Off-Policy Classification - A New Reinforcement Learning Model Selection Method
June 19, 2019
Alex Irpan, Software Engineer, Robotics at Google
Quick links
Reinforcement learning (RL) is a framework that lets agents learn decision making from experience. One of the many variants of RL is off-policy RL, where an agent is trained using a combination of data collected by other agents (off-policy data) and data it collects itself to learn generalizable skills like robotic walking and grasping. In contrast, fully off-policy RL is a variant in which an agent learns entirely from older data, which is appealing because it enables model iteration without requiring a physical robot. With fully off-policy RL, one can train several models on the same fixed dataset collected by previous agents, then select the best one. However, fully off-policy RL comes with a catch: while training can occur without a real robot, evaluation of the models cannot. Furthermore, ground-truth evaluation with a physical robot is too inefficient to test promising approaches that require evaluating a large number of models, such as automated architecture search with AutoML.
This challenge motivates off-policy evaluation (OPE), techniques for studying the quality of new agents using data from other agents. With rankings from OPE, we can selectively test only the most promising models on real-world robots, significantly scaling experimentation with the same fixed real robot budget.
 |
| A diagram for real-world model development. Assuming we can evaluate 10 models per day, without off-policy evaluation, we would need 100x as many days to evaluate our models. |
Though the OPE framework shows promise, it assumes one has an off-policy evaluation method that accurately ranks performance from old data. However, agents that collected past experience may act very differently from newer learned agents, which makes it hard to get good estimates of performance.
In “Off-Policy Evaluation via Off-Policy Classification”, we propose a new off-policy evaluation method, called off-policy classification (OPC), that evaluates the performance of agents from past data by treating evaluation as a classification problem, in which actions are labeled as either potentially leading to success or guaranteed to result in failure. Our method works for image (camera) inputs, and doesn’t require reweighting data with importance sampling or using accurate models of the target environment, two approaches commonly used in prior work. We show that OPC scales to larger tasks, including a vision-based robotic grasping task in the real world.
How OPC Works
OPC relies on two assumptions: 1) that the final task has deterministic dynamics, i.e. no randomness is involved in how states change, and 2) that the agent either succeeds or fails at the end of each trial. This second “success or failure” assumption is natural for many tasks, such as picking up an object, solving a maze, winning a game, and so on. Because each trial will either succeed or fail in a deterministic way, we can assign binary classification labels to each action. We say an action is effective if it could lead to success, and is catastrophic if it is guaranteed to lead to failure.
OPC utilizes a Q-function, learned with a Q-learning algorithm, that estimates the future total reward if the agent chooses to take some action from its current state. The agent will then choose the action with the largest total reward estimate. In our paper, we prove that the performance of an agent is measured by how often its chosen action is an effective action, which depends on how well the Q-function correctly classifies actions as effective vs. catastrophic. This classification accuracy acts as an off-policy evaluation score.
However, the labeling of data from previous trials is only partial. For example, if a previous trial was a failure, we do not get negative labels because we do not know which action was the catastrophic one. To overcome this, we leverage techniques from semi-supervised learning, positive-unlabeled learning in particular, to get an estimate of classification accuracy from partially labeled data. This accuracy is the OPC score.
Off-Policy Evaluation for Sim-to-Real Learning
In robotics, it’s common to use simulated data and transfer learning techniques to reduce the sample complexity of learning robotics skills. This can be very useful, but tuning these sim-to-real techniques for real-world robotics is challenging. Much like off-policy RL, training doesn’t use the real robot, because it is trained in simulation, but evaluation of that policy still needs to use a real robot. Here, off-policy evaluation can come to the rescue again—we can take a policy trained only in simulation, then evaluate it using previous real-world data to measure its transfer to the real robot. We examine OPC across both fully off-policy RL and sim-to-real RL.
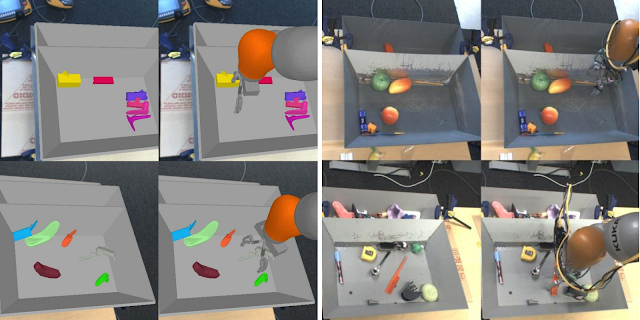
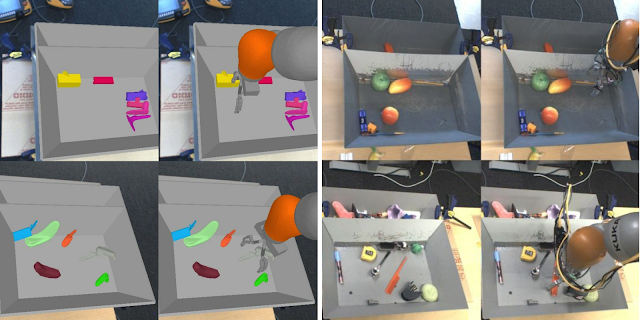 |
| An example of how simulated experience can differ from real-world experience. Here, simulated images (left) have much less visual complexity than real-world images (right). |
Results
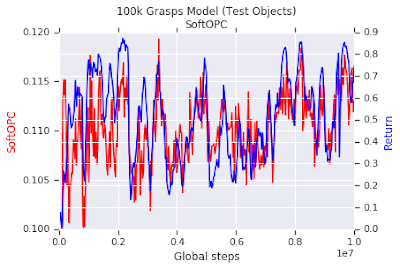
First, we set up a simulated version of our robot grasping task, where we could easily train and evaluate several models to benchmark off-policy evaluation. These models were trained with fully off-policy RL, then evaluated with off-policy evaluation. We found that in our robotics tasks, a variant of the OPC called the SoftOPC performed best at predicting final success rate.
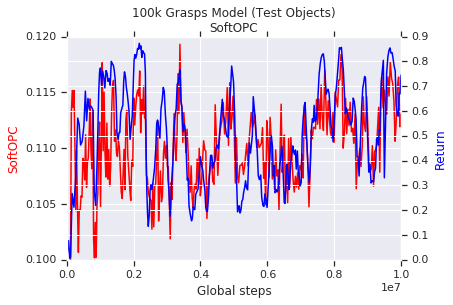 |
| An experiment in the simulated grasping task. The red curve is the dimensionless SoftOPC score over the course of training, evaluated from old data. The blue curve is the grasp success rate in simulation. We see the SoftOPC on old data correlates well with grasp success of the model within our simulator. |
After success in sim, we then tried SoftOPC in the real-world task. We took 15 models, trained to have varying degrees of robustness to the gap between simulation and reality. Of these models, 7 of them were trained purely in simulation, and the rest were trained on mixes of simulated and real-world data. For each model, we evaluated the SoftOPC on off-policy real-world data, then the real-world grasp success, to see how well SoftOPC predicted performance of that model. We found that on real data, the SoftOPC does produce scores that correlate with true grasp success, letting us rank sim-to-real techniques using past real experience.
 |
| SoftOPC score and true performance for 3 different sim-to-real methods: a baseline simulation, a simulation with random textures and lighting, and a model trained with RCAN. All three models are trained with no real data, then evaluated with off-policy evaluation on a validation set of real data. The ordering of the SoftOPC score matches the order of real grasp success. |
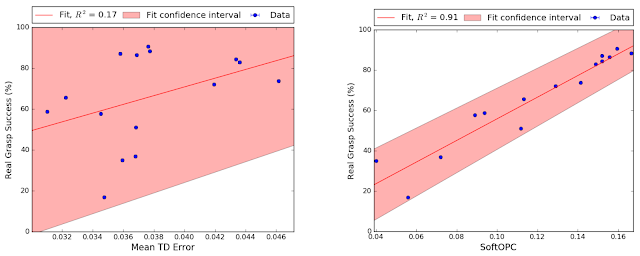
Below is a scatterplot of the full results from all 15 models. Each point represents the off-policy evaluation score and real-world grasp success of each model. We compare different scoring functions by their correlation to final grasp success. The SoftOPC does not correlate perfectly with true grasp success, but its scores are significantly more reliable than baseline approaches like the temporal-difference error (the standard Q-learning loss).
 |
| Results from our sim-to-real evaluation experiment. On the left is a baseline, the temporal difference error of the model. On the right is one of our proposed methods, the SoftOPC. The shaded region is a 95% confidence interval. The correlation is significantly better with SoftOPC. |
Future Work
One promising direction for future work is to see if we can relax our assumptions about the task, to support tasks where dynamics are more noisy, or where we get partial credit for almost succeeding. However, even with our included assumptions, we think the results are promising enough to be applied to many real-world RL problems.
Acknowledgements
This research was conducted by Alex Irpan, Kanishka Rao, Konstantinos Bousmalis, Chris Harris, Julian Ibarz and Sergey Levine. We’d like to thank Razvan Pascanu, Dale Schuurmans, George Tucker and Paul Wohlhart for valuable discussions. A preprint is available on arXiv.
Quick links