Parrotron: New Research into Improving Verbal Communication for People with Speech Impairments
July 17, 2019
Posted by Fadi Biadsy, Research Scientist and Ron Weiss, Software Engineer, Google Research
Quick links
Most people take for granted that when they speak, they will be heard and understood. But for the millions who live with speech impairments caused by physical or neurological conditions, trying to communicate with others can be difficult and lead to frustration. While there have been a great number of recent advances in automatic speech recognition (ASR; a.k.a. speech-to-text) technologies, these interfaces can be inaccessible for those with speech impairments. Further, applications that rely on speech recognition as input for text-to-speech synthesis (TTS) can exhibit word substitution, deletion, and insertion errors. Critically, in today’s technological environment, limited access to speech interfaces, such as digital assistants that depend on directly understanding one's speech, means being excluded from state-of-the-art tools and experiences, widening the gap between what those with and without speech impairments can access.
Project Euphonia has demonstrated that speech recognition models can be significantly improved to better transcribe a variety of atypical and dysarthric speech. Today, we are presenting Parrotron, an ongoing research project that continues and extends our effort to build speech technologies to help those with impaired or atypical speech to be understood by both people and devices. Parrotron consists of a single end-to-end deep neural network trained to convert speech from a speaker with atypical speech patterns directly into fluent synthesized speech, without an intermediate step of generating text—skipping speech recognition altogether. Parrotron’s approach is speech-centric, looking at the problem only from the point of view of speech signals—e.g., without visual cues such as lip movements. Through this work, we show that Parrotron can help people with a variety of atypical speech patterns—including those with ALS, deafness, and muscular dystrophy—to be better understood in both human-to-human interactions and by ASR engines.
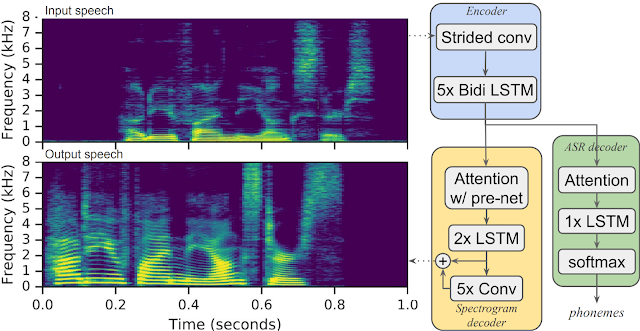
Parrotron is an attention-based sequence-to-sequence model trained in two phases using parallel corpora of input/output speech pairs. First, we build a general speech-to-speech conversion model for standard fluent speech, followed by a personalization phase that adjusts the model parameters to the atypical speech patterns from the target speaker. The primary challenge in such a configuration lies in the collection of the parallel training data needed for supervised training, which consists of utterances spoken by many speakers and mapped to the same output speech content spoken by a single speaker. Since it is impractical to have a single speaker record the many hours of training data needed to build a high quality model, Parrotron uses parallel data automatically derived with a TTS system. This allows us to make use of a pre-existing anonymized, transcribed speech recognition corpus to obtain training targets.
The first training phase uses a corpus of ~30,000 hours that consists of millions of anonymized utterance pairs. Each pair includes a natural utterance paired with an automatically synthesized speech utterance that results from running our state-of-the-art Parallel WaveNet TTS system on the transcript of the first. This dataset includes utterances from thousands of speakers spanning hundreds of dialects/accents and acoustic conditions, allowing us to model a large variety of voices, linguistic and non-linguistic contents, accents, and noise conditions with “typical” speech all in the same language. The resulting conversion model projects away all non-linguistic information, including speaker characteristics, and retains only what is being said, not who, where, or how it is said. This base model is used to seed the second personalization phase of training.
The second training phase utilizes a corpus of utterance pairs generated in the same manner as the first dataset. In this case, however, the corpus is used to adapt the network to the acoustic/phonetic, phonotactic and language patterns specific to the input speaker, which might include, for example, learning how the target speaker alters, substitutes, and reduces or removes certain vowels or consonants. To model ALS speech characteristics in general, we use utterances taken from an ALS speech corpus derived from Project Euphonia. If instead we want to personalize the model for a particular speaker, then the utterances are contributed by that person. The larger this corpus is, the better the model is likely to be at correctly converting to fluent speech. Using this second smaller and personalized parallel corpus, we run the neural-training algorithm, updating the parameters of the pre-trained base model to generate the final personalized model.
We found that training the model with a multitask objective to predict the target phonemes while simultaneously generating spectrograms of the target speech led to significant quality improvements. Such a multitask trained encoder can be thought of as learning a latent representation of the input that maintains information about the underlying linguistic content.
 |
| Overview of the Parrotron model architecture. An input speech spectrogram is passed through encoder and decoder neural networks to generate an output spectrogram in a new voice. |
To demonstrate a proof of concept, we worked with our fellow Google research scientist and mathematician Dimitri Kanevsky, who was born in Russia to Russian speaking, normal-hearing parents but has been profoundly deaf from a very young age. He learned to speak English as a teenager, by using Russian phonetic representations of English words, learning to pronounce English using transliteration into Russian (e.g., The quick brown fox jumps over the lazy dog => ЗИ КВИК БРАУН ДОГ ЖАМПС ОУВЕР ЛАЙЗИ ДОГ). As a result, Dimitri’s speech is substantially distinct from native English speakers, and can be challenging to comprehend for systems or listeners who are not accustomed to it.
Dimitri recorded a corpus of 15 hours of speech, which was used to adapt the base model to the nuances specific to his speech. The resulting Parrotron system helped him be better understood by both people and Google’s ASR system alike. Running Google’s ASR engine on the output of Parrotron significantly reduced the word error rate from 89% to 32%, on a held out test set from Dimitri. Below is an example of Parrotron’s successful conversion of input speech from Dimitri:
| Dimitri saying, "How far is the Moon from the Earth?" | |
| Parrotron (male voice) saying, "How far are the Moon from the Earth?" |
We also worked with Aubrie Lee, a Googler and advocate for disability inclusion, who has muscular dystrophy, a condition that causes progressive muscle weakness, and sometimes impacts speech production. Aubrie contributed 1.5 hours of speech, which has been instrumental in showing promising outcomes of the applicability of this speech-to-speech technology. Below is an example of Parrotron’s successful conversion of input speech from Aubrie:
| Aubrie saying, "Is morning glory a perennial plant?" | |
| Parrotron (female voice) saying, "Is morning glory a perennial plant?" | |
| Aubrie saying, "Schedule a meeting with John on Friday." | |
| Parrotron (female voice) saying, "Schedule a meeting with John on Friday." |
We also tested Parrotron’s performance on speech from speakers with ALS by adapting the pretrained model on multiple speakers who share similar speech characteristics grouped together, rather than on a single speaker. We conducted a preliminary listening study and observed an increase in intelligibility when comparing natural ALS speech to the corresponding speech obtained from running the Parroton model, for the majority of our test speakers.
Cascaded Approach
Project Euphonia has built a personalized speech-to-text model that has reduced the word error rate for a deaf speaker from 89% to 25%, and ongoing research is also likely to improve upon these results. One could use such a speech-to-text model to achieve a similar goal as Parrotron by simply passing its output into a TTS system to synthesize speech from the result. In such a cascaded approach, however, the recognizer may choose an incorrect word (roughly 1 out 4 times, in this case)—i.e., it may yield words/sentences with unintended meaning and, as a result, the synthesized audio of these words would be far from the speaker’s intention. Given the end-to-end speech-to-speech training objective function of Parrotron, even when errors are made, the generated output speech is likely to sound acoustically similar to the input speech, and thus the speaker’s original intention is less likely to be significantly altered and it is often still possible to understand what is intended:
| Dimitri saying, "What is definition of rhythm?" | |
| Parrotron (male voice) saying, "What is definition of rhythm?" | |
| Dimitri saying, "How many ounces in one liter?" | |
| Parrotron (male voice) saying, "Hey Google, How many unces [sic] in one liter?" | |
| Google Assistant saying, "One liter is equal to thirty-three point eight one four US fluid ounces." | |
| Aubrie saying, "Is it wheelchair accessible?" | |
| Parrotron (female voice) saying, "Is it wheelchair accecable [sic]?" |
Furthermore, since Parrotron is not strongly biased to producing words from a predefined vocabulary set, input to the model may contain completely new invented words, foreign words/names, and even nonsense words. We observe that feeding Arabic and Spanish utterances into the US-English Parrotron model often results in output which echoes the original speech content with an American accent, in the target voice. Such behavior is qualitatively different from what one would obtain by simply running an ASR followed by a TTS. Finally, by going from a combination of independently tuned neural networks to a single one, we also believe there are improvements and simplifications that could be substantial.
Conclusion
Parrotron makes it easier for users with atypical speech to talk to and be understood by other people and by speech interfaces, with its end-to-end speech conversion approach more likely to reproduce the user’s intended speech. More exciting applications of Parrotron are discussed in our paper and additional audio samples can be found on our github repository. If you would like to participate in this ongoing research, please fill out this short form and volunteer to record a set of phrases. We look forward to working with you!
This project was joint work between the Speech and Google Brain teams. Contributors include Fadi Biadsy, Ron Weiss, Pedro Moreno, Dimitri Kanevsky, Ye Jia, Suzan Schwartz, Landis Baker, Zelin Wu, Johan Schalkwyk, Yonghui Wu, Zhifeng Chen, Patrick Nguyen, Aubrie Lee, Andrew Rosenberg, Bhuvana Ramabhadran, Jason Pelecanos, Julie Cattiau, Michael Brenner, Dotan Emanuel, Joel Shor, Sean Lee and Benjamin Schroeder. Our data collection efforts have been vastly accelerated by our collaborations with ALS-TDI.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
March 17, 2026
Improving breast cancer screening workflows with machine learning- Health & Bioscience ·
- Human-Computer Interaction and Visualization
×
❮
❯
