Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision
May 21, 2020
Posted by Lucas Beyer and Alexander Kolesnikov, Research Engineers, Google Research, Zürich
Quick links
A common refrain for computer vision researchers is that modern deep neural networks are always hungry for more labeled data — current state-of-the-art CNNs need to be trained on datasets such as OpenImages or Places, which consist of over 1M labelled images. However, for many applications, collecting this amount of labeled data can be prohibitive to the average practitioner.
A common approach to mitigate the lack of labeled data for computer vision tasks is to use models that have been pre-trained on generic data (e.g., ImageNet). The idea is that visual features learned on the generic data can be re-used for the task of interest. Even though this pre-training works reasonably well in practice, it still falls short of the ability to both quickly grasp new concepts and understand them in different contexts. In a similar spirit to how BERT and T5 have shown advances in the language domain, we believe that large-scale pre-training can advance the performance of computer vision models.
In “Big Transfer (BiT): General Visual Representation Learning” we devise an approach for effective pre-training of general features using image datasets at a scale beyond the de-facto standard (ILSVRC-2012). In particular, we highlight the importance of appropriately choosing normalization layers and scaling the architecture capacity as the amount of pre-training data increases. Our approach exhibits unprecedented performance adapting to a wide range of new visual tasks, including the few-shot recognition setting and the recently introduced “real-world” ObjectNet benchmark. We are excited to share the best BiT models pre-trained on public datasets, along with code in TF2, Jax, and PyTorch. This will allow anyone to reach state-of-the-art performance on their task of interest, even with just a handful of labeled images per class.
Pre-training
In order to investigate the effect of data scale, we revisit common design choices of the pre-training setup (such as normalizations of activations and weights, model width/depth and training schedules) using three datasets: ILSVRC-2012 (1.28M images with 1000 classes), ImageNet-21k (14M images with ~21k classes) and JFT (300M images with ~18k classes). Importantly, with these datasets we concentrate on the previously underexplored large data regime.
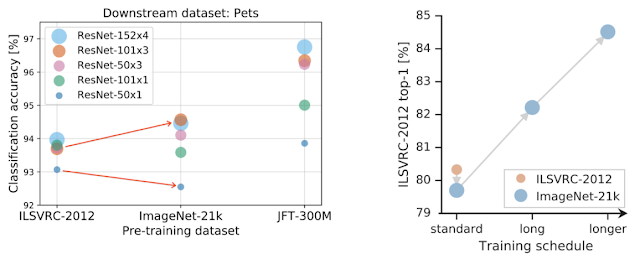
We first investigate the interplay between dataset size and model capacity. To do this we train classical ResNet architectures, which perform well, while being simple and reproducible. We train variants from the standard 50-layer deep “R50x1” up to the 4x wider and 152-layer deep “R152x4” on each of the above-mentioned datasets. A key observation is that in order to profit from more data, one also needs to increase model capacity. This is exemplified by the red arrows in the left-hand panel of the figure below
 |
| Left: In order to make effective use of a larger dataset for pre-training, one needs to increase model capacity. The red arrows exemplify this: small architectures (smaller point) become worse when pre-trained on the larger ImageNet-21k, whereas the larger architectures (larger points) improve. Right: Pre-training on a larger dataset alone does not necessarily result in improved performance, e.g., when going from ILSVRC-2012 to the relatively larger ImageNet-21k. However, by also increasing the computational budget and training for longer, the performance improvement is pronounced. |
During our exploration phase, we discovered another modification crucial to improving performance. We show that replacing batch normalization (BN, a commonly used layer that stabilizes training by normalizing activations) with group normalization (GN) is beneficial for pre-training at large scale. First, BN’s state (mean and variance of neural activations) needs adjustment between pre-training and transfer, whereas GN is stateless, thus side-stepping this difficulty. Second, BN uses batch-level statistics, which become unreliable with small per-device batch sizes that are inevitable for large models. Since GN does not compute batch-level statistics, it also side-steps this issue. For more technical details, including the use of a weight standardization technique to ensure stable behavior, please see our paper.
 |
| Summary of our pre-training strategy: take a standard ResNet, increase depth and width, replace BatchNorm (BN) with GroupNorm and Weight Standardization (GNWS), and train on a very large and generic dataset for many more iterations. |
Following the methods established in the language domain by BERT, we fine-tune the pre-trained BiT model on data from a variety of “downstream” tasks of interest, which may come with very little labeled data. Because the pre-trained model already comes with a good understanding of the visual world, this simple strategy works remarkably well.
Fine-tuning comes with a lot of hyper-parameters to be chosen, such as learning-rate, weight-decay, etc. We propose a heuristic for selecting these hyper-parameters that we call “BiT-HyperRule”, which is based only on high-level dataset characteristics, such as image resolution and the number of labeled examples. We successfully apply the BiT-HyperRule on more than 20 diverse tasks, ranging from natural to medical images.
 |
| Once the BiT model is pre-trained, it can be fine-tuned on any task, even if only few labeled examples are available. |
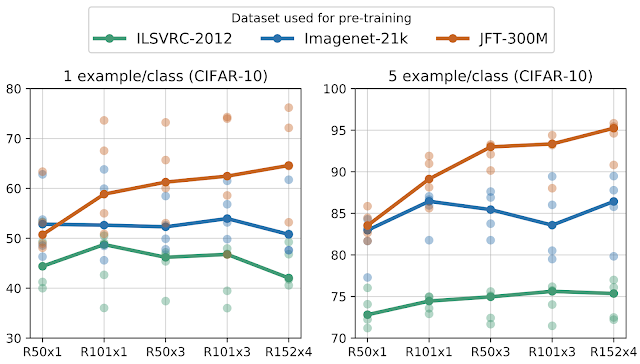
 |
| The curves depict median accuracy over 5 independent runs (light points) when transferring to CIFAR-10 with only 1 or 5 images per class (10 or 50 images total). It is evident that large architectures pre-trained on large datasets are significantly more data-efficient. |
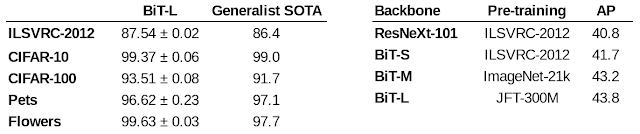
We show that this strategy of large-scale pre-training and simple transfer is effective even when a moderate amount of data is available by evaluating BiT-L on several standard computer vision benchmarks such as Oxford Pets and Flowers, CIFAR, etc. On all of these, BiT-L matches or surpasses state-of-the-art results. Finally, we use BiT as a backbone for RetinaNet on the MSCOCO-2017 detection task and confirm that even for such a structured output task, using large-scale pre-training helps considerably.
 |
| Left: Accuracy of BiT-L compared to the previous state-of-the-art general model on various standard computer vision benchmarks. Right: Results in average precision (AP) of using BiT as backbone for RetinaNet on MSCOCO-2017. |
Evaluation with ObjectNet
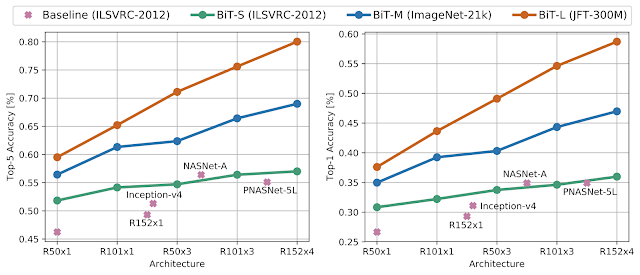
To further assess the robustness of BiT in a more challenging scenario, we evaluate BiT models that were fine-tuned on ILSVRC-2012 on the recently introduced ObjectNet dataset. This dataset closely resembles real-world scenarios, where objects may appear in atypical context, viewpoint, rotation, etc. Interestingly, the benefit from data and architecture scale is even more pronounced with the BiT-L model achieving unprecedented top-5 accuracy of 80.0%, an almost 25% absolute improvement over the previous state-of-the-art.
 |
| Results of BiT on the ObjectNet evaluation dataset. Left: top-5 accuracy, right: top-1 accuracy. |
We show that given pre-training on large amounts of generic data, a simple transfer strategy leads to impressive results, both on large datasets as well as tasks with very little data, down to a single image per class. We release the BiT-M model, a R152x4 pre-trained on ImageNet-21k, along with colabs for transfer in Jax, TensorFlow2, and PyTorch. In addition to the code release, we refer the reader to the hands-on TensorFlow2 tutorial on how to use BiT models. We hope that practitioners and researchers find it a useful alternative to commonly used ImageNet pre-trained models.
Acknowledgements
We would like to thank Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby who have co-authored the BiT paper and been involved in all aspects of its development, as well as the Brain team in Zürich. We also would like to thank Andrei Giurgiu for his help in debugging input pipelines. We thank Tom Small for creating the animations used in this blogpost. Finally, we refer the interested reader to the related approaches in this direction by our colleagues in Google Research, Noisy Student, as well as Facebook Research’s highly relevant Exploring the Limits of Weakly Supervised Pretraining.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯