
More Efficient NLP Model Pre-training with ELECTRA
March 10, 2020
Posted by Kevin Clark, Student Researcher and Thang Luong, Senior Research Scientist, Google Research, Brain Team
Quick links
Recent advances in language pre-training have led to substantial gains in the field of natural language processing, with state-of-the-art models such as BERT, RoBERTa, XLNet, ALBERT, and T5, among many others. These methods, though they differ in design, share the same idea of leveraging a large amount of unlabeled text to build a general model of language understanding before being fine-tuned on specific NLP tasks such as sentiment analysis and question answering.
Existing pre-training methods generally fall under two categories: language models (LMs), such as GPT, which process the input text left-to-right, predicting the next word given the previous context, and masked language models (MLMs), such as BERT, RoBERTa, and ALBERT, which instead predict the identities of a small number of words that have been masked out of the input. MLMs have the advantage of being bidirectional instead of unidirectional in that they “see” the text to both the left and right of the token being predicted, instead of only to one side. However, the MLM objective (and related objectives such as XLNet’s) also have a disadvantage. Instead of predicting every single input token, those models only predict a small subset — the 15% that was masked out, reducing the amount learned from each sentence.
 |
| Existing pre-training methods and their disadvantages. Arrows indicate which tokens are used to produce a given output representation (rectangle). Left: Traditional language models (e.g., GPT) only use context to the left of the current word. Right: Masked language models (e.g., BERT) use context from both the left and right, but predict only a small subset of words for each input. |
Making Pre-training Faster
ELECTRA uses a new pre-training task, called replaced token detection (RTD), that trains a bidirectional model (like a MLM) while learning from all input positions (like a LM). Inspired by generative adversarial networks (GANs), ELECTRA trains the model to distinguish between “real” and “fake” input data. Instead of corrupting the input by replacing tokens with “[MASK]” as in BERT, our approach corrupts the input by replacing some input tokens with incorrect, but somewhat plausible, fakes. For example, in the below figure, the word “cooked” could be replaced with “ate”. While this makes a bit of sense, it doesn’t fit as well with the entire context. The pre-training task requires the model (i.e., the discriminator) to then determine which tokens from the original input have been replaced or kept the same. Crucially, this binary classification task is applied to every input token, instead of only a small number of masked tokens (15% in the case of BERT-style models), making RTD more efficient than MLM — ELECTRA needs to see fewer examples to achieve the same performance because it receives mode training signal per example. At the same time, RTD results in powerful representation learning, because the model must learn an accurate representation of the data distribution in order to solve the task.
 |
| Replaced token detection trains a bidirectional model while learning from all input positions. |
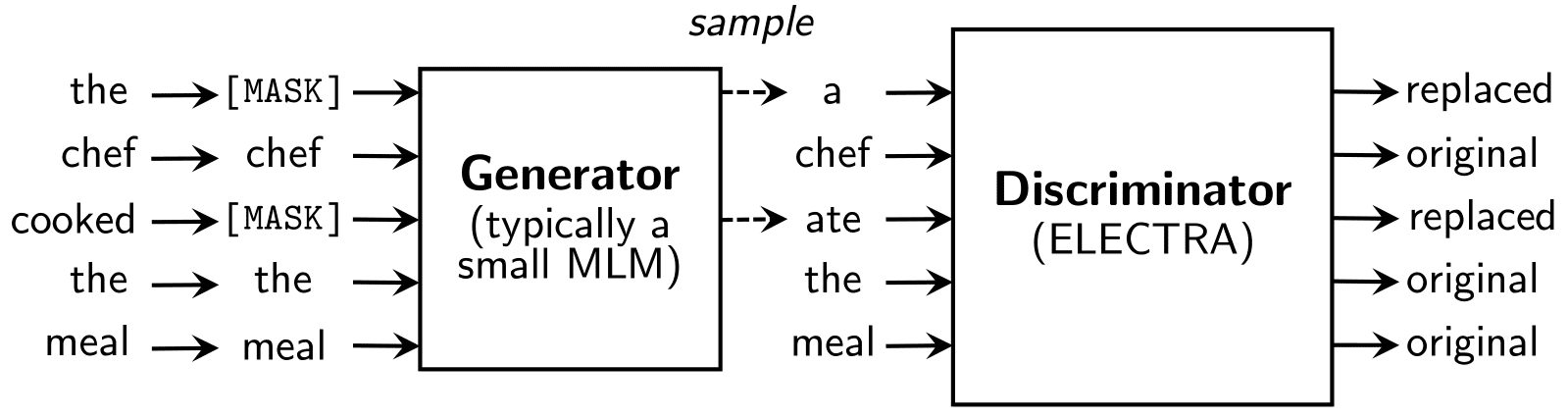 |
| Further details on the replaced token detection (RTD) task. The fake tokens are sampled from a small masked language model that is trained jointly with ELECTRA. |
We compare ELECTRA against other state-of-the-art NLP models and found that it substantially improves over previous methods, given the same compute budget, performing comparably to RoBERTa and XLNet while using less than 25% of the compute.
 |
| The x-axis shows the amount of compute used to train the model (measured in FLOPs) and the y-axis shows the dev GLUE score. ELECTRA learns much more efficiently than existing pre-trained NLP models. Note that current best models on GLUE such as T5 (11B) do not fit on this plot because they use much more compute than others (around 10x more than RoBERTa). |
Lastly, to see if the strong results held at scale, we trained a large ELECTRA model using more compute (roughly the same amount as RoBERTa, about 10% the compute as T5). This model achieves a new state-of-the-art for a single model on the SQuAD 2.0 question answering dataset (see the below table) and outperforms RoBERTa, XLNet, and ALBERT on the GLUE leaderboard. While the large-scale T5-11b model scores higher still on GLUE, ELECTRA is 1/30th the size and uses 10% of the compute to train.
| Model | Squad 2.0 test set |
| ELECTRA-Large | 88.7 |
| ALBERT-xxlarge | 88.1 |
| XLNet-Large | 87.9 |
| RoBERTa-Large | 86.8 |
| BERT-Large | 80.0 |
| SQuAD 2.0 scores for ELECTRA-Large and other state-of-the-art models (only non-ensemble models shown). |
We are releasing the code for both pre-training ELECTRA and fine-tuning it on downstream tasks, with currently supported tasks including text classification, question answering and sequence tagging. The code supports quickly training a small ELECTRA model on one GPU. We are also releasing pre-trained weights for ELECTRA-Large, ELECTRA-Base, and ELECTRA-Small. The ELECTRA models are currently English-only, but we hope to release models which have been pre-trained on many languages in the future.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
×
❮
❯



