
Patchscopes: A unifying framework for inspecting hidden representations of language models
April 11, 2024
Avi Caciularu and Asma Ghandeharioun, Research Scientists, Google Research
Quick links
The remarkable advancements in large language models (LLMs) and the concerns associated with them, such as factuality and transparency, highlight the importance of comprehending their mechanisms, particularly in instances where they produce errors. By exploring the way a machine learning (ML) model represents what it has learned (the model's so called hidden representations), we can gain better control over a model's behavior and unlock a deeper scientific understanding of how these models really work. This question has become even more important as deep neural networks grow in complexity and scale. Recent advances in interpretability research show promising results in using LLMs to explain neuron patterns within another model.
These findings motivate our design of a novel framework to investigate hidden representations in LLMs with LLMs, which we call Patchscopes. The key idea behind this framework is to use LLMs to provide natural language explanations of their own internal hidden representations. Patchscopes unifies and extends a broad range of existing interpretability techniques, and it enables answering questions that were difficult or impossible before. For example, it offers insights into how an LLM's hidden representations capture nuances of meaning in the model's input, making it easier to fix certain types of reasoning errors. While we initially focus the application of Patchscopes to the natural language domain and the autoregressive Transformer model family, its potential applications are broader. For example, we are excited about its applications to detection and correction of model hallucinations, the exploration of multimodal (image and text) representations, and the investigation of how models build their predictions in more complex scenarios.
Patchscopes walkthrough with an example
Consider the task of understanding how an LLM processes co-references to entities within a text. An implementation of Patchscopes is a specialized tool crafted to address the specific problem of co-reference resolution. For instance, to investigate a model's contextual understanding of whom a pronoun like “it” refers to, a Patchscopes configuration can be created as follows (also illustrated below):
- The Setup: A standard prompt (namely, the “source prompt”) containing relevant contextual information is presented to the model under investigation. The full source prompt in the example below is “Patchscopes is robust. It helps interpret…”.
- The Target: A secondary prompt (namely, the “target prompt”) is designed to extract specific hidden information. In this example, a simple word-repetition prompt can reveal information from the hidden representation. The target prompt in the example below is “cat->cat; 135->135; hello->hello; ?”. Note that these words are randomly selected and so the prompt might look like gibberish at first, but there is also a pattern: it is composed of a few examples, where each example is a word, an arrow, and a repetition of the same word. If we feed this text to a language model trained to predict the next word, it is expected to continue to follow this pattern. That is, if we replace "?" with any random word and let the model generate the next word, it should repeat whatever we used to replace "?".
- The Patch: Inference is performed on the source prompt. The hidden representation at the layer of interest in the token for "It" (green dot in the example below) is injected into the target prompt (the orange dot in the example below). Optionally, a transformation can be applied (the “f” in the example below) to align the representation with other layers or models.
- The Reveal: The model processes the augmented input, and its output provides insights into how the original model internally comprehends the word "It" within its specific context. In the example below, the model generates “Patchscopes”, explaining the hidden representation at the 4th layer of the model above the “It” token. This shows that after 4 layers of computation, the model has incorporated information from previous words into this hidden representation above the “It” token, and has concluded that it is no longer referring to a generic object, but rather to “Patchscopes”. While this token representation (green dot) might otherwise look like an inscrutable vector of floating point numbers, Patchscopes can translate it into human-understandable text, showing that it refers to “Patchscopes”. This is in line with prior work that suggests information about a subject gets accrued in its last token.
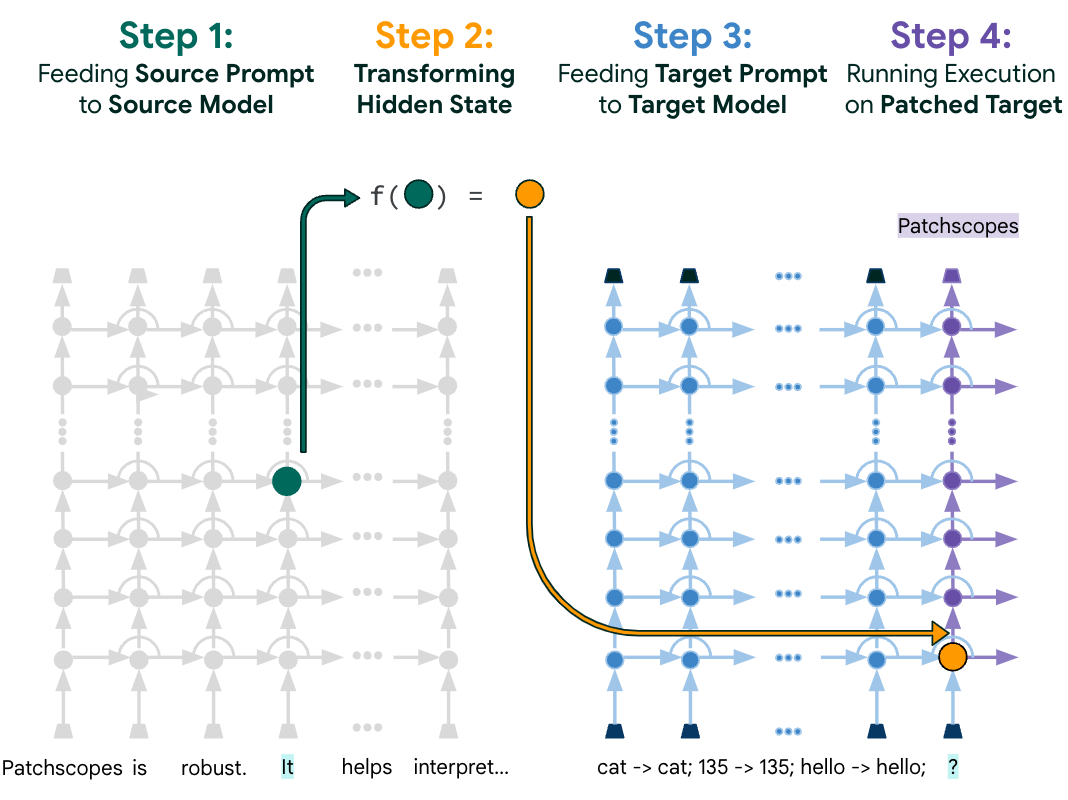
Illustration of our framework, showing a Patchscope for decoding what is encoded in the representation of “It” in the source prompt (left), by using a predefined target prompt (right).
Patchscopes in action
Patchscopes has a broad range of applications for understanding and controlling LLMs. Here are a few examples we explored:
- Next-token prediction: How early in the computation might the model have concluded its final prediction from the given context?
Next token prediction from intermediate hidden representations is a widely used task to evaluate interpretability methods that look at the internals of transformers. Application of the Patchscope used in the previous section is surprisingly effective at this also, even in the usually much trickier early- to mid-layers of processing. Across different language models, it uniformly outperforms prior methods like Tuned Lens and Logit Lens from layer 10 onward.
Evaluating various interpretability methods using the next token prediction task from the intermediate hidden representations of an LLM. This shows our application of Patchscopes with a simple "Token Identity" target prompt (that is, a target prompt composed of k demonstrations representing an identity-like function, formatted as "tok_1 → tok_1 ; tok_2 → tok_2 ; . . . ; tok_k") compared to Tuned Lens and Logit Lens methods. The x-axis is the hidden representations' layer that is being examined in the LLM. The y-axis shows precision@1, which measures the proportion of examples where the highest probability predicted token matches the highest probability token in the original distribution. - Pulling out facts: How early in a model's computation does it have attribute information (e.g., the currency of a country)?
In this experiment, we consider the task of extracting attributes from texts that originate from commonsense and factual knowledge tasks compiled by Hernandez et al., 2024. Here we use a target prompt that is a simple verbalization of the relation under investigation, followed by a placeholder for the subject. For example, to extract the official currency of the United States from the representation of “States”, we use the target prompt, "The official currency of x". Given that this application of Patchscopes does not use any training examples, it's notable that it significantly outperforms other techniques.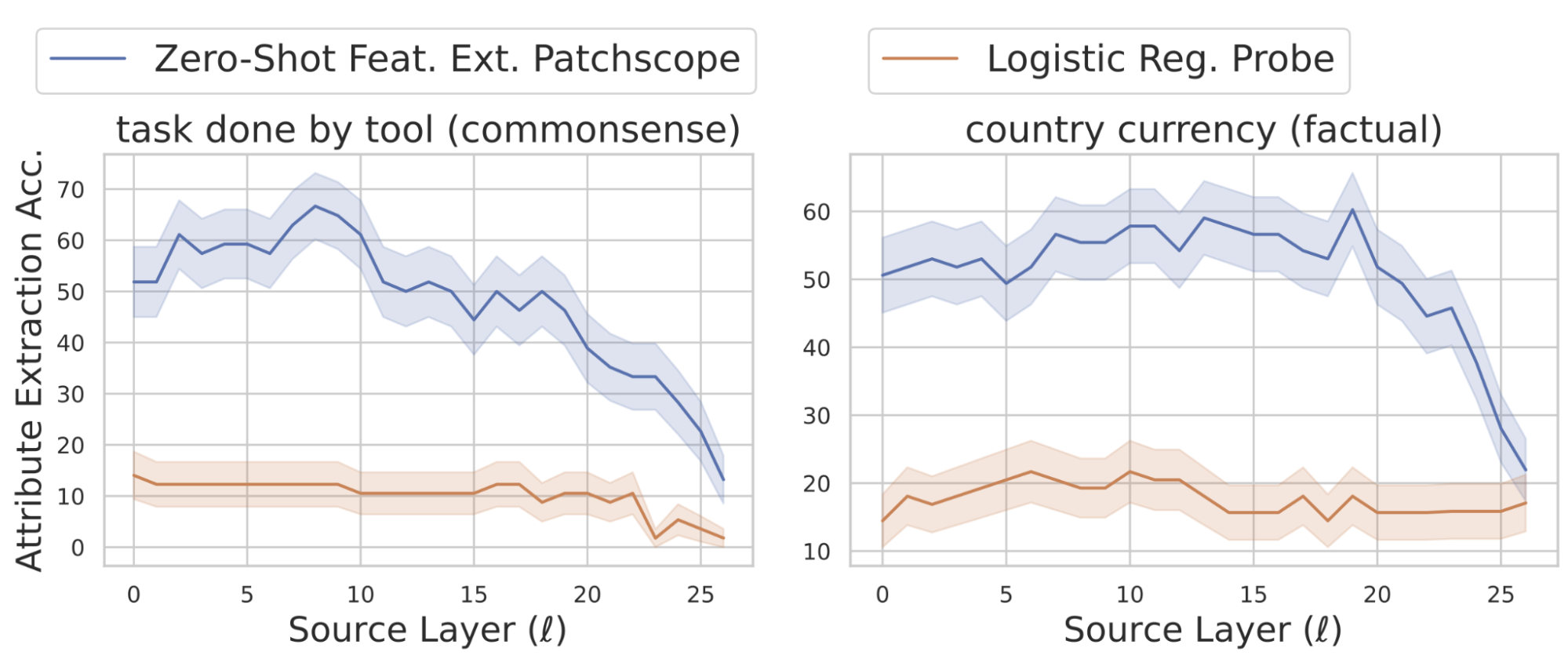
Attribute extraction accuracy across source layers (ℓ). Left: Task done by tool (commonsense), 54 Source prompts, 12 Classes. Right: Country currency (factual), 83 Source prompts, 14 Classes. - Explaining entities: Beyond just "Yes" or "No"
How does a model understand a multi-word input like "Alexander the Great" as it processes input? Patchscopes goes beyond simple “has it figured this out yet” answers to reveal how the model gradually understands an entity, even in the very beginning stages. We use the following few-shot target prompt to decode the model’s gradual processing: "Syria: Country in the Middle East, Leonardo DiCaprio: American actor, Samsung: South Korean multinational major appliance and consumer electronics corporation, x". The table below shows that as we go through the layers of two different models, Vicuna 13B and Pythia 12B, more words from the context get integrated into the current representation as reflected in the generations.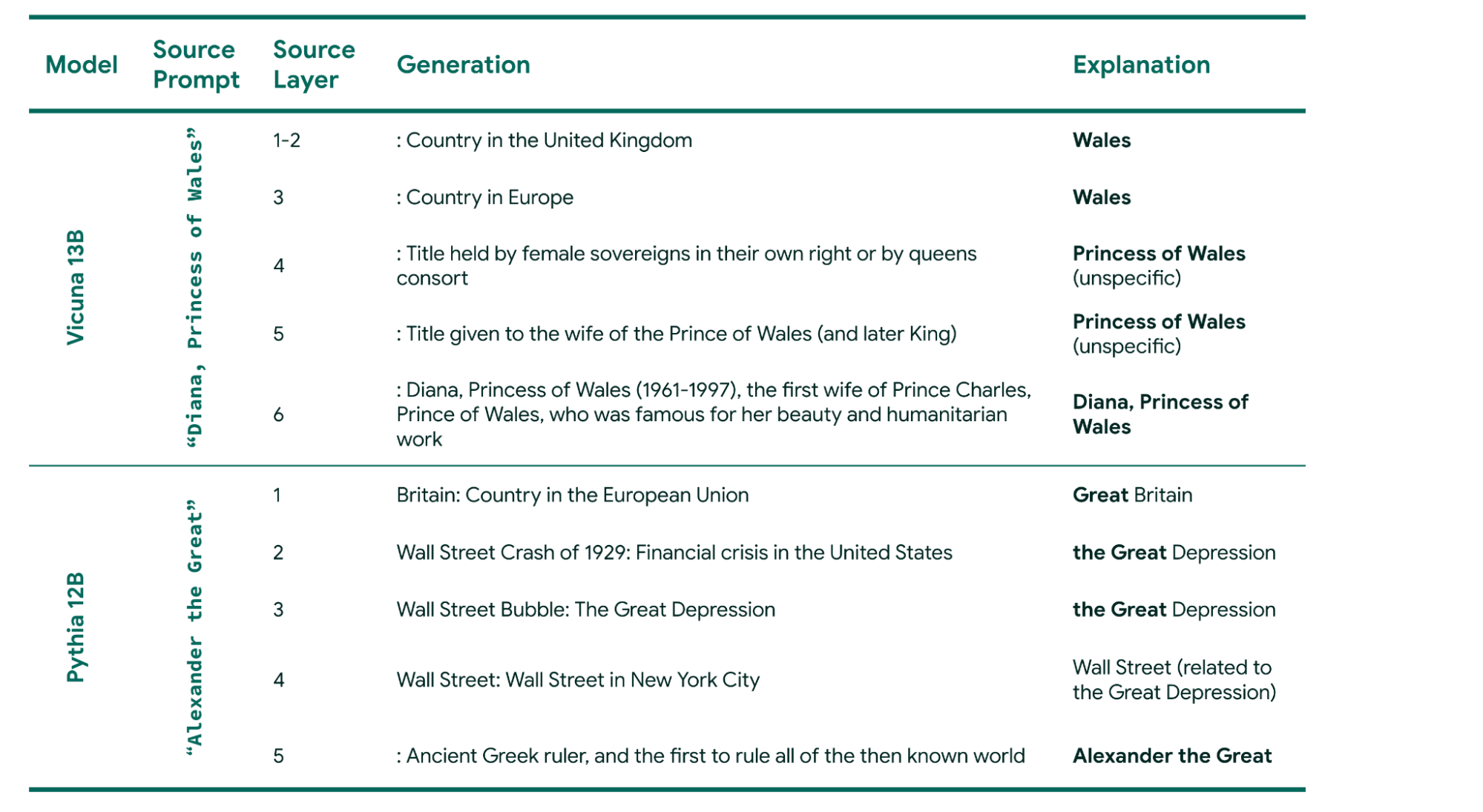
Illustrating entity resolution via qualitative examples. The expressive generations show that as we go through the layers, more tokens from the context get integrated into the current representation. "Explanation" is what the generation seems to be referring to and how that relates to the source prompt. Both these examples use the same target prompt described above. - Teamwork makes the dream work: Models explaining models
The Patchscopes framework lets us use a powerful language model to decode the process of a smaller one. Here, we leveraged Vicuna 13B to explain Vicuna 7B input processing by patching hidden representations of entities from the smaller model into the larger one. We measure the lexical similarity (using the RougeL score) between the model-generated text and the actual reference description sourced from Wikipedia. Vicuna 7B → 13B (green line) is almost always above the Vicuna 7B → 7B (blue line) and has a higher area under the curve. This shows that cross-model patching into a larger and more expressive model results in improved lexical similarity between generations and the reference text, and demonstrates that the process of cross-model patching significantly enhances the model's ability to generate text that is contextually aligned with the input representation from another model.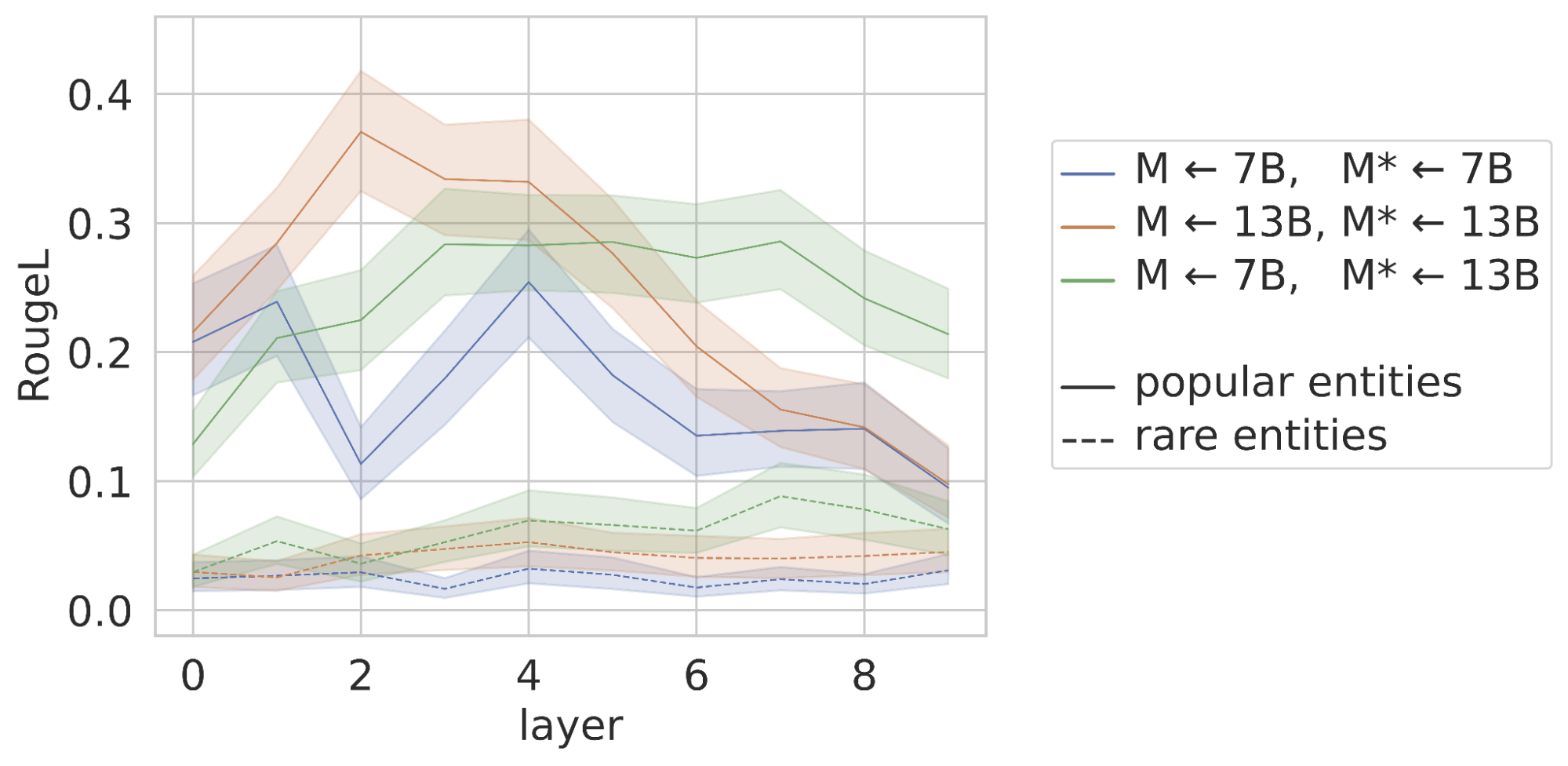
RougeL (lexical similarity) scores of the generated descriptions against descriptions from Wikipedia, using the Vicuna models. Patched representations from Vicuna 7B to Vicuna 13B result in a more expressive verbalization of entity resolution, both for popular and rare entities. - Fixing faulty reasoning
The most advanced LLMs can still struggle with multi-step reasoning, even if they are able to solve each reasoning step in isolation. Patchscopes can help address this by rerouting the intermediate hidden representations, significantly boosting accuracy. In this experiment, we systematically generate multi-hop factual and commonsense reasoning queries, and show that with prior knowledge about the input’s structure, errors can be fixed by patching the hidden representations from one part of the query into another. We call this a chain-of-thought (CoT) Pathcscope, because it enforces sequential reasoning using the same prompt for source and target, but patching the hidden representation of one position into another. We show that CoT Patchscope improves accuracy from 19.57% to 50%. Our goal with this experiment is to demonstrate that it is feasible to use Patchscopes for intervention and correction, but caution that the CoT Pathscope is meant as an illustration rather than a generic correction method.
An illustration of CoT Patchscope on a single example, focusing on a response needing correction with the prompt "The current CEO of the company that created Visual Basic Script".
The takeaway
The Patchscopes framework is a breakthrough in understanding how language models work. It helps answer a wide range of questions from simple predictions to extracting knowledge from hidden representations and fixing errors in LLMs’ complex reasoning. This has intriguing implications for improving the reliability and transparency of the powerful language models we use every day. Want to see Patchscopes in action? Find more details in the paper.
Quick links
Other posts of interest
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence




Illustration of our framework, showing a Patchscope for decoding what is encoded in the representation of “It” in the source prompt (left), by using a predefined target prompt (right).
