Open Images V6 — Now Featuring Localized Narratives
February 26, 2020
Posted by Jordi Pont-Tuset, Research Scientist, Google Research
Quick links
Open Images is the largest annotated image dataset in many regards, for use in training the latest deep convolutional neural networks for computer vision tasks. With the introduction of version 5 last May, the Open Images dataset includes 9M images annotated with 36M image-level labels, 15.8M bounding boxes, 2.8M instance segmentations, and 391k visual relationships. Along with the dataset itself, the associated Open Images Challenges have spurred the latest advances in object detection, instance segmentation, and visual relationship detection.
 |
| Annotation modalities in Open Images V5: image-level labels, bounding boxes, instance segmentations, and visual relationships. Image sources: 1969 Camaro RS/SS by D. Miller, the house by anita kluska, Cat Cafe Shinjuku calico by Ari Helminen, and Radiofiera - Villa Cordellina Lombardi, Montecchio Maggiore (VI) - agosto 2010 by Andrea Sartorati. All images used under CC BY 2.0 license. |
 |
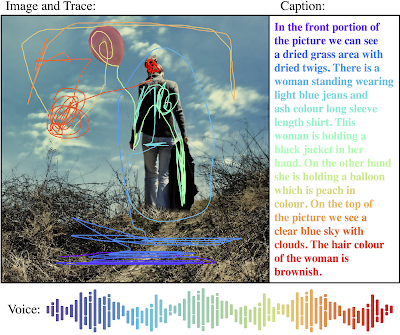
| Sample of localized narratives. Image source: Spring is here:-) by Kasia. |
One of the motivations behind localized narratives is to study and leverage the connection between vision and language, typically done via image captioning — images paired with human-authored textual descriptions of their content. One of the limitations of image captioning, however, is the lack of visual grounding, that is, localization on the image of the words in the textual description. To mitigate that, some previous works have a-posteriori drawn the bounding boxes for the nouns present in the description. In contrast, in localized narratives, every word in the textual description is grounded.
 |
| Different levels of grounding between image content and captioning. Left to Right: Caption to whole image (COCO); nouns to boxes (Flickr30k Entities); each word to a mouse trace segment (localized narratives). Image sources: COCO, Flickr30k Entities, and Sapa, Vietnam by Rama. |
 |
| Alignment of manual and automatic transcriptions. Icons based on an original design from Freepik. |
 |
| Mouse trace segments corresponding to the words below the images. Image sources: Via Guglielmo Marconi, Positano - Hotel Le Agavi - boat by Elliott Brown, air frame by vivek jena, and CL P1050512 by Virginia State Parks. |
New Visual Relationships, Human Actions, and Image-Level Annotations
In addition to the localized narratives, in Open Images V6 we increased the types of visual relationship annotations by an order of magnitude (up to 1.4k), adding for example “man riding a skateboard”, “man and woman holding hands”, and “dog catching a flying disk”.
 |
| Image sources: IMG_5678.jpg by James Buck, DSC_0494 by Quentin Meulepas, and DSC06464 by sally9258. |
 |
| Image sources: _DSCs1341 (2) by Boo Ph, and Richard Wagner Spiele 2015 by Johannes Gärtner. |
Conclusion
Open Images V6 is a significant qualitative and quantitative step towards improving the unified annotations for image classification, object detection, visual relationship detection, and instance segmentation, and takes a novel approach in connecting vision and language with localized narratives. We hope that Open Images V6 will further stimulate progress towards genuine scene understanding.
Quick links
Other posts of interest
-

March 16, 2026
Testing LLMs on superconductivity research questions- Education Innovation ·
- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

March 12, 2026
Protecting cities with AI-driven flash flood forecasting- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

March 12, 2026
Introducing Groundsource: Turning news reports into data with Gemini- Climate & Sustainability ·
- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets
×
❮
❯