On-Device Conversational Modeling with TensorFlow Lite
November 14, 2017
Posted by Sujith Ravi, Research Scientist, Google Expander Team
Quick links
Earlier this year, we launched Android Wear 2.0 which featured the first "on-device" machine learning technology for smart messaging. This enabled cloud-based technologies like Smart Reply, previously available in Gmail, Inbox and Allo, to be used directly within any application for the first time, including third-party messaging apps, without ever having to connect to the cloud. So you can respond to incoming chat messages on the go, directly from your smartwatch.
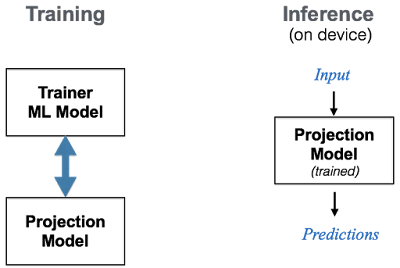
Today, we announce TensorFlow Lite, TensorFlow’s lightweight solution for mobile and embedded devices. This framework is optimized for low-latency inference of machine learning models, with a focus on small memory footprint and fast performance. As part of the library, we have also released an on-device conversational model and a demo app that provides an example of a natural language application powered by TensorFlow Lite, in order to make it easier for developers and researchers to build new machine intelligence features powered by on-device inference. This model generates reply suggestions to input conversational chat messages, with efficient inference that can be easily plugged in to your chat application to power on-device conversational intelligence.
The on-device conversational model we have released uses a new ML architecture for training compact neural networks (as well as other machine learning models) based on a joint optimization framework, originally presented in ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections. This architecture can run efficiently on mobile devices with limited computing power and memory, by using efficient “projection” operations that transform any input to a compact bit vector representation — similar inputs are projected to nearby vectors that are dense or sparse depending on type of projection. For example, the messages “hey, how's it going?” and “How's it going buddy?”, might be projected to the same vector representation.
Using this idea, the conversational model combines these efficient operations at low computation and memory footprint. We trained this on-device model end-to-end using an ML framework that jointly trains two types of models — a compact projection model (as described above) combined with a trainer model. The two models are trained in a joint fashion, where the projection model learns from the trainer model — the trainer is characteristic of an expert and modeled using larger and more complex ML architectures, whereas the projection model resembles a student that learns from the expert. During training, we can also stack other techniques such as quantization or distillation to achieve further compression or selectively optimize certain portions of the objective function. Once trained, the smaller projection model is able to be used directly for inference on device.

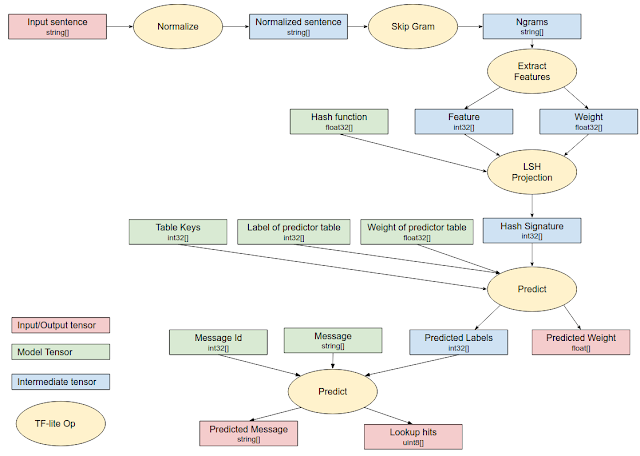
 |
| TensorFlow Lite execution for the On-Device Conversational Model. |
Beyond Conversational Models
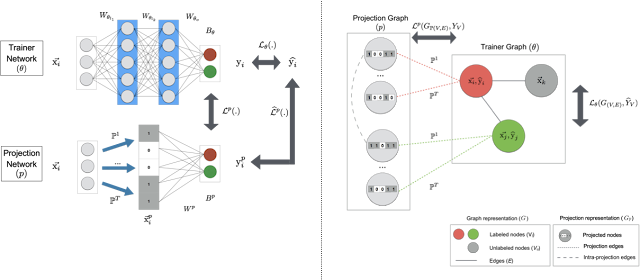
Interestingly, the ML architecture described above permits flexible choices for the underlying model. We also designed the architecture to be compatible with different machine learning approaches — for example, when used with TensorFlow deep learning, we learn a lightweight neural network (ProjectionNet) for the underlying model, whereas a different architecture (ProjectionGraph) represents the model using a graph framework instead of a neural network.
The joint framework can also be used to train lightweight on-device models for other tasks using different ML modeling architectures. As an example, we derived a ProjectionNet architecture that uses a complex feed-forward or recurrent architecture (like LSTM) for the trainer model coupled with a simple projection architecture comprised of dynamic projection operations and a few, narrow fully-connected layers. The whole architecture is trained end-to-end using backpropagation in TensorFlow and once trained, the compact ProjectionNet is directly used for inference. Using this method, we have successfully trained tiny ProjectionNet models that achieve significant reduction in model sizes (up to several orders of magnitude reduction) and high performance with respect to accuracy on multiple visual and language classification tasks (a few examples here). Similarly, we trained other lightweight models using our graph learning framework, even in semi-supervised settings.
 |
| ML architecture for training on-device models: ProjectionNet trained using deep learning (left), and ProjectionGraph trained using graph learning (right). |
Acknowledgments
Yicheng Fan and Gaurav Nemade contributed immensely to this effort. Special thanks to Rajat Monga, Andre Hentz, Andrew Selle, Sarah Sirajuddin, and Anitha Vijayakumar from the TensorFlow team; Robin Dua, Patrick McGregor, Andrei Broder, Andrew Tomkins and the Google Expander team.
1 The released on-device model was trained to optimize for small size and low latency applications on mobile phones and wearables. Smart Reply predictions in Google apps, however are generated using larger, more complex models. In production systems, we also use multiple classifiers that are trained to detect inappropriate content and apply further filtering and tuning to optimize user experience and quality levels. We recommend that developers using the open-source TensorFlow Lite version also follow such practices for their end applications.↩
Quick links
Other posts of interest
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
×
❮
❯