Neptune: The long orbit to benchmarking long video understanding
September 16, 2024
Arsha Nagrani and Tobias Weyand, Research Scientists, Google Research
We describe Neptune, a new open-source video question-answering dataset to test long-video-understanding.
The amount of video content online is growing at a rapid pace and driving the need for new research into video and language tasks, such as video question answering (VideoQA) and video summarization. Early video and language models, while adept at VideoQA, have largely focused on short, trimmed clips (less than 1 minute long) and are unable to accommodate long format videos, which are very common. The recent release of powerful longer context multimodal models (for example the Gemini-1.5 model family) has ushered in the promise of models being able to reason over millions of tokens, which expands the possibilities for VideoQA applications to videos up to several minutes long.
Datasets for evaluation play a critical role in the development of VideoQA, as they allow for a final, unbiased performance measure of the entire model building process. Yet popular test sets (such as MVBench, MSRVTT-QA and Next-QA) focus on short, trimmed clips only up to 30 seconds long. A key challenge in designing models to reason over long videos, then, is the lack of proper long video evaluation datasets.
With this in mind, we are releasing a new evaluation dataset, called Neptune, that includes tough multiple-choice and open-ended questions for videos of variable lengths up to 15 minutes long. Described in our paper “Neptune: The Long Orbit to Benchmarking Long Video Understanding”, Neptune’s questions are designed to require reasoning over multiple modalities (visual and spoken content) and long time horizons, challenging the abilities of current large multimodal models.
Pipeline
Long video datasets are challenging to build because of the significant manual effort required to select, watch, understand and annotate long videos with free-form natural language. Answering challenging questions about longer videos is often a multimodal task that may involve listening to the audio track in addition to watching the video. It may also be a non-linear task, because sometimes it may be necessary to rewind and rewatch key parts to answer a question. Proposing suitable high-level questions that are not trivially solved by observing only a few frames can also be tricky for people to do consistently and with adequate variety.
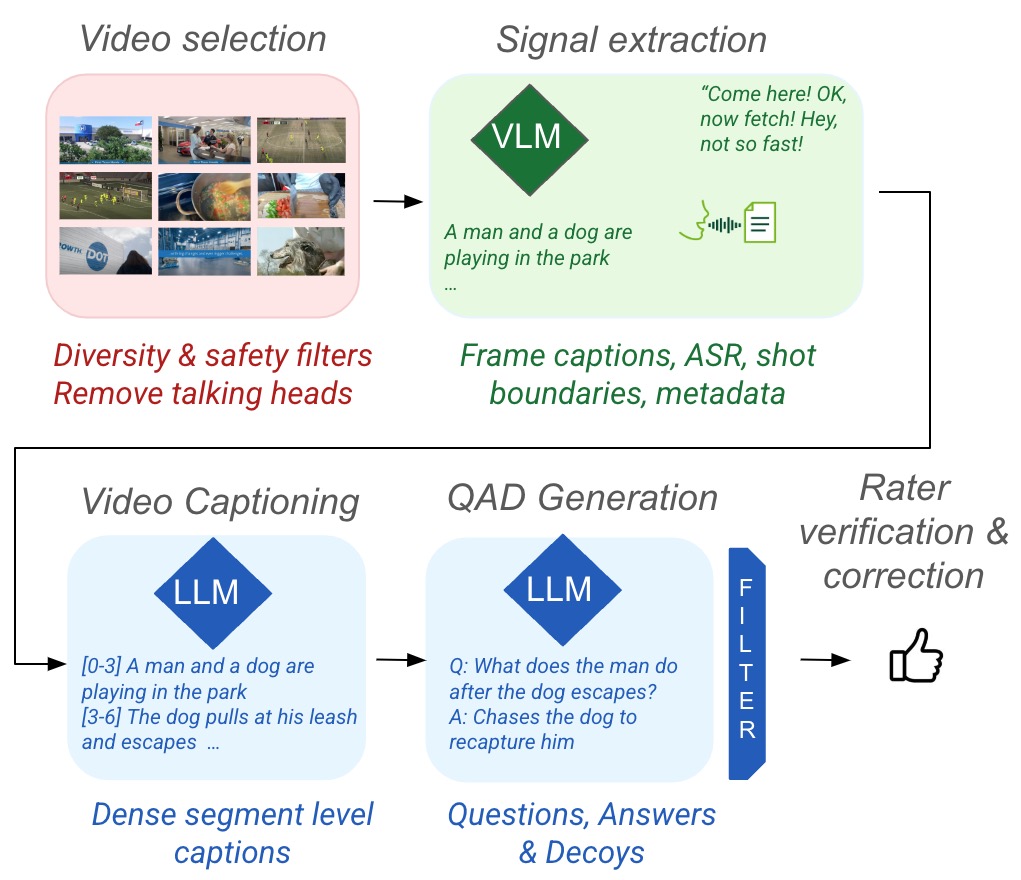
In order to solve this problem we propose a semi-automatic pipeline that first generates candidate multiple choice questions using a number of strong vision-language models (VLMs) and large language models (LLMs) with carefully designed prompts, and then lets human annotators filter and correct the proposed questions to reduce errors and bias. In order to reduce human effort, we leverage automatic tools to (1) find suitable videos, (2) extract useful signals, and then (3) automatically generate video-level captions, questions and answers.
Our pipeline begins with the selection of video content. We filter videos to increase visual and demographic diversity. We also remove videos with mostly static content as well as gaming videos and animated content. In the next stage, we extract two types of captions from the resulting videos: automatic speech recognition (ASR) captions and frame captions. For the latter, we prompt a VLM to describe video frames sampled at one frame per second. The next step summarizes these captions by segmenting the video into shots, grouping them by topics and prompting an LLM to summarize ASR and frame-level captions into shot-level captions.
Given these captions, the pipeline generates multiple-choice questions in two stages. In the first stage, we prompt an LLM to generate a set of challenging questions and answers, providing it with the video captions as context. In the second stage, we prompt the LLM with a generated question-answer pair and the video captions and ask it to generate four decoy answers. Decoys need to be incorrect but plausible answers to the question. The final stage of the pipeline is human verification, where we ask human raters to filter or correct incorrect questions, answers and decoys.
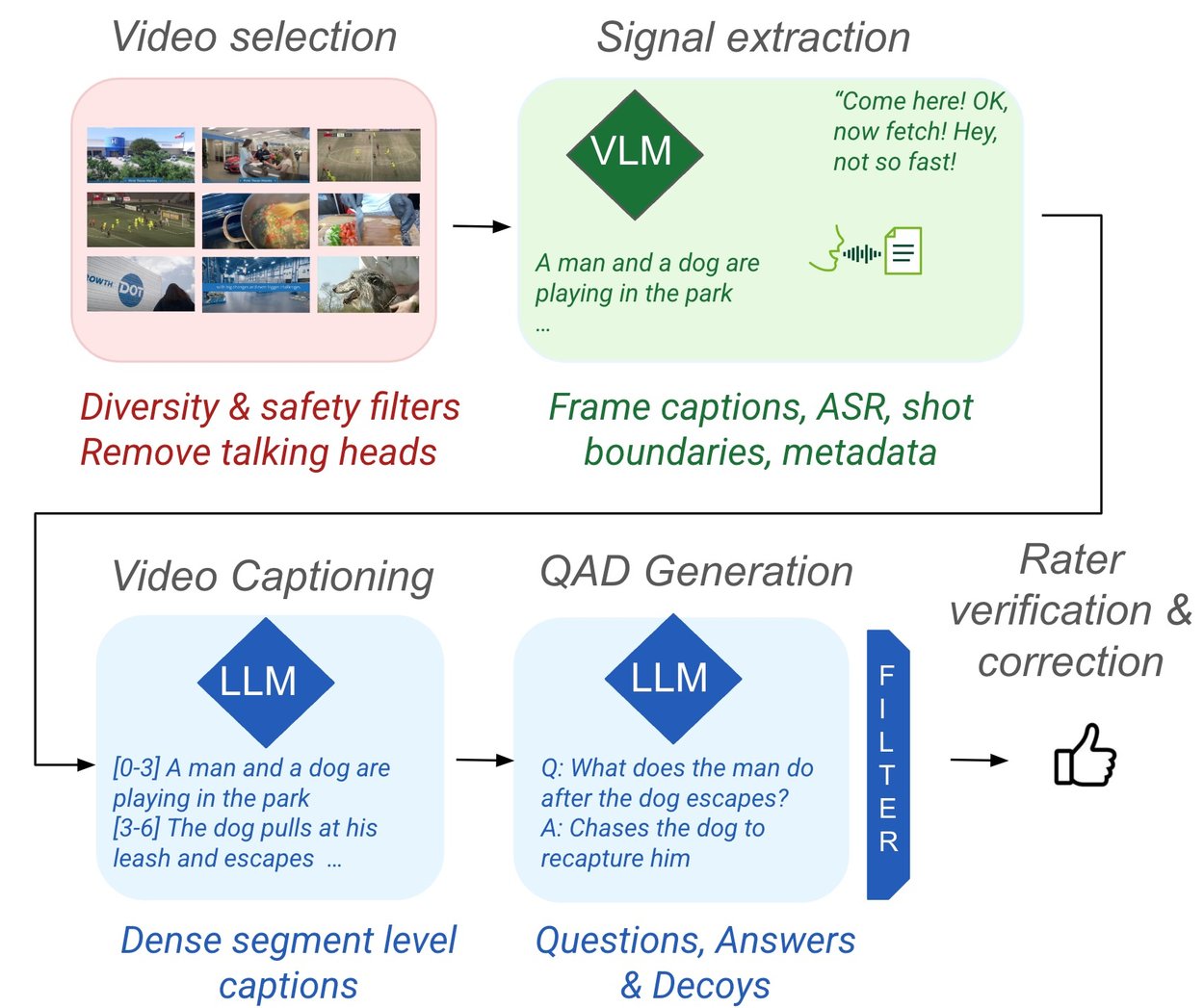
The Neptune data pipeline.
Question types
The resulting dataset, Neptune, covers a broad range of long video reasoning abilities. The questions include type labels, such as "video summarization", "temporal ordering", "state changes", and "creator intent", amongst others (examples shown below). In addition, to test the broad applicability of large multimodal models, Neptune contains videos from a variety of domains including how-to videos, video blogs (VLOGs), sports, cooking, etc.

Examples of different question types in Neptune.
Evaluation
Neptune allows for two modes of evaluation: multiple-choice and open-ended question answering. Traditional metrics for question answering are often rule-based and derived from captioning (e.g., WUPS or CIDEr). We found these to perform poorly, especially for longer answers. More recently, LLMs are being used to judge the correctness of open-ended answers. This approach is much more robust than using traditional metrics, but relies on proprietary APIs (e.g., ChatGPT) that can change over time, which hinders reproducibility. To provide a metric that is both robust and stable, we fine-tune an open source model (Gemma) to score question answering results on the manually annotated BEM answer equivalence dataset. Our new metric is called the Gemma Equivalence Metric (GEM).
Baselines
We benchmark a number of both open-source and proprietary video-language models on Neptune. The open-source models include both short-context models (Video-LLaVA, VideoLLaMA2) and long-context models (MovieChat, MA-LMM, and Mini-GPT4-video). Surprisingly, we find that the open source video models designed for long-context understanding fail to leverage multiple frames on Neptune. In fact, short-context models — such as Video-LLaVA, which uses only 8 frames — typically outperform them. Secondly, we find that all open-source models perform much worse than Gemini-1.5-Pro, which sets the state-of-the-art on the dataset.
Analyzing the performance across the different question types shows interesting results. We find that “Counting”, “Temporal Ordering” and “State Change” questions are challenging for all models, pointing to areas for future work for video-language models, while “Cause and Effect” is easier. Interestingly, the Gemini-1.5-Pro model applied only to ASR without access to video frames is the best at “Goal Reasoning”, which may be because human goals in videos are often mentioned in speech. Yet as expected, it is worse at the “Visual Narrative” questions, where Gemini-1.5-Pro models with access to RGB frames do much better.
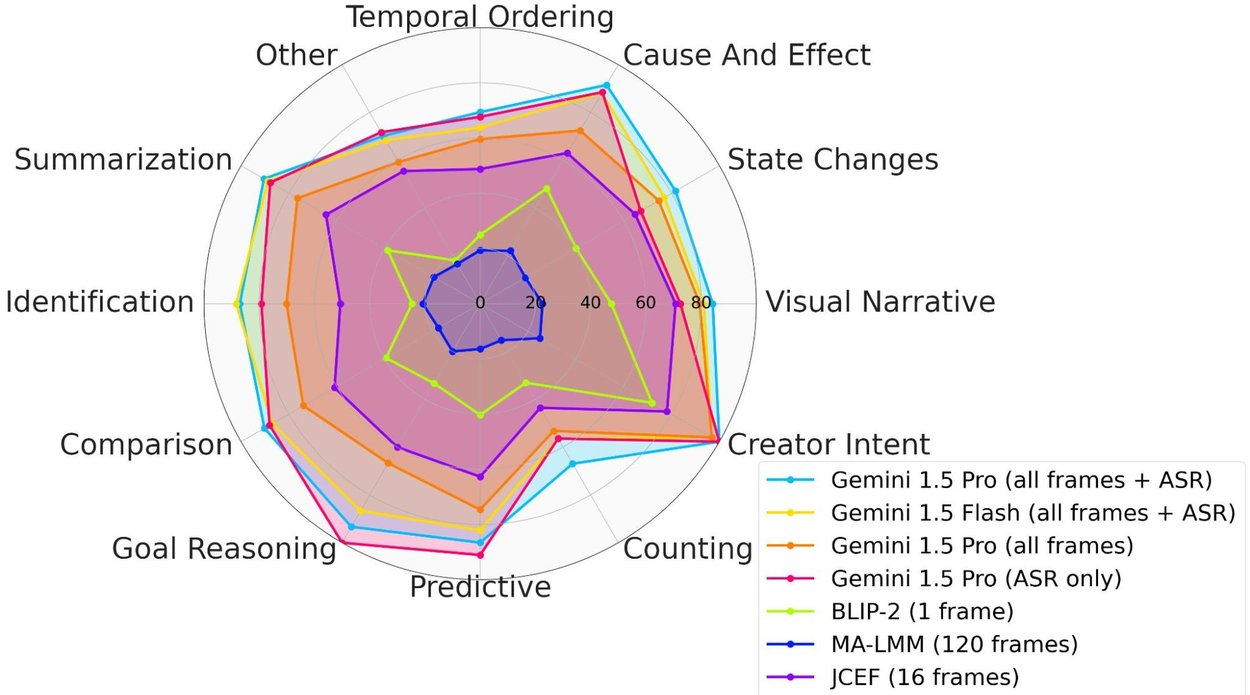
Performance of different models across different Neptune question types.
Learning more about Neptune
The Neptune dataset is publicly available and further details are in the paper. We hope that Neptune will inspire and guide further research towards long video understanding. In the future, we hope to collaborate with the video research community to introduce additional annotations, tasks, metrics, or even new languages to the benchmark.
Acknowledgements
This work was done by the entire Neptune team, consisting of Arsha Nagrani, Mingda Zhang, Ramin Mehran, Rachel Hornung, Nitesh Bharadwaj Gundavarapu, Nilpa Jha, Austin Myers, Xingyi Zhou, Boqing Gong, Cordelia Schmid, Mikhail Sirotenko, Yukun Zhu, and Tobias Weyand. We are also grateful to Antoine Yang, Anelia Angelova, Mario Lucic and Karel Lenc from the Gemini team for their support, as well as Anja Hauth for help with hosting the data. We thank Jannis Bulian and Christian Buck for their help with the BEM dataset. We’d also like to thank Brandon Black, Amanda Sadler, Michael Smouha, Rachel Stigler. All team members are now in Google DeepMind.
Other posts of interest
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

March 24, 2026
Mapping the modern world: How S2Vec learns the language of our cities- Algorithms & Theory ·
- Earth AI ·
- Machine Intelligence
-

March 17, 2026
Google Research at The Check Up: from healthcare innovation to real-world care settings- Health & Bioscience ·
- Machine Intelligence


