MultiModel: Multi-Task Machine Learning Across Domains
June 21, 2017
Posted by Łukasz Kaiser, Senior Research Scientist, Google Brain Team and Aidan N. Gomez, Researcher, Department of Computer Science Machine Learning Group, University of Toronto
Quick links
Over the last decade, the application and performance of Deep Learning has progressed at an astonishing rate. However, the current state of the field is that the neural network architectures are highly specialized to specific domains of application. An important question remains unanswered: Will a convergence between these domains facilitate a unified model capable of performing well across multiple domains?
Today, we present MultiModel, a neural network architecture that draws from the success of vision, language and audio networks to simultaneously solve a number of problems spanning multiple domains, including image recognition, translation and speech recognition. While strides have been made in this direction before, namely in Google’s Multilingual Neural Machine Translation System used in Google Translate, MultiModel is a first step towards the convergence of vision, audio and language understanding into a single network.
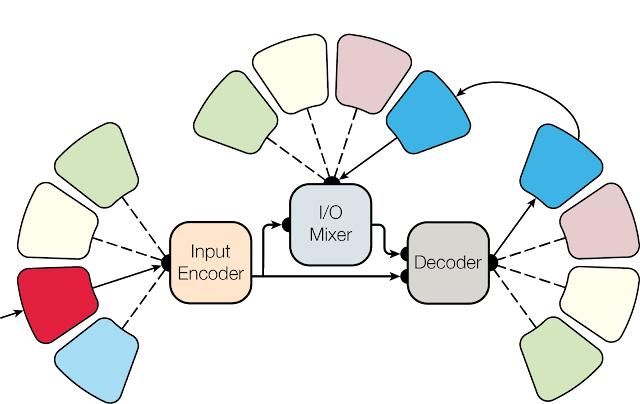
The inspiration for how MultiModel handles multiple domains comes from how the brain transforms sensory input from different modalities (such as sound, vision or taste), into a single shared representation and back out in the form of language or actions. As an analog to these modalities and the transformations they perform, MultiModel has a number of small modality-specific sub-networks for audio, images, or text, and a shared model consisting of an encoder, input/output mixer and decoder, as illustrated below.
 |
| MultiModel architecture: small modality-specific sub-networks work with a shared encoder, I/O mixer and decoder. Each petal represents a modality, transforming to and from the internal representation. |

It is important to note that while MultiModel does not establish new performance records, it does provide insight into the dynamics of multi-domain multi-task learning in neural networks, and the potential for improved learning on data-limited tasks by the introduction of auxiliary tasks. There is a longstanding saying in machine learning: “the best regularizer is more data”; in MultiModel, this data can be sourced across domains, and consequently can be obtained more easily than previously thought. MultiModel provides evidence that training in concert with other tasks can lead to good results and improve performance on data-limited tasks.
Many questions about multi-domain machine learning remain to be studied, and we will continue to work on tuning Multimodel and improving its performance. To allow this research to progress quickly, we open-sourced MultiModel as part of the Tensor2Tensor library. We believe that such synergetic models trained on data from multiple domains will be the next step in deep learning and will ultimately solve tasks beyond the reach of current narrowly trained networks.
Acknowledgements
This work is a collaboration between Googlers Łukasz Kaiser, Noam Shazeer, Ashish Vaswani, Niki Parmar, Llion Jones and Jakob Uszkoreit, and Aidan N. Gomez from the University of Toronto. It was performed while Aidan was working with the Google Brain team.
1 The 8 tasks were: (1) speech recognition (WSJ corpus), (2) image classification (ImageNet), (3) image captioning (MS COCO), (4) parsing (Penn Treebank), (5) English-German translation, (6) German-English translation, (7) English-French translation, (8) French-English translation (all using WMT data-sets).↩
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯

