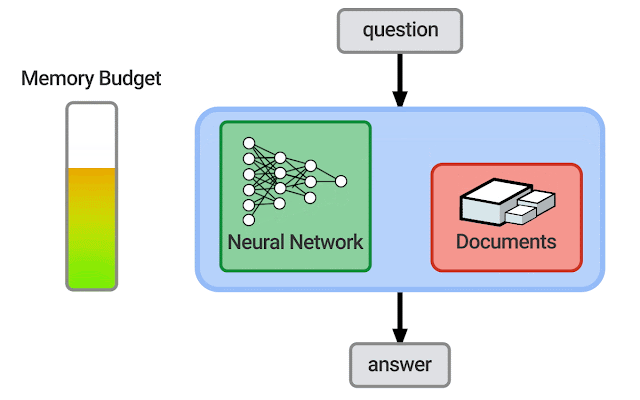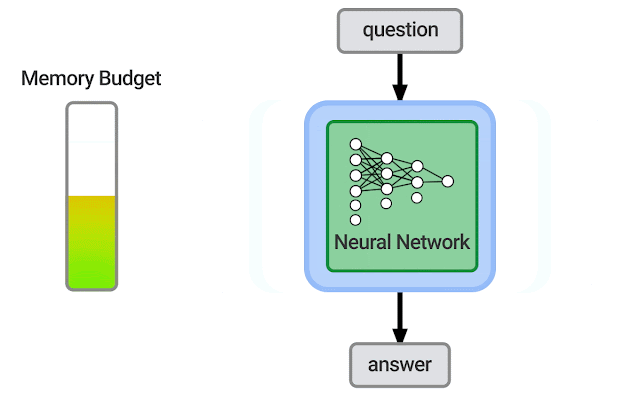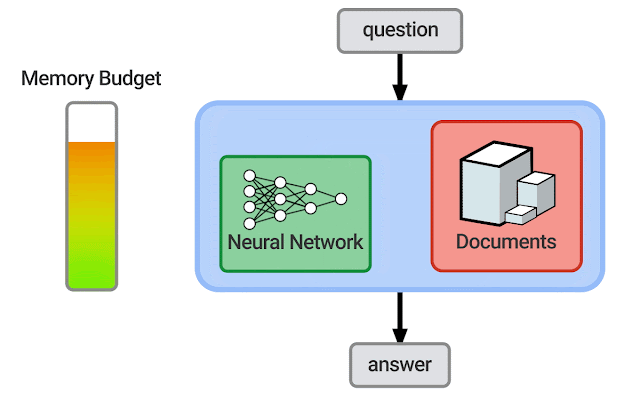
| An illustration of how the memory budget changes as a neural network and retrieval corpus grow and shrink. It is possible that successful systems will also use other resources such as a knowledge graph. |
The competition will be evaluated using the open-domain variant of the Natural Questions dataset. We will also provide further human evaluation of all the top performing entries to account for the fact that there are many correct ways to answer a question, not all of which will be covered by any set of reference answers. For example, for the question “What type of car is a Jeep considered?” both “off-road vehicles” and “crossover SUVs” are valid answers.
The competition is divided between four separate tracks: best performing system under 500 Mb; best performing system under 6 Gb; smallest system to get at least 25% accuracy; and the best performing system with no constraints. The winners of each of these tracks will be invited to present their work during the competition track at NeurIPS 2020, which will be hosted virtually. We will also put each of the winning systems up against human trivia experts (the 2017 NeurIPS Human-Computer competition featured Jeopardy! and Who Wants to Be a Millionaire champions) in a real-time contest at the virtual conference.
Participation
To participate, go to the competition site where you will find the data and evaluation code available for download, as well as dates and instructions on how to participate, and a sign-up form for updates. Along with our academic collaborators, we have provided some example systems to help you get started.
We believe that the field of natural language processing will benefit from a greater exploration and comparison of small system question answering options. We hope that by encouraging the development of very small systems, this competition will pave the way for on-device question answering.
Acknowledgements
Creating this challenge and workshop has been a large team effort including Adam Roberts, Colin Raffel, Chris Alberti, Jordan Boyd-Graber, Jennimaria Palomaki, Kenton Lee, Kelvin Guu, and Michael Collins from Google; as well as Sewon Min and Hannaneh Hajishirzi from the University of Washington; and Danqi Chen from Princeton University.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯
