Pix2Seq: A New Language Interface for Object Detection
April 22, 2022
Posted by Ting Chen and David Fleet, Research Scientists, Google Research, Brain Team
Quick links
Object detection is a long-standing computer vision task that attempts to recognize and localize all objects of interest in an image. The complexity arises when trying to identify or localize all object instances while also avoiding duplication. Existing approaches, like Faster R-CNN and DETR, are carefully designed and highly customized in the choice of architecture and loss function. This specialization of existing systems has created two major barriers: (1) it adds complexity in tuning and training the different parts of the system (e.g., region proposal network, graph matching with GIOU loss, etc.), and (2), it can reduce the ability of a model to generalize, necessitating a redesign of the model for application to other tasks.
In “Pix2Seq: A Language Modeling Framework for Object Detection”, published at ICLR 2022, we present a simple and generic method that tackles object detection from a completely different perspective. Unlike existing approaches that are task-specific, we cast object detection as a language modeling task conditioned on the observed pixel inputs. We demonstrate that Pix2Seq achieves competitive results on the large-scale object detection COCO dataset compared to existing highly-specialized and well-optimized detection algorithms, and its performance can be further improved by pre-training the model on a larger object detection dataset. To encourage further research in this direction, we are also excited to release to the broader research community Pix2Seq’s code and pre-trained models along with an interactive demo.
Pix2Seq Overview
Our approach is based on the intuition that if a neural network knows where and what the objects in an image are, one could simply teach it how to read them out. By learning to “describe” objects, the model can learn to ground the descriptions on pixel observations, leading to useful object representations. Given an image, the Pix2Seq model outputs a sequence of object descriptions, where each object is described using five discrete tokens: the coordinates of the bounding box’s corners [ymin, xmin, ymax, xmax] and a class label.
 |
| Pix2Seq framework for object detection. The neural network perceives an image, and generates a sequence of tokens for each object, which correspond to bounding boxes and class labels. |
With Pix2Seq, we propose a quantization and serialization scheme that converts bounding boxes and class labels into sequences of discrete tokens (similar to captions), and leverage an encoder-decoder architecture to perceive pixel inputs and generate the sequence of object descriptions. The training objective function is simply the maximum likelihood of tokens conditioned on pixel inputs and the preceding tokens.
Sequence Construction from Object Descriptions
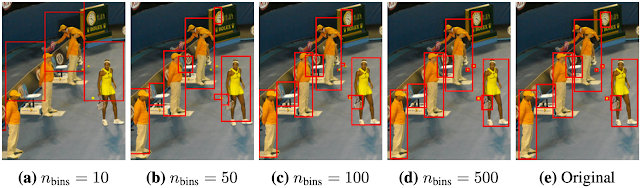
In commonly used object detection datasets, images have variable numbers of objects, represented as sets of bounding boxes and class labels. In Pix2Seq, a single object, defined by a bounding box and class label, is represented as [ymin, xmin, ymax, xmax, class]. However, typical language models are designed to process discrete tokens (or integers) and are unable to comprehend continuous numbers. So, instead of representing image coordinates as continuous numbers, we normalize the coordinates between 0 and 1 and quantize them into one of a few hundred or thousand discrete bins. The coordinates are then converted into discrete tokens as are the object descriptions, similar to image captions, which in turn can then be interpreted by the language model. The quantization process is achieved by multiplying the normalized coordinate (e.g., ymin) by the number of bins minus one, and rounding it to the nearest integer (the detailed process can be found in our paper).
 |
| Quantization of the coordinates of the bounding boxes with different numbers of bins on a 480 × 640 image. With a small number of bins/tokens, such as 500 bins (∼1 pixel/bin), it achieves high precision even for small objects. |
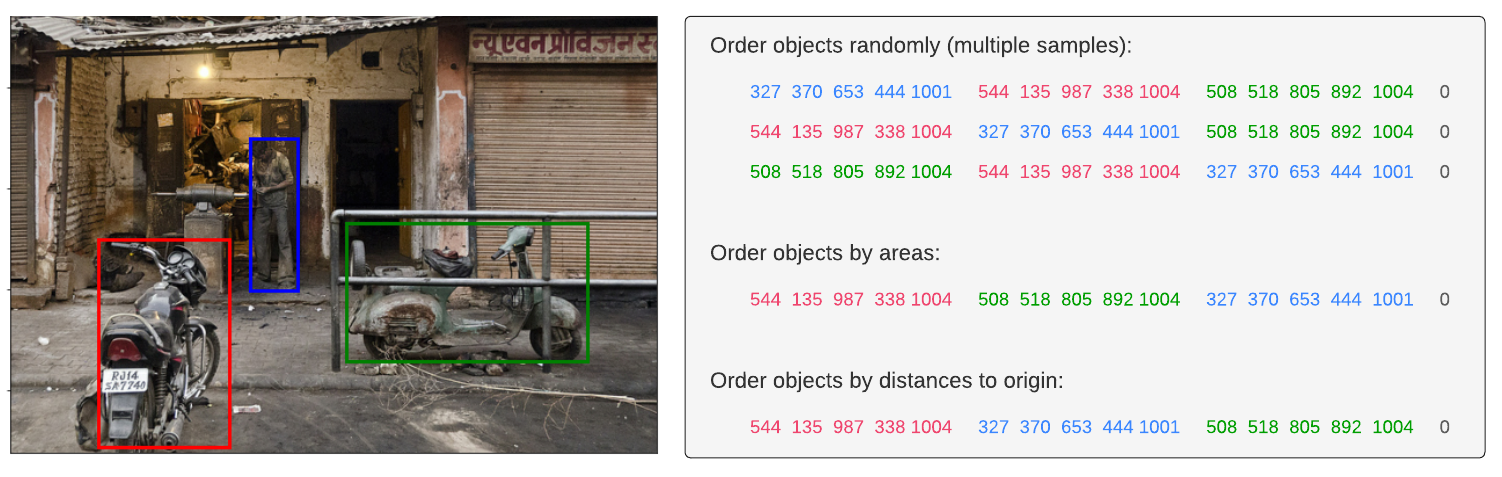
After quantization, the object annotations provided with each training image are ordered into a sequence of discrete tokens (shown below). Since the order of the objects does not matter for the detection task per se, we randomize the order of objects each time an image is shown during training. We also append an End of Sequence (EOS) token at the end as different images often have different numbers of objects, and hence sequence lengths.
 |
| The bounding boxes and class labels for objects detected in the image on the left are represented in the sequences shown on the right. A random object ordering strategy is used in our work but other approaches to ordering could also be used. |
The Model Architecture, Objective Function, and Inference
We treat the sequences that we constructed from object descriptions as a “dialect” and address the problem via a powerful and general language model with an image encoder and autoregressive language encoder. Similar to language modeling, Pix2Seq is trained to predict tokens, given an image and preceding tokens, with a maximum likelihood loss. At inference time, we sample tokens from model likelihood. The sampled sequence ends when the EOS token is generated. Once the sequence is generated, we split it into chunks of 5 tokens for extracting and de-quantizing the object descriptions (i.e., obtaining the predicted bounding boxes and class labels). It is worth noting that both the architecture and loss function are task-agnostic in that they don’t assume prior knowledge about object detection (e.g., bounding boxes). We describe how we can incorporate task-specific prior knowledge with a sequence augmentation technique in our paper.
Results
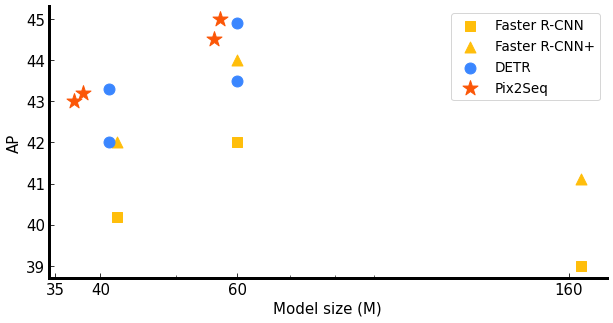
Despite its simplicity, Pix2Seq achieves impressive empirical performance on benchmark datasets. Specifically, we compare our method with well established baselines, Faster R-CNN and DETR, on the widely used COCO dataset and demonstrate that it achieves competitive average precision (AP) results.
 |
| Pix2Seq achieves competitive AP results compared to existing systems that require specialization during model design, while being significantly simpler. The best performing Pix2Seq model achieved an AP score of 45. |
Since our approach incorporates minimal inductive bias or prior knowledge of the object detection task into the model design, we further explore how pre-training the model using the large-scale object detection COCO dataset can impact its performance. Our results indicate that this training strategy (along with using bigger models) can further boost performance.
 |
| The average precision of the Pix2Seq model with pre-training followed by fine-tuning. The best performing Pix2Seq model without pre-training achieved an AP score of 45. When the model is pre-trained, we see an 11% improvement with an AP score of 50. |
Pix2Seq can detect objects in densely populated and complex scenes, such as those shown below.
 |
| Example complex and densely populated scenes labeled by a trained Pix2Seq model. Try it out here. |
Conclusion and Future Work
With Pix2Seq, we cast object detection as a language modeling task conditioned on pixel inputs for which the model architecture and loss function are generic, and have not been engineered specifically for the detection task. One can, therefore, readily extend this framework to different domains or applications, where the output of the system can be represented by a relatively concise sequence of discrete tokens (e.g., keypoint detection, image captioning, visual question answering), or incorporate it into a perceptual system supporting general intelligence, for which it provides a language interface to a wide range of vision and language tasks. We also hope that the release of our Pix2Seq’s code, pre-trained models and interactive demo will inspire further research in this direction.
Acknowledgements
This post reflects the combined work with our co-authors: Saurabh Saxena, Lala Li, Geoffrey Hinton. We would also like to thank Tom Small for the visualization of the Pix2Seq illustration figure.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence